Масштабируемость системы
Масштабируемость — такое свойство вычислительной системы, которое обеспечивает предсказуемый рост системных характеристик, например, числа поддерживаемых пользователей, быстроты реакции, общей производительности и пр., при добавлении к ней вычислительных ресурсов. В случае сервера СУБД можно рассматривать два способа масштабирования — вертикальный и горизонтальный (рис. 2).
При горизонтальном масштабировании увеличивается число серверов СУБД, возможно, взаимодействующих друг с другом в прозрачном режиме, разделяя таким образом общую загрузку системы. Такое решение, видимо, будет все более популярным с ростом поддержки слабосвязанных архитектур и распределенных баз данных, однако обычно оно характеризуется сложным администрированием.
Вертикальное масштабирование подразумевает увеличение мощности отдельного сервера СУБД и достигается заменой аппаратного обеспечения (процессора, дисков) на более быстродействующее или добавлением дополнительных узлов.
Свойство масштабируемости актуально по двум основным причинам. Прежде всего, условия современного бизнеса меняются столь быстро, что делают невозможным долгосрочное планирование, требующее всестороннего и продолжительного анализа уже устаревших данных, даже для тех организаций, которые способны это себе позволить. Взамен приходит стратегия постепенного, шаг за шагом, наращивания мощности информационных систем.
- поддержка многопроцессорной обработки;
- гибкость архитектуры.
Многопроцессорные системы
Для вертикального масштабирования все чаще используются симметричные многопроцессорные системы (SMP), поскольку в этом случае не требуется смены платформы, т.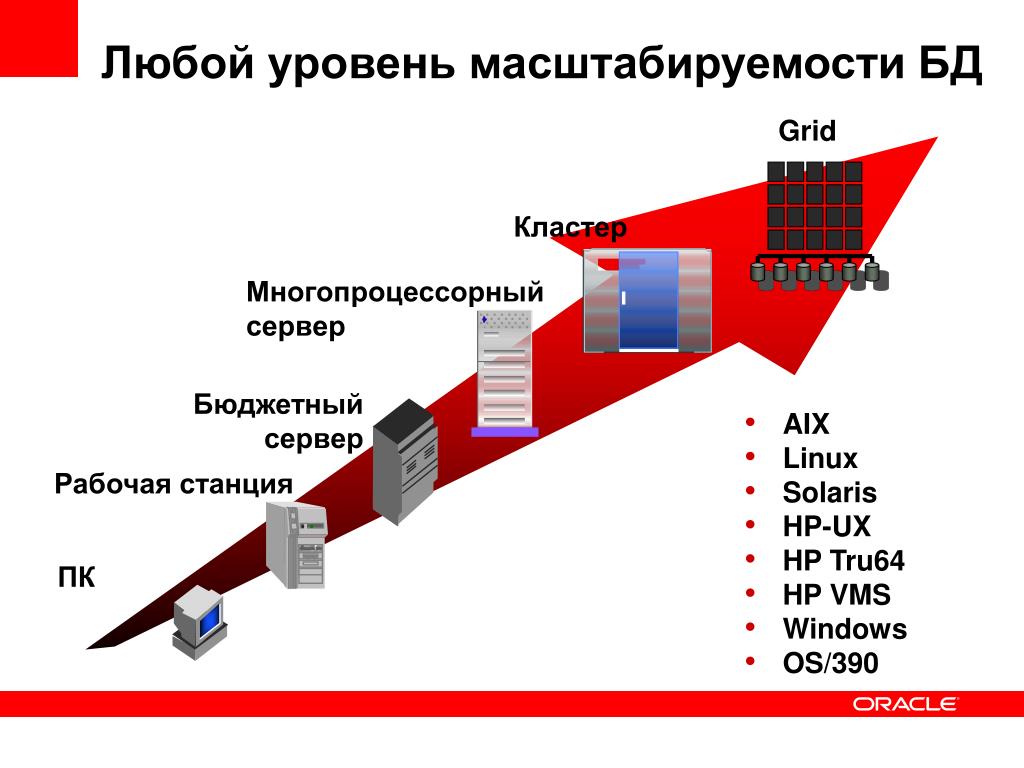
Свойство адекватности требует, чтобы архитектура сервера равно поддерживала один или десять процессоров без переустановки или существенных изменений в конфигурации, а также дополнительных программных модулей. Такая архитектура будет одинаково полезна и эффективна и в однопроцессорной системе, и, по мере роста сложности решаемых задач, на нескольких или даже на множестве (MPP) процессоров. В общем случае потребитель не должен дополнительно покупать и осваивать новые опции программного обеспечения.
Обеспечение прозрачности архитектуры сервера, в свою очередь, позволяет скрыть изменения конфигурации аппаратного обеспечения от приложений, т. е. гарантирует переносимость прикладных программных систем. В частности, в сильно связанных многопроцессорных архитектурах приложение может взаимодействовать с сервером через сегмент разделяемой памяти, тогда как при использовании слабосвязанных многосерверных систем (кластеров) для этой цели может быть применен механизм сообщений. Приложение не должно учитывать возможности реализации аппаратной архитектуры — способы манипулирования данными и программный интерфейс доступа к базе данных обязаны оставаться одинаковыми и в равной степени эффективными.
е. гарантирует переносимость прикладных программных систем. В частности, в сильно связанных многопроцессорных архитектурах приложение может взаимодействовать с сервером через сегмент разделяемой памяти, тогда как при использовании слабосвязанных многосерверных систем (кластеров) для этой цели может быть применен механизм сообщений. Приложение не должно учитывать возможности реализации аппаратной архитектуры — способы манипулирования данными и программный интерфейс доступа к базе данных обязаны оставаться одинаковыми и в равной степени эффективными.
Качественная поддержка многопроцессорной обработки требует от сервера баз данных способности самостоятельно планировать выполнение множества обслуживаемых запросов, что обеспечило бы наиболее полное разделение доступных вычислительных ресурсов между задачами сервера. Запросы могут обрабатываться последовательно несколькими задачами или разделяться на подзадачи, которые, в свою очередь, могут быть выполнены параллельно (рис. 3). Последнее более оптимально, поскольку правильная реализация этого механизма обеспечивает выгоды, независимые от типов запросов и приложений.
Гибкость архитектуры
Независимо от степени мобильности, поддержки стандартов, параллелизма и других полезных качеств, производительность СУБД, имеющей ощутимые встроенные архитектурные ограничения, не может наращиваться свободно.
Обычно узким местом является невозможность динамической подстройки характеристик программ сервера баз данных. Способность на ходу определять такие параметры, как объем потребляемой памяти, число занятых процессоров, количество параллельных потоков выполнения заданий (будь то настоящие потоки (threads), процессы операционной системы или виртуальные процессоры) и количество фрагментов таблиц и индексов баз данных, а также их распределение по физическим дискам БЕЗ останова и перезапуска системы является требованием, вытекающим из сути современных приложений.
Масштабируемость: что это такое?
Как-то передо мной встал вопрос, что такое масштабируемость и как это связано с зависимостью/независимостью от центрального процессора? В результате получилась небольшая статья, которую и предлагаю Вашему вниманию.
Начну с того, что постараюсь кратко объяснить, что же такое процессорная зависимость (CPU dependency) применительно к 3D-ускорителям. Дело в том, что ни один из существующих 3D-ускорителей пользовательского класса не ускоряет весь процесс обсчета трехмерной сцены (геометрические преобразования, просчет освещенности, отсечение невидимых поверхностей и т.д.). Разные ускорители ускоряют разные этапы, обычно лежащие где-то ближе к концу цепочки вычислений — растеризацию (т.е. перевод двумерного векторного изображения в двумерное растровое изображение) и наложение текстур. Вся остальная работа ложится на плечи центрального процессора (CPU). При этом для организации взаимодействия с 3D-ускорителем обычно требуется некоторое дополнительное число шагов. Процессорная зависимость, таким образом, слагается из 2-х компонент — процента вычислений, НЕ ускоряемых картой, и процента дополнительных вычислений, которые производятся уже графическим процессором.
При этом для организации взаимодействия с 3D-ускорителем обычно требуется некоторое дополнительное число шагов. Процессорная зависимость, таким образом, слагается из 2-х компонент — процента вычислений, НЕ ускоряемых картой, и процента дополнительных вычислений, которые производятся уже графическим процессором.
Как процессорная зависимость связана с масштабируемостью, т.е. возможностью роста производительности карточки с ростом производительности процессора? В большинстве случаев имеется некоторый отрезок процессорной мощности, при котором карточка демонстрирует почти линейный рост производительности. Связано это с тем, что процессор не успевает готовить данные для графического ускорителя, и любые данные обрабатываются до поступления следующей порции. При этом, очевидно, что чем больший участок тракта вычислений берет на себя графический акселератор, тем меньше нагрузка на процессор, а значит, CPU быстрее готовит данные, и, в результате, сужается участок линейного масштабирования. Отсюда следует, что чем менее процессорно-зависима карточка-ускоритель, тем она обычно менее масштабируема.
Отсюда следует, что чем менее процессорно-зависима карточка-ускоритель, тем она обычно менее масштабируема.
Начиная с какого-то момента, графический акселератор начинает все больше и больше тормозить процессор, и при неограниченном росте производительности последнего скорость рендеринга становится постоянной, стремясь к пиковой производительности ускорителя.
Конечно, эта модель несколько упрощенная. В реальных системах процессору всегда найдется, чем заняться, к тому же пропускные способности шин, передающих данные, на сегодня весьма ограничены. Что, кстати, является еще одним узким местом на пути достижения максимальной производительности.
В качестве оценки предельной производительности карточки можно использовать известные характеристики количества треугольников, которые она может обработать в секунду, и скорость закраски (fill-rate), т.е. количество текстурированных и отфильтрованных пикселов, выводимых в одну секунду. Возьмем для примера две карточки: 3Dfx Voodoo и nVidia Riva TNT.
Их параметры таковы:
- 3dfx Voodoo: 750 тыс. треуг./сек, 40 млн.пикселей/сек
- nVidia Riva TNT: 2 млн. треуг./сек, 200 млн.пикселей/сек
Что можно сказать на основе этих данных? Для 3dfx Voodoo получается следующее ограничение:
- при сложности сцены в 10 тыс. треуг. — 75 fps.
- при разрешении 640х480 и глубине перекрытия 4 — 32 fps.
Как видим, теоретические данные очень неплохо согласуются с практическими (эти параметры приблизительно соответствуют Quake 2).
Что же с Ривой? Получаются следующие значения:
- при сложности сцены в 10 тыс. треуг — 200 fps.
- при разрешении 640х480 и глубине перекрытия 4 — 162 fps.
- при разрешении 800х600 и глубине перекрытия 4 — 104 fps.
- при разрешении 1024х768 и глубине перекрытия 4 — 63 fps.
Что следует из этих цифр? Очень простой вывод. Начиная с какого-то уровня, производительность 3D-ускорителя уже не играет роли (глазу все равно, 160 или 60 fps он видит). Все теперь упирается в процессорную зависимость, т.е. в то, какой процессор нужен, чтобы достичь подобных пиковых значений. Вот почему я с большим скепсисом читаю характеристики вновь появляющихся 3D-ускорителей. Также легко видеть, что приведенные ускорители (как и подавляющее большинство остальных) ограничены именно скоростью закраски, тогда как для процессора основная нагрузка исходит от процесса геометрических преобразований, т.е., усилия разработчиков сосредоточены несколько не в том месте, где надо бы.
Все теперь упирается в процессорную зависимость, т.е. в то, какой процессор нужен, чтобы достичь подобных пиковых значений. Вот почему я с большим скепсисом читаю характеристики вновь появляющихся 3D-ускорителей. Также легко видеть, что приведенные ускорители (как и подавляющее большинство остальных) ограничены именно скоростью закраски, тогда как для процессора основная нагрузка исходит от процесса геометрических преобразований, т.е., усилия разработчиков сосредоточены несколько не в том месте, где надо бы.
Масштабируемость
Масштабируемость — это способность системы адаптироваться к расширению предъявляемых требований и возрастанию объемов решаемых задач.
Работа одного прикладного решения в разных условиях
Система «1С:Предприятие 8» имеет хорошие возможности масштабирования. Она позволяет работать как в файловом варианте, так и с использованием технологии «клиент-сервер».
Персональное использование, файловый вариант работы
При работе в файловом варианте платформа может работать с локальной информационной базой, расположенной на том же компьютере, на котором работает пользователь. Такой вариант работы может использоваться в домашних условиях или при работе на ноутбуке.
Файловый вариант также обеспечивает возможность работы по локальной сети нескольких пользователей с одной информационной базой. Такой способ работы может использоваться в небольших рабочих группах, он прост в установке и эксплуатации.
Для больших рабочих групп и в масштабах предприятия может применяться клиент-серверный вариант работы, основанный на трехуровневой архитектуре с использованием кластера серверов «1С:Предприятия 8» и отдельной системы управления базами данных. Он обеспечивает надежное хранение данных и их эффективную обработку при одновременной работе большого количества пользователей.
Крупные холдинговые компании могут использовать работу в распределенной информационной базе, сочетающуюся с применением как файлового, так и клиент-серверного вариантов работы. Распределенная информационная база позволяет объединить удаленные друг от друга подразделения холдинга, а каждое из этих подразделений может использовать, в свою очередь, файловый или клиент-серверный варианты работы. Механизм распределенной информационной базы будет обеспечивать идентичность конфигураций, используемых в каждом из подразделений холдинга, и осуществлять обмен данными между отдельными информационными базами, входящими с состав распределенной системы.
Важно отметить, что одни и те же прикладные решения (конфигурации) могут использоваться как в файловом, так и в клиент-серверном варианте работы. При переходе от файлового варианта к технологии «клиент-сервер» не требуется вносить изменения в прикладное решение. Поэтому выбор варианта работы целиком зависит от потребностей заказчика и его финансовых возможностей. На начальной стадии можно работать в файловом варианте, а затем с увеличением количества пользователей и объема базы данных можно легко перейти на клиент-серверный вариант работы со своей информационной базы.
На начальной стадии можно работать в файловом варианте, а затем с увеличением количества пользователей и объема базы данных можно легко перейти на клиент-серверный вариант работы со своей информационной базы.
Многопользовательская работа
Одним из основных показателей масштабируемости системы является возможность эффективной работы при увеличении количества решаемых задач, объема обрабатываемых данных и количества интенсивно работающих пользователей.
В варианте клиент-сервер обеспечивается возможность параллельной работы большого количества пользователей. Как показывают тесты, с ростом числа пользователей скорость ввода документов уменьшается очень медленно. Это означает, что при увеличении количества интенсивно работающих пользователей скорость реакции автоматизированной системы остается на приемлемом уровне.
В модели данных, поддерживаемой системой «1С:Предприятие 8», не существует таблиц базы данных, однозначно приводящих к конкурентному доступу со стороны нескольких пользователей. Конкурентный доступ возникает только при обращении к логически связанным данным и не затрагивает данные, не связанные между собой с точки зрения предметной области.
Конкурентный доступ возникает только при обращении к логически связанным данным и не затрагивает данные, не связанные между собой с точки зрения предметной области.
При выполнении регламентных операций исключены ситуации, когда для начала работы в некотором отчетном периоде требуется установка монопольного режима. Регламентные операции могут выполняться в удобные для пользователей и организации моменты времени. Монопольный режим устанавливается не при запуске системы, а в тот момент, когда необходимо выполнение операции, требующей его включения. После выполнения таких операций монопольный режим может быть отключен.
Механизмы оптимизации
Технологическая платформа «1С:Предприятия 8» содержит ряд механизмов, оптимизирующих скорость работы прикладных решений.
Управление блокировками в транзакции
Режим управляемых блокировок в транзакции позволяет управлять блокировками данных в терминах предметной области и повышает параллельность работы пользователей. Подробнее…
Подробнее…
Выполнение на сервере
В варианте клиент-сервер использование сервера «1С:Предприятия 8» позволяет сосредоточить на нем выполнение наиболее объемных операций по обработке данных. Например, при выполнении даже весьма сложных запросов программа, работающая у пользователя, будет получать только необходимую ей выборку, а вся промежуточная обработка будет выполняться на сервере. Обычно увеличить мощность сервера гораздо проще, чем обновить весь парк клиентских машин.
Кэширование данных
Система «1С:Предприятие 8» использует механизм кэширования данных, считанных из базы данных при использовании объектной техники. При обращении к реквизиту объекта выполняется чтение всех данных объекта в кэш, расположенный в оперативной памяти. Последующие обращения к реквизитам того же объекта будут направляться уже в кэш, а не в базу данных, что значительно сокращает время, затрачиваемое на получение нужных данных.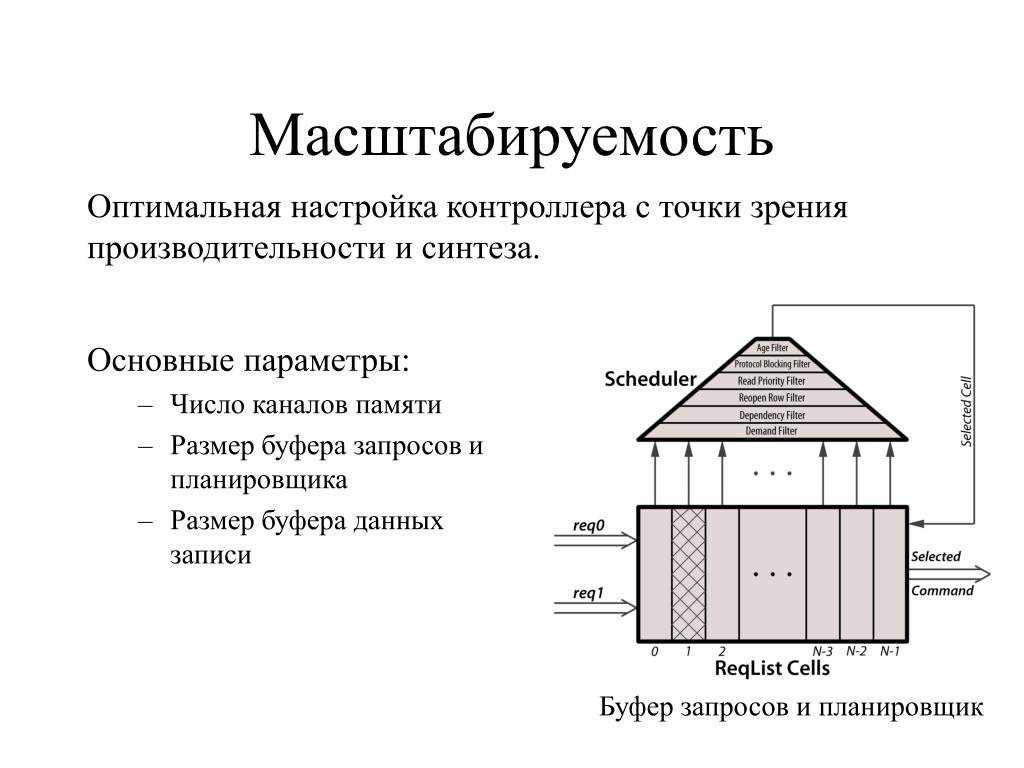
Работа встроенного языка на сервере
При работе в клиент-серверном варианте вся работа прикладных объектов выполняется только на сервере. Функциональность форм и командного интерфейса также реализована на сервере.
На сервере выполняется подготовка данных формы, расположение элементов, запись данных формы после изменения. На клиенте отображается уже подготовленная на сервере форма, выполняется ввод данных и вызовы сервера для записи введенных данных и других необходимых действий.
Аналогично командный интерфейс формируется на сервере и отображается на клиенте. Также и отчеты формируются полностью на сервере и отображаются на клиенте.
Примеры технологических параметров внедрений решения «Управление производственным предприятием»
В этом разделе публикуется развернутая информация о технологических параметрах внедрений «1C:Предприятие 8. Управление производственным предприятием» на предприятиях различного масштаба и профиля деятельности.
Управление производственным предприятием» на предприятиях различного масштаба и профиля деятельности.
Цель раздела — ознакомить ИТ- специалистов с данными о реально используемом оборудовании и с примерами нагрузки реальных внедрений «1С:Предприятия 8».
Также эта информация может быть полезна и для пользователей всех программ системы «1С:Предприятие 8».
1С:Центр управления производительностью — инструмент мониторинга и анализа производительности
1С:Центр управления производительностью (1С:ЦУП) — инструмент мониторинга и анализа производительности информационных систем на платформе «1С:Предприятие 8». 1С:ЦУП предназначен для оценки производительности системы, сбора подробной технической информации об имеющихся проблемах производительности и анализа этой информации с целью дальнейшей оптимизации. Подробнее…
1С:ТестЦентр — инструмент автоматизации нагрузочных испытаний
1С:ТестЦентр — инструмент автоматизации многопользовательских нагрузочных испытаний информационных систем на платформе «1С:Предприятие 8». С его помощью можно моделировать работу предприятия без участия реальных пользователей, что позволяет оценивать применимость, производительность и масштабируемость информационной системы в реальных условиях. Подробнее…
С его помощью можно моделировать работу предприятия без участия реальных пользователей, что позволяет оценивать применимость, производительность и масштабируемость информационной системы в реальных условиях. Подробнее…
Внедрение корпоративных информационных систем на платформе «1С:Предприятие 8»
Опыт внедрения прикладных решений на платформе «1С:Предприятие 8» показывает, что система позволяет решать задачи различной степени сложности — от автоматизации одного рабочего места до создания информационных систем масштаба предприятия.
В то же время, внедрение большой информационной системы предъявляет повышенные требования по сравнению с небольшим или средним внедрением. Информационная система масштаба предприятия должна обеспечивать приемлемую производительность в условиях одновременной и интенсивной работы большого количества пользователей, которые используют одни и те же информационные и аппаратные ресурсы в конкурентном режиме. Подробнее…
Подробнее…
База знаний по технологическим вопросам крупных внедрений
Фирма «1С», совместно с сертифицированными «1С:Экспертами по технологическим вопросам» и другими техническими специалистами, ведет и регулярно обновляет базу знаний по технологическим вопросам крупных внедрений.
База знаний — это постоянно пополняемый информационный ресурс, который является основным источником информации по технологическим вопросам крупных внедрений:
- Методики и технологии, ориентированные на повышение качества крупных внедрений
- Технологические проблемы крупных внедрений и способы их решения
Подробнее…
Расширяемость и масштабируемость | Компьютерные сети
Термины «расширяемость» и «масштабируемость» иногда неверно используют как синонимы.
Наши партнеры:
— Возможно эта информация Вас заинтересует:
— Посмотрите интересные ссылочки вот тут:
Расширяемость означает возможность сравнительно простого добавления отдельных компонентов сети (пользователей, компьютеров, приложений, служб), наращивания длины сегментов кабелей и замены существующей аппаратуры более мощной.
При этом принципиально важно, что простота расширения системы иногда может обеспечиваться в определенных пределах. Например, локальная сеть Ethernet, построенная на основе одного разделяемого сегмента коаксиального кабеля, обладает хорошей расширяемостью в том смысле, что позволяет легко подключать новые станции. Однако такая сеть имеет ограничение на число станций — оно не должно превышать 30-40. Хотя сеть допускает физическое подключение к сегменту и большего числа станций (до 100), при этом резко снижается производительность сети. Наличие такого ограничения и является признаком плохой масштабируемости системы при ее хорошей расширяемости.
Масштабируемость означает, что сеть позволяет наращивать количество узлов и протяженность связей в очень широких пределах, при этом производительность сети не снижается.
Для обеспечения масштабируемости сети приходится применять дополнительное коммуникационное оборудование и специальным образом структурировать сеть. Обычно масштабируемое решение обладает многоуровневой иерархической структурой, которая позволяетдобавлять элементы на каждом уровне иерархии без изменения главной идеи проекта.
Обычно масштабируемое решение обладает многоуровневой иерархической структурой, которая позволяетдобавлять элементы на каждом уровне иерархии без изменения главной идеи проекта.
Примером хорошо масштабируемой сети является Интернет, технология которого (TCP/IP) оказалась способной поддерживать сеть в масштабах земного шара. Организационная структура Интернета, которую мы рассмотрели в главе 5, образует несколько иерархических уровней: сети пользователей, сетей локальных поставщиков услуг и т. д. вверх по иерархии вплоть до сетей межнациональных поставщиков услуг. Технология TCP/IP, на которой построен Интернет, также позволяет строить иерархические сети. Основной протокол Интернета (IP) основан на двухуровневой модели: нижний уровень составляют отдельные сети (чаще всего сети корпоративных пользователей), а верхний уровень — это составная сеть, объединяющая эти сети. Стек TCP/IP поддерживает также концепцию автономной системы. В автономную систему входят все составные сети одного поставщика услуг, так что автономная система представляет собой более высокий уровень иерархии.
Наличие автономных систем в Интернете позволяет упростить решение задачи нахождение оптимального маршрута — сначала ищется оптимальный маршрут между автономными системами, а затем каждая автономная система находит оптимальный маршрут внутри себя.
Не только сама сеть должна быть масштабируемой, но и устройства, работающие на магистрали сети, также должны обладать этим свойством, так как рост сети не должен приводить к необходимости постоянной смены оборудования. Поэтому магистральные коммутаторы и маршрутизаторы строятся обычно по модульному принципу, позволяя наращивать количество интерфейсов и производительность обработки пакетов в широких пределах.
Проектирование масштабируемых приложений Azure — Azure Architecture Center
-
 date»>12/01/2020
date»>12/01/2020 - Чтение занимает 8 мин
В этой статье
Проектирование приложений крайне важно для обработки масштабирования при увеличении нагрузки. Эта статья поможет вам получить представление о самых важных темах. Дополнительные разделы, связанные с масштабированием, см. в статье проектирование приложений Azure для повышения эффективности в области эффективности производительности.
Выбор правильного хранилища данных
Общая структура уровня данных может значительно повлиять на производительность и масштабируемость приложения. Платформа службы хранилища Azure разработана для массовой масштабируемости в соответствии с требованиями к хранению и производительности современных приложений.
Службы данных на платформе хранилища Azure:
- Большой двоичный объект Azure — хранилище масштабируемых объектов для текстовых и двоичных данных. включает поддержку анализа больших данных с помощью Data Lake Storage 2-го поколения.

- Файловые ресурсы, управляемые службой файлов Azure для облачных или локальных развертываний.
- Очередь Azure — хранилище сообщений для надежного обмена сообщениями между компонентами приложения.
- Таблицы Azure — хранилище NoSQL для хранения структурированных данных, не имеющих схемы.
- Диски Azure — тома хранилища на уровне блоков для виртуальных машин Azure.
Большинство облачных рабочих нагрузок применяют подход Polyglot сохраняемости. Вместо использования одной службы хранилища данных используется сочетание технологий. В зависимости от требований приложение, скорее всего, потребует больше одного типа хранилища данных. Примеры использования этих типов хранения данных см. в разделе примеры сценариев.
Доступ ко всем службам осуществляется с помощью учетной записи хранения. Чтобы приступить к работе, создайте такую учетную запись.
Рекомендации по базе данных
Выбор базы данных может повлиять на производительность и масштабируемость приложения. Операции чтения и записи базы данных требуют сетевого вызова и ввода-вывода хранилища, которые являются дорогостоящими операциями. Выбор правильной службы базы данных для хранения и извлечения данных, следовательно, является критически важным решением и следует учитывать, чтобы обеспечить масштабируемость приложений. В Azure имеется множество служб баз данных, которые будут соответствовать большинству нужд. Кроме того, существуют сторонние параметры, которые можно рассматривать в Azure Marketplace.
Операции чтения и записи базы данных требуют сетевого вызова и ввода-вывода хранилища, которые являются дорогостоящими операциями. Выбор правильной службы базы данных для хранения и извлечения данных, следовательно, является критически важным решением и следует учитывать, чтобы обеспечить масштабируемость приложений. В Azure имеется множество служб баз данных, которые будут соответствовать большинству нужд. Кроме того, существуют сторонние параметры, которые можно рассматривать в Azure Marketplace.
чтобы облегчить выбор типа базы данных, определите требования к хранилищу приложения относительно реляционной структуры (SQL) по сравнению со структурой «ключ-значение», «документ/граф» (NoSQL). некоторые приложения могут иметь как SQL, так и базу данных NoSQL для различных потребностей в хранении. Используйте дерево решений хранилища данных Azure , чтобы найти соответствующее решение для хранения управляемых данных.
Зачем использовать реляционную базу данных?
Используйте реляционную базу данных, если гарантии строгой согласованности важны, где все изменения являются атомарными, а транзакции всегда оставляют данные в согласованном состоянии. Однако реляционная база данных обычно не может горизонтально масштабироваться без сегментирования данных каким-либо образом. Реализация сегментирования вручную может быть трудоемкой задачей. Кроме того, данные в реляционной базе данных должны быть нормализованы, что не подходит для каждого набора данных.
Если реляционная база данных считается оптимальной, Azure предлагает несколько параметров PaaS, которые полностью управляют размещением и эксплуатацией базы данных. База данных SQL Azure может содержать отдельные базы данных или несколько баз данных (База данных SQL Azure Управляемый экземпляр). Набор предложений охватывает требования к производительности, масштабированию, размеру, устойчивости, аварийному восстановлению и совместимости с миграцией. Azure предлагает следующие службы реляционных баз данных PaaS:
Зачем использовать базу данных NoSQL?
Используйте базу данных NoSQL, если производительность и доступность приложения важнее, чем строгая согласованность. Базы данных NoSQL идеально подходят для обработки больших, несвязанных, неопределенных или быстро меняющихся данных. NoSQL базы данных имеют компромиссы. Дополнительные сведения см. в статье некоторые трудности с базами данных NoSQL.
azure предоставляет две управляемые службы, оптимизированные для решений NoSQL: Azure Cosmos DB и кэш Azure для Redis. для баз данных документов и графов Cosmos DB обеспечивает экстремальное масштабирование и производительность.
Подробное описание NoSQL и реляционных баз данных см. в разделе Основные сведения о различиях.
Выбор правильного размера виртуальной машины
Выбор неправильного размера виртуальной машины может привести к проблемам с емкостью, так как виртуальные машины приближается к их ограничениям. Это также может привести к ненужным затратам. Чтобы выбрать правильный размер виртуальной машины, учитывайте рабочие нагрузки, количество ЦП, емкость ОЗУ, размер диска и скорость в соответствии с бизнес-требованиями. Сведения о снимках размеров виртуальных машин Azure и их целях см. в статье размеры виртуальной машины в Azure.
Azure предоставляет следующие категории размеров виртуальных машин, каждый из которых предназначен для выполнения различных рабочих нагрузок. Щелкните категорию, чтобы получить дополнительные сведения.
- Общее назначение — обеспечивает сбалансированное соотношение ресурсов ЦП и памяти. Идеальное решение для тестирования и разработки, небольших и средних баз данных, а также веб-серверов с небольшим или средним объемом трафика.
- Оптимизированная для памяти — обеспечивает высокое соотношение памяти и ЦП, которое отлично подходит для серверов реляционных баз данных, средних и больших кэшей и аналитики в памяти.
- Оптимизированные для вычислений ресурсы имеют высокое соотношение ресурсов ЦП и памяти. Эти размеры подходят для веб-серверов со средним объемом трафика, сетевых устройств, пакетных процессов и серверов приложений.
- Оптимизированный GPU — доступен с помощью одного, нескольких и дробных GPU. Эти размеры предназначены для рабочих нагрузок с большим объемом вычислений, графической обработки и визуализаций.
- Высокопроизводительное вычисление — предназначено для предоставления лидерам производительности, масштабируемости и экономичности для различных реальных рабочих нагрузок HPC.
- служба хранилища, оптимизированный для повышения пропускной способности дисков и операций ввода-вывода, идеально подходит для больших данных, SQL, баз данных NoSQL, хранилищ данных и больших транзакционных баз данных. Примеры включают Cassandra, MongoDB, Cloudera и Redis.
Требования к размерам можно изменить в соответствии с вашими потребностями и требованиями.
Сборка с микрослужбами
Архитектура микрослужб широко используется для создания устойчивых, высокомасштабируемых, независимо развертываемых и быстро растущих приложений. Архитектура микрослужб представляет собой набор небольших автономных служб. Каждая служба является самодостаточной и должна реализовывать возможности одной компании. Разбиение больших сущностей на небольшие дискретные части не гарантирует возможности изменения размера и масштабирования. Для управления этим необходимо написать логику приложения.
Одним из многих преимуществ микрослужб является то, что их можно масштабировать независимо друг от друга. Это позволяет масштабировать подсистемы, требующие больше ресурсов, без масштабирования всего приложения. Еще одно преимущество — изоляция сбоев. Если одна микрослужба станет недоступна, это не нарушит работу всего приложения, так как все вышестоящие микрослужбы спроектированы правильно реагировать на ошибки (например, путем реализации автоматического выключения).
Дополнительные сведения о преимуществах микрослужб см. в статье преимущества.
Сборка с микрослужбами имеет такие трудности, как разработка и тестирование. Написание небольшой службы, основанной на других зависимых службах, требует иного подхода, чем написание традиционного монолитного или многоуровневого приложения. Существующие средства не всегда предназначены для работы с зависимостями служб. Рефакторинг между службами может быть сложной задачей. Также непросто тестировать зависимости служб, особенно если приложение быстро изменяется.
Список возможных недостатков архитектуры микрослужбы см. в статье проблемы .
Использование динамической службы обнаружения для приложений микрослужб
При наличии нескольких отдельных служб или экземпляров служб они должны будут получить инструкции по контактам и (или) другим сведениям о конфигурации. Жестко программировать эти сведения являются изъянами, и здесь приведены инструкции по обнаружению служб в. Экземпляр службы может создавать и динамически обнаруживать сведения о конфигурации, необходимые для работы, без жестко закодированной информации.
в сочетании с платформой оркестрации, предназначенной для выполнения и управления микрослужбами, такими как Kubernetes или Service Fabric, отдельные службы могут иметь правильный размер, масштабироваться, масштабироваться и динамически настраиваться в соответствии с потребностями пользователей. С помощью оркестраторов (например, Kubernetes или Service Fabric) вы можете создавать на одном узле пакеты служб с более высокой плотностью, оптимизируя использование ресурсов. Обе эти платформы предоставляют встроенные службы для выполнения, масштабирования и работы архитектуры микрослужб. Одна из этих ключевых служб — обнаружение и поиск места запуска определенной службы.
Kubernetes поддерживает автоматическое масштабирование Pod и автоматическое масштабирование кластера. Дополнительные сведения см. в разделе Автомасштабирование. архитектура Service Fabric использует другой подход к масштабированию для служб без отслеживания состояния и с отслеживанием состояния. Дополнительные сведения см. в разделе рекомендации по масштабированию.
Совет
При необходимости разбить приложение на микрослужбы — это уровень разделения, который является архитектурной практикой. Архитектура микрослужб может также привести к некоторым проблемам. Шаблоны разработки в шаблонах разработки для микрослужб могут помочь устранить эти проблемы.
Создание пулов соединений
Установка соединений с базами данных обычно является дорогостоящей операцией, которая подразумевает установку сетевого подключения с проверкой подлинности к удаленному серверу базы данных. Это особенно справедливо для приложений, которые часто открывают новые подключения. Использование пулов соединений для уменьшения задержки подключения путем повторного использования существующих соединений и включения более высокой пропускной способности базы данных (транзакций в секунду) на сервере. Это позволяет избежать расходов на открытие нового соединения для каждого запроса.
Ограничения размера пула
Azure ограничивает количество сетевых подключений, которые может создать виртуальная машина или экземпляр AppService. Превышение этого ограничения приведет к снижению или прерыванию соединения. При использовании пулов соединений фиксированный набор соединений устанавливается во время запуска и сохраняется. Во многих случаях размер пула по умолчанию может состоять только из небольшого числа подключений, которые быстро выполняются в базовых тестовых сценариях, но становятся узким местом при масштабе, когда пул исчерпан. Рекомендуется устанавливать размер пула, который соответствует количеству параллельных транзакций, поддерживаемых в каждом экземпляре приложения.
Каждая платформа базы данных и приложения будет иметь несколько отличающихся требований для настройки и использования пула. пример кода .net с помощью SQL Server и базы данных Azure см. в разделе SQL Server создание пулов соединений . Во всех случаях тестирование имеет первостепенное значение для обеспечения правильной установки пула соединений и работы в соответствии с нагрузкой.
Совет
Используйте размер пула, который использует то же количество параллельных подключений. Выберите размер, который может выполнять больше существующих подключений, чтобы можно было быстро справиться с новым запросом, поступающим в.
Встроенные функции безопасности
Встроенная безопасность — это единое унифицированное решение для защиты каждой службы, выполняемой предприятием, с помощью набора общих политик и параметров конфигурации. В дополнение к сокращению проблем, связанных с масштабированием, подготовкой и управлением (включая более высокие затраты и сложность), встроенная безопасность также повышает управляемость и общую безопасность. Однако могут возникнуть ситуации, когда использование пула соединений может не потребоваться по соображениям безопасности. Например, хотя пул подключений повышает производительность последующих запросов к базе данных для одного пользователя, этот пользователь не может воспользоваться преимуществами подключений, сделанных другими пользователями. Это также приводит по крайней мере к одному соединению с сервером базы данных для каждого пользователя.
Измерьте требования к безопасности бизнеса в соответствии с преимуществами и недостатками пулов соединений. Дополнительные сведения см. в разделе Фрагментация пула .
Дальнейшие действия
Перспективные механизмы повышения масштабируемости СХД
Масштабируемость – способность продолжать решать задачу, когда масштабы этой задачи растут.
Тео Шлосснагл
За последние несколько лет человечество произвело информации больше, чем за всю предшествующую историю своего существования. Мы генерируем данные в огромных объемах: согласно исследованию IDC, уже к 2020 г. будет накоплено около 44 зеттабайт (для сравнения: в 2014 г. – только 4,4 зеттабайта). Развитие Интернета вещей, промышленного Интернета, увеличение разрешения камер видеонаблюдения, повышение пропускной способности каналов – все это приводит к экспоненциальному увеличению объема информации. Соответственно растет потребность в системах хранения данных, ужесточаются технические требования к ним.
Scale-up vs. Scale-out
Архитектурно системы хранения данных (СХД) можно поделить на два типа: Scale-up – традиционные системы с вертикально масштабируемой архитектурой и Scale-out – горизонтально масштабируемые системы.
По оценкам экспертов компании «АРСИЭНТЕК» (RCNTEC), на сегодняшний день около 95% российских ИT-компаний используют системы хранения данных с вертикально масштабируемой архитектурой.
Традиционные СХД с вертикальным масштабированием (Scale-up) ограничены производительностью контроллеров. Емкость таких систем ограничивается десятками петабайт, и наращивается она путем добавления дисковых полок, количество которых всегда лимитировано. При этом распределение информации между старыми и новыми массивами является ручной операцией, а процесс переноса сопровождается снижением производительности СХД. Рано или поздно такие системы достигают своего потолка, и тогда приходится покупать новый, более мощный контроллер. Независимо от мощности контроллера при увеличении объемов данных и интенсивности работы с ними контроллеры как единственная точка входа-выхода становятся «бутылочным горлышком» подобной системы.
Основатель OmniTI инженер Тео Шлосснагл (Theo Schlossnagle), член IEEE и ACM, совершенно правильно утверждал, что именно «горизонтальное масштабирование – лучший (и единственный полноценный) способ масштабирования».
На сегодняшний день лучше всего задача масштабирования решена крупнейшими зарубежными и российскими интернет-компаниями – Amazon, Google, Facebook, «Яндекс», «ВКонтакте». Они давно осознали, что вертикальным масштабированием постоянно наращивать емкость и производительность СХД нельзя, и начали строить свои системы хранения из большого количества маленьких блоков, стыкующихся в общую сеть хранения данных.
В горизонтально масштабируемых системах (Scale-out) отсутствуют централизованные контроллеры, клиенты общаются с дисковыми модулями напрямую. Соответственно при необходимости увеличить емкость системы хранения или производительность в общую систему просто устанавливаются и подключаются дополнительные дисковые модули.
Таким образом, любая компания может начать с минимально необходимого ей количества модулей и затем уже плавно расти по мере увеличения потребности в дисковом пространстве и производительности.
Естественно, расширять емкость и производительность уже имеющейся системы выгоднее, чем менять ее на новую, более мощную, поэтому такое горизонтальное масштабирование является набирающим силу трендом.
Программно-определяемые СХД – естественная закономерность развития ИТ
Рассуждая о перспективах повышения масштабирования, мы говорим прежде всего о горизонтально масштабируемых системах хранения данных. Это в первую очередь программно-определяемые СХД (Software-Defined Storage – SDS).
Сейчас даже у классически сильных вендоров СХД в портфолио есть системы SDS, например, та же ScaleIO у компании EMC, влившейся недавно в Dell.
Если смотреть на развитие систем хранения данных в контексте общего развития ИТ-технологий, то мы увидим, что появление и развитие программно-определяемых СХД выглядит как вполне естественная закономерность. Например, в телекоммуникациях уже фактически совершилась подобная трансформация проприетарных систем на базе TDM и закрытых управляющих модулей в сторону VoIP и выноса логики управления на открытые платформы, в первую очередь ОС Linux на commodity ×86 серверах.
Нечто похожее происходит сейчас в радиосвязи, когда на замену приемопередатчикам с жестко реализованным в «железе» набором функциональных возможностей приходит технология Software Defined Radio (SDR), где это реализуется на базе открытых DSP. В области сетей активно развивается технология Software Defined Networking (SDN) – она означает разделение уровня непосредственно коммутации пакетов и логики управления этим процессом с выносом последней опять же на открытые платформы. Так что программно-определяемые СХД являются естественным продолжением общего тренда.
«Все системы давно уже, в первую очередь – это ПО, – подтверждает генеральный директор «АРСИЭНТЕК» Денис Нештун, – но когда нужно, чтобы система работала хорошо, ПО и оборудование должны работать вместе, а для этого они должны быть протестированы и взаимоувязаны. Долгое время мы осуществляли поддержку самых разных информационных систем и отлично понимаем, насколько трудно обеспечить работоспособность, если у вас ИТ-оборудование и/или программное обеспечение разношерстные. Мы стараемся избавить заказчика от этой головной боли и поставляем ему аппаратно-программный комплекс, о котором знаем, что он точно будет работать. При наращивании емкости он будет понятным образом развиваться и, что очень важно, обеспечит совместимость разных поколений дисковых модулей. По сути, система хранения данных «Полибайт» является программно-определяемой средой хранения, которая построена на базе нашего аппаратно-программного комплекса».
С увеличением объемов хранимой и передаваемой информации у традиционных файловых хранилищ обнаруживается ряд недостатков. Все более популярными становятся объектные СХД, обеспечивающие высокую производительность и отказоустойчивость при работе с большим объемом неструктурированных данных. Но ключевой функцией этих новых программно-определяемых СХД является использование нескольких протоколов сразу, т. е. сочетание в себе файлового, блочного и объектного хранилища.
Open source: все ли гладко?
Выбирая себе систему хранения данных, многие останавливаются на SDS c открытым кодом, таких как GLUSTERFS, CEPH, ZFS, LUSTRE и др. Обычно к таким решениям приходят те, кто хочет сэкономить, ибо зачем покупать готовое решение у кого-то, когда и самому можно скачать все то же самое, причем бесплатно.
Но подобная экономия может дорого обойтись. Во-первых, сделать так, чтобы система заработала, т. е. увязать открытое ПО с имеющимся у вас «железом», под силу далеко не каждому. Квалификация инженеров в компании должна быть очень высокой.
Во-вторых, в отличие от коммерческих ЦОД, когда любой возникшей проблемой занимается вендор, в случае использования Open Source все проблемы и сбои ложатся на плечи самого внедренца.
В истории есть случаи, когда из-за таких сбоев разрушались целые бизнесы. Например, компания Cloudmouse сделала свою систему на текущей версии CEPH и в результате сбоя в марте 2015 г. потеряла данные 22 тыс. виртуальных машин, включая их бэкапы. Эта компания в конечном счете была вынуждена уйти с рынка.
В-третьих, баги и сбои неизбежно будут: коммерческие решения не зря стоят своих денег. Чтобы решения Open Source нормально работали, на «допиливание» может уйти не один год кропотливого труда.
Так что «бесплатность» решений Open Source – во многом кажущаяся, а в неумелых руках программно-определяемыe СХД c открытым кодом могут быть просто опасны и для пользователей, и для самой компании.
Все в одном? – Плюсы и минусы гиперконвергентных инфраструктур
Набирающим популярность трендом является идеология создания гиперконвергентных инфраструктур, например EMC VxRail или Cisco HyperFlex.
От конвергентных эти системы отличаются простотой управления и расширения, а также более эффективным использованием оборудования, поскольку фактически здесь все возможные ресурсы объединяются в единый пул. Управление такими системами, осуществляемое через общую консоль, по силам одному системному администратору. Для горизонтального роста гиперконвергентной системы достаточно просто добавлять в нее новые узлы.
Пример хранилища корпоративного класса для подобной гиперконвергентной инфраструктуры – VMware Virtual SAN. Развертывание этого решения может быть выполнено на недорогих стандартных серверах, что позволит избежать компании крупных начальных инвестиций. Управление Virtual SAN максимально автоматизировано. При успешной интеграции с имеющимся оборудованием, как заявляют производители, совокупная стоимость владения может быть снижена до 50%. Из недостатков VSAN можно назвать ограничение максимального количества хостов – их всего 64. Следовательно, масштабируемость такой системы существенно ограничена.
Гиперконвергентные решения нельзя назвать панацеей, и подходят они не всем, скорее, занимают свою узкопрофильную нишу в мире СХД.
«Мы считаем, что гиперконвергентные системы не являются универсальными СХД. Профили использования вычислительных ресурсов и ресурсов хранения данных не одинаковы, поэтому невозможно придумать небольшое количество конфигураций гиперконвергентных модулей, так чтобы они решали потенциально любые задачи в частных или в публичных облаках. На наш взгляд, целесообразно строить независимые горизонтально масштабируемую вычислительную платформу и горизонтально масштабируемую систему хранения данных. Это позволяет наращивать те ресурсы, в которых возникает потребность», – комментирует Денис Нештун.
Flash-революция
Говоря о тенденциях в мире современных СХД, нельзя пройти мимо тренда, который мы сейчас наблюдаем в коммерческих ЦОД: SSD-накопители там постепенно вытесняют традиционные HDD. И это естественно, поскольку они обладают рядом преимуществ: потребляют мало энергии, практически не нагреваются при работе и зачастую по производительности на два порядка превосходят HDD.
Главным минусом твердотельных накопителей относительно шпиндельных можно считать их цену. Однако же, по прогнозам экспертов «АРСИЭНТЕК», эта разница в ближайшие несколько лет непременно начнет сокращаться и постепенно сойдет на нет. Производством HDD-накопителей сейчас, по результатам всех слияний и поглощений, занимаются лишь две компании в мире, а SSD – около 200 компаний. Итак, вендоры вынуждены конкурировать между собой, что приводит не только к снижению цен, но и к ускоренному развитию технологий.
Исследования аналитиков IDC также подтверждают данный тренд: «В I квартале 2016 г. впервые в истории российского рынка внешних систем хранения данных общая стоимость гибридных систем, построенных с использованием Flash-памяти, превысила совокупную стоимость традиционных систем на привычных жестких дисках. Таким образом, революционное изменение можно считать свершившимся, и в будущем нам стоит ожидать лишь роста поставок гибридных систем и систем All-Flash», – полагает Михаил Попов, старший аналитик IDC по корпоративным системам.
За горизонтом
Рынок СХД сегодня развивается головокружительными темпами – это обусловлено количеством генерируемой человечеством информации и потребностью ее хранения. Заглядывая вперед, можно с достаточной долей уверенности сказать, что в ближайшие несколько лет темпы развития СХД снижаться не будут.
«Если говорить о системах хранения данных, то следующим шагом в увеличении эффективности СХД будет распределение вычислительных функций хранилища на накопители – это приведет к уменьшению компонентов СХД и повышению их специализации, что, в свою очередь, обусловит повышение плотности хранения и снижение удельной стоимости», – резюмирует Денис Нештун.
Connect благодарит компанию «АРСИЭНТЕК» за помощь в подготовке материала.
Что на самом деле означает «масштабируемость» в мире блокчейна?
Масштабируемость — одна из самых важных проблем в блокчейне. С тех пор, как появился Биткоин, она была в центре внимания как практиков отрасли, так и ученых. Чжицзе Рен и Питер Чжоу исследуют вопросы масштабируемости блокчейна в VeChain и сравнивают различные блокчейны, анализируя их плюсы и минусы. Их цель — обеспечить как криптовалютные сообщества, так и широкую публику глубоким пониманием текущего состояния развития блокчейна. Думаю, вам это тоже будет чертовски интересно. Далее — от первого лица.
Независимо от того, исследуете ли вы блокчейн в академических кругах или просто тащитесь от происходящего в мире крипты, вы наверняка слышали термин «масштабируемость» (scalability) или «масштабируемый блокчейн» (scalable blockchain). Об этом так много говорят, столько шума. Однако в большинстве случаев за «масштабируемым» блокчейном скрывается обычная цепочка блоков, способная достигать высоких показателей TPS (транзакций в секунду). Иногда бывает даже так, что истинный смысл «масштабируемости» искажается или даже намеренно меняется, чтобы ввести людей в заблуждение и получить незаслуженные преимущества. С другой стороны, мы видели массу докладов и статей, написанных исследовательскими институтами, компаниями или СМИ, в которых пытаются объективно сравнить масштабируемость разных блокчейнов. Однако вряд ли хоть кто-то из них способен отличить лживые утверждения от имеющих под собой почву.
Несмотря на то, что понятие масштабируемости хорошо определено во многих научных областях, в мире блокчейна у него довольно много значений, это вы увидите позже. Мы хотим показать вам новейшие разработки в области масштабируемости блокчейна, как от практиков блокчейна, так и от научных, что более важно, исследователей. Мы считаем, что обществу крайне необходимо лучше понять эту проблему. Тогда отрасль в целом будет расти здоровее и быстрее.
Для большинства компьютерных систем — например, базы данных или поисковой системы — «масштабируемость» означает способность системы обрабатывать растущий объём работы, то есть масштабироваться. Система плохо масштабируется или, иными словами, имеет плохую масштабируемость, если вместо того, чтобы задействовать больше ресурсов (например, подключать дополнительную вычислительную мощность, серверы или пропускную способность), она требует дополнительных усилий по модификации системы, чтобы быть в состоянии справиться с возросшей нагрузкой.
И всё же, в области блокчейна у слова «масштабируемость» гораздо более широкий диапазон значений. Да что там говорить — даже термин «блокчейн» пока не получил хорошего определения с академической точки зрения. К примеру, если говорить про Bitcoin, многие до сих пор считают «масштабированием» любое улучшение пропускной способности, задержки, времени начальной загрузки или стоимости транзакций.
В наши дни есть много различных систем блокчейна, которые можно считать «масштабируемым», однако их пропускная способность сильно отличается. Обратите внимание, что слово «масштабируемый» является сравнительным термином в блокчейне. Когда система называется масштабируемой, это значит, что она достигает более высокого значения TPS, чем другие существующие системы, путём изменения механизма консенсуса и/или уточнения некоторых параметров системы.
Фактически, мы можем классифицировать масштабируемые блокчейны на четыре типа:
- 1. Масштабирование Bitcoin: решения для повышения пропускной способности Bitcoin за счёт увеличения размера блока или сокращения интервала блока без изменений в POW-алгоритме консенсуса
- 2. Масштабирование POW: решения, которые всё еще укладываются в структуру консенсуса Сатоши Накамото, но достигают более высокой пропускной способности, чем POW-алгоритм в Биткоине, за счёт изменения алгоритма
- 3. Масштабирование алгоритмов византийской отказоустойчивости (Byzantine Fault Tolerance, BFT): решения, основанные на BFT-алгоритмах, но с более простыми сообщениями, нежели в алгоритмах Practical Byzantine Fault Tolerance, PBFT
- 4. Масштабируемые блокчейны: решения, которые ослабляют требование того, что узлы валидации/майнинга должны знать всю историю транзакций. Благодаря этому пропускная способность системы может возрастать с увеличением размера сети и, следовательно, лучше масштабироваться, чем системы трёх вышеупомянутых типов
Масштабирование Bitcoin
Все мы знаем, что Биткоин плохо масштабируется. Потому что дизайн POW (proof-of-work), лежащий в основе работы Биткоина, это не позволяет. В Биткоине POW используется как метод случайного определения следующего действительного (valid) блока, то есть все узлы «работают» (обеспечивают доказательство проделанной работы, POW) в течение определённого времени, чтобы определить победителя. Более того, новый блок должен быть синхронизирован со всей сетью, чтобы каждый узел мог (плюс-минус) конкурировать с другими в гонке за следующий блок. По сути, POW Биткоина обладает каскадной структурой, как на рисунке ниже.
Каскадная структура POW Биткоина запускает алгоритм консенсуса только после того, как все узлы закончат получать и проверять все блоки.
То, что синхронизация занимает 1 минуту, когда длительность работы POW составляет 10 минут (как в Биткоине) — это нормально. Но Биткоин больше не будет честным и безопасным, если время синхронизации будет сопоставимо с каждым циклом POW, что произойдёт, если размер блока увеличится или интервал блока значительно уменьшится — например, до 1 минуты. В таком случае в сети появится много форков, ответвлений, что в итоге приведёт к очень долгому времени подтверждения и снижению уровня безопасности.
Другими словами, неочевидное ограничение Биткоина заключается в том, что время каждого раунда работы алгоритма консенсуса должно быть значительно больше периода синхронизации. Сколько времени уйдёт на синхронизацию — зависит не только от дизайна алгоритма консенсуса, но и в значительной степени от характеристик основной сети, например, от пропускной способности, задержки, топологии, уровня децентрализации. В работе ‘On scaling decentralized blockchains‘ (О масштабировании децентрализованных блокчейнов) подсчитано, что Bitcoin мог обеспечить не больше 27 транзакций в секунду на сети Bitcoin в 2016 году. Это ограничение может быть неприменимо к отдельному альткоину, использующему тот же алгоритм POW для достижения консенсуса, или даже к современному Bitcoin, так как сети отличаются по размеру или уровню децентрализации. Однако вышеупомянутое ограничение остается в силе. Следовательно, «наивные» подходы, которые увеличивают блок (привет BCH — от редакции) или уменьшают интервал между блоками, могут «масштабировать» Биткоин совсем чуть-чуть.
Масштабирование POW
Для решения проблемы, изложенной выше, предлагаются новые схемы POW, в которых безопасность системы не зависит от синхронизации новых блоков, как показано на рисунке ниже. Другими словами, период согласования (достижения консенсуса) не обязательно должен быть значительно больше времени синхронизации, его можно оставить примерно или в точности таким же. Например, в Bitcoin-NG консенсус используется только для определения лидера раунда вместо целого набора транзакций. Таким образом, синхронизация транзакций может выполняться параллельно и может использоваться больший размер блока. Другие похожие блокчейны в этой категории имеют Hybrid Consensus, Byzcoin и GHOST.
Масштабируемый POW распараллеливал бы синхронизацию и согласование с консенсусом, таким образом всю пропускную способность можно было бы использовать для передачи сообщений.
POS (proof-of-stake)
Мы можем включить некоторые новые схемы POS в категорию масштабируемого POW с точки зрения масштабируемости. Всё потому, что в таких системах консенсус в сети достигается с помощью механизмов выбора лидера, которые основаны на генераторах случайных чисел и которым не требуется много времени для достижения справедливого выбора. Следовательно, у них нет ограничения в том, что «период консенсуса должен быть значительно больше времени синхронизации», и можно сразу перейти к большому размеру блока, как в решениях масштабирования POW. Среди известных проектов: Ouroboros, Snow White, Dfinity и Algorand.
Масштабирование BFT
Алгоритмы византийской отказоустойчивости (BFT) — это семейство алгоритмов консенсуса, которые могут допускать произвольное поведение ненадежных узлов, что позволяет честным узлам достигать консенсуса в ненадёжных сетях. Всё началось с задачи византийских генералов, предложенной Лесли Лэмпортом в начале 80-х. Однако из-за отсутствия «реальных» случаев применения практическая версия BFT появилась только в 1995 году и получила название «практической византийской отказоустойчивости» (PBFT).
PBFT — это алгоритм, имеющий сложность сообщения O(N²), как показано на следующем рисунке. N здесь — это общее число узлов проверки/майнинга в сети. На рисунке ниже показаны пять шагов в каждом раунде согласования (консенсуса), а стрелка представляет сообщение, отправляемого с одного узла на другой. Можно заметить, что для достижения консенсуса по одному сообщению это сообщение сперва должно быть передано всем узлам сети, а затем каждая нода (узел) должна оповестить каждую другую о сообщении.
Одним из главных недостатков PBFT является то, что он плохо масштабируется в зависимости от размера сети из-за сложности сообщения O(N²). Легко обнаружить, что количество сообщений, отправляемых между узлами для каждой транзакции, будет расти в квадрате относительно роста количества проверяющих сеть узлов. И поскольку пропускная способность может расти только пропорционально количеству узлов, пропускная способность будет уменьшаться по мере роста сети, и в принципе её нельзя будет использовать в сети с более чем, скажем, 50 узлами.
Для решения этой проблемы было предложено несколько идей, масштабирующих классические алгоритмы BFT. Первая попытка получила название спекулятивной (или предположительной) BFT. Идея очень проста: сперва узлы предполагают, что состояние сети хорошее и что среда доверенная, и используют более простые и эффективные схемы для достижения консенсуса. Если попытка в таком случае не удаётся, они переключаются обратно на более «дорогостоящий» PBFT. Это эквивалентно размену «худшей из задержек» на «лучшую из возможных пропускную способность». Отметим, что этот тип BFT на примере, допустим, Zyzzyva, существовал еще до концепции блокчейна. Поскольку проблема масштабируемости становится всё более и более важной, идея спекулятивной византийской отказоустойчивости была пересмотрена и принята на вооружение практиками и исследователями блокчейна для построения таких систем, как Byzcoin, Algorand и Thunderella.
Zyzzyva спекулятивно использует схему сложности сообщения O(N) для достижения консенсуса
Вторая идея заключается в намеренном удалении избыточности в процессе BFT за счёт использования информационно-теоретического инструмента — кодирования со стиранием. Он может повысить эффективность использования пропускной полосы. К примеру, Honeybadger-BFT попадает в эту категорию.
Третья идея состоит в том, чтобы ввести случайность в обмен данными между узлами таким образом, чтобы после получения сообщения, вместо того, чтобы слушать его от всех других пиров для подтверждения, каждый узел просто слушает случайно выбранные узлы и принимает соответствующие решения. Теоретически, узел примет правильное решение с высокой долей вероятности, если размер выборки будет выбран правильно и процесс выборки будет действительно случайным. Алгоритм консенсуса Avalanche использует эту идею для достижения лучшей масштабируемости.
Что лучше: масштабируемый POW (POS) или масштабируемая BFT
Хотя схемы масштабируемого POW (POS) и масштабируемой BFT, упомянутые выше, могут отличаться как по форме, так и по концепции, они могут иметь схожую производительность с точки зрения пропускной способности. В идеале оба подхода должны максимально использовать пропускную способность для передачи сообщений и обеспечивать беспрепятственную сложность сообщений O(N). 100-1000 транзакций в секунду (TPS) в сети с сотнями узлов (нод) будет грубым приближением пропускной способности масштабируемого POW (POS) или масштабируемой BFT. Другими словами, если вы видите термин «масштабируемый блокчейн», скорее всего, он будет относиться к двум этим типам «масштабируемости».
Направленные ациклические графы (DAG)
Многих удивит, что алгоритмы консенсуса на базе DAG также попадают в эту категорию, поскольку многие считают, что их вполне можно масштабировать горизонтально. Но факт заключается в том, что большинство DAG, независимо от того, являются они академическими предложениями по типу Phantom, Conflux или Avalanche, или промышленными проектами по типу IOTA и Hedera Hashgraph, они требуют, что все сообщения были известны каждому углу. Phantom, Conflux и IOTA можно рассматривать как усовершенствованные версии GHOST (масштабируемый POW), обеспечивающие лучшее распараллеливание консенсуса и синхронизацию. Avalanche и Hedera Hashgraph можно рассматривать как алгоритмы спекулятивной BFT, которые выдают высокую пропускную способность с менее строгими предположениями BFT.
Горизонтальные блокчейны (scale-out)
Эта концепция больше напоминает первоначальное определение «масштабируемого» в распределённых системах, в том смысле, что как масштабируемый горизонтально (scale-out) блокчейн, так и масштабируемая распределённая система с радостью предлагают более высокую пропускную способность по мере роста сети. Принципиальное различие между ними заключается в том, что масштабируемость в распределённых системах требует линейного роста производительности системы вместе с числом серверов (узлов), а это по сути является недостижимым для блокчейна по причине децентрализации.
И поэтому исследователи блокчейна стремились к более низкому уровню масштабируемости, чтобы пропускная способность сети росла сублинейно с увеличением размера сети. В результате получались схемы, которые сегодня называются «масштабируемыми горизонтально блокчейнами». Возможно, вы не слышали об этом самом горизонтальном масштабировании (scale-out), но наверняка слышали о «шардинге», Lightning Network и Ethereum Plasma. Их все можно рассматривать как горизонтальные подходы к решению вопроса масштабируемости блокчейна.
В масштабируемых горизонтально блокчейнах некоторые сообщения могут никогда не достичь некоторых узлов. Здесь под «узлами» мы подразумеваем тех, кто участвует и в валидации, и в консенсусе. В контексте Биткоина это будет означать, что майнеры не должны знать и подтверждать все транзакции. Серьёзным следствием такого параметра будет то, что растёт риск двойной траты, поскольку монеты, потраченные в транзакции, можно потратить снова в узлах, которые не знают об этой транзакции. Чтобы предотвратить двойные траты и, в то же время, сохранить параметр, нам понадобится, чтобы некоторые узлы в сети проверяли транзакции от лица других, что фактически возвращает определённый уровень централизации в систему. В результате под угрозой оказывается безопасность или децентрализация. Эту проблему называют «трилеммой масштабируемости блокчейна». Из-за трилеммы были споры о том, стоит ли нам вообще использовать горизонтальные схемы масштабирования.
Трилемма масштабируемости блокчейна
Как мы уже упомянули в некоторых схемах горизонтального масштабирования, есть две популярные стратегии разработки и реализации горизонтального блокчейна: одна — через шардинг и другая — через off-chain схемы, то есть такие, которые проводятся не на основном блокчейне.
Шардинг (sharding) — это разделение всей сети на подсети, «шарды» или сегменты, где узлы в каждой подсети используют локальный ledger, то есть книгу блоков. В идеале каждому узлу нужно знать, проверять и хранить сообщения, передаваемые только в пределах его собственного сегмента, а не все. Можно представить шардинг как разбиение исходного блокчейна на меньшие блокчейны, которые менее безопасны, так как меньше узлов проверяют транзакции и участвуют в консенсусе.
Таким образом, самые большие проблемы стратегии шардинга следующие: 1) как защитить каждый шард; 2) как шарды могли бы эффективно и безопасно взаимодействовать для обработки транзакций между шардами. Например, если какие-нибудь криптовалюты перемещаются из шарда А в шард Б, получатель в шарде Б должен запросить действительность валют у множества узлов из шарда А, чтобы не попасться на уловку злоумышленников. Для решения этих двух проблем предлагалось много решений, достаточно перечислить некоторые: Omniledger, Chainspace, Rchain, шардинг для Ethereum, распространяться о них мы будем в другой статье.
Схемы вне блокчейна (off-chain), внешние решения надстройки, в значительной степени базируются на идеях Lightning Network, которая использует некоторые хитрые приёмы для активации отдельного канала вне блокчейна между двумя узлами для быстрых переводов — без необходимости регистрировать каждую транзакцию между ними на блокчейне Bitcoin. Однако такое удобство сопряжено с некоторыми издержками, а именно: обе стороны должны заранее внести депозит на блокчейн, чтобы открыть оффчейн-канал между собой. С тех пор предлагалось множество подобных внеблокчейновых схем, предлагающих проведение быстрых платежей. В частности, сторонам позволяли взаимодействовать посредством других типов сообщений, например, транзакций с множеством сторон (multi-party transactions), транзакций условных платежей (conditional payment transactions) и транзакций на смарт-контрактах (smart contract transactions). Таким образом, остаётся лишь задача спроектировать и эффективно развернуть такие механизмы за пределами блокчейна с применением принудительных мер на блокчейне для различных типов сообщений. Из обсуждаемых проектов: Plasma, Polkadot, Liquidity.
Что лучше: шардинг или внеблокчейновые платежи?
Как ни странно, на деле довольно сложно определить разницу между шардингом и внеблокчейновой схемой. Некоторые схемы шардинга также могут включать основной блокчейн или общий консенсус среди всех сегментов, а некоторых схемы вне цепи могут также делить узлы на группы. Здесь различия будут больше теоретическими.
Фактически, термин «консенсус» состоит из двух свойств: согласованность (соглашение) и жизнеспособность (доступность). Первое означает, что два честных узла не должны иметь разногласий по поводу содержания сообщения. Последнее означает, что если честный узел знает сообщение, все остальные честные узлы в конечном счете тоже о нём узнают. Как для шардинга, так и для внеблокчейновых схем жизнеспособность оказывается скомпрометированной, поскольку о некоторых сообщениях узнают не все честные узлы. Разница между ними в том, как они достигают согласованности. В частности, шардинг гарантирует согласованность в шарде с определённым ухудшением безопасности. С другой стороны, решения вне цепи блоков не дают жёсткой гарантии согласованности. Вместо этого согласованность зависит от некоторого экономического принуждения, такого как депозит на основной цепи, и штрафного механизма, если кто-то ведёт себя плохо за пределами блокчейна.
VAPOR
Помимо шардингового и внеблокчейнового подходов, мы недавно предложили ещё одно решение для горизонтального масштабирования: VAPOR. Эта система основана на важном допущении под названием «рациональность», которое мы наблюдали на имеющихся системах блокчейна. В частности, мы находим, что большинство систем блокчейна рассматривают особый тип сообщений — транзакций, и большинство систем по умолчанию подразумевают, что участники блокчейна рациональны в отношении транзакций. К примеру, если Алиса рациональна и если она хочет что-то купить у Боба, после того, как она осуществит платежную транзакцию Бобу, ей нужно будет предоставить подлинность этой транзакции Бобу. И Боб, если он разумен и рационален, продаст свой товар только после того, как проверит, что сделка действительно подтверждена и подлинна. Мы называем это «рациональностью в передачи ценности». VAPOR использует «рациональность» в системе передачи ценности для масштабирования без ущерба для безопасности и децентрализации. Другими словами, VAPOR может использоваться в качестве полностью защищённой и децентрализованной системы ценностей, то есть в качестве криптовалюты, без необходимости каждого узла знать, подтверждать и хранить все транзакции. Однако у этой системы есть ограничение в функциональности, поскольку её можно использовать только для передачи ценности — в качестве «денег», чтобы допущение о «рациональности» соблюдалось.
Обсуждение
Мы надеемся, что теперь концепция масштабируемости блокчейна стала вам понятнее. Самое важное, что нужно из этого всего вынести: так называемый «масштабируемый блокчейн» ничего не скажет вам о его подлинной масштабирумости, если только его не сравнивают с Биткоином, POW Биткоина, классическим BFT или негоризонтальным блокчейном.
Критерии определения масштабируемости блокчейна
Весьма трудно судить о «масштабируемости» системы блокчейна без каких-либо теоретических знаний и опыта в этой области. Тем не менее, я думаю, что следующие три критерия могут быть использованы для оценки того, обладает ли конкретная блокчейн-система тремя типами масштабируемости, которые мы обсудили:
- Использует ли блокчейн POW Биткоина в качестве типа консенсуса? Если да, есть ли ограничение, что узлы всегда должны синхронизироваться с новейшими блоками, иначе их мощность майнинга будет потрачена впустую? Если да, это не масштабируемый POW.
- Использует ли блокчейн византийскую отказоустойчивость (BFT) в качестве типа консенсуса? Если да, есть ли какая-нибудь хитрая уловка, которая позволяет уменьшить сложность сообщения? Если нет, это не масштабируемая BFT.
- Нужно ли знать каждый кусочек сообщения каждому проверяющему узлу/майнеру? Узел в данном случае означает узлы, которые участвуют в консенсусе, то есть узлы, которые могут генерировать блоки — например, майнеры в контексте криптовалют. Если да, это не горизонтально масштабируемый блокчейн.
Так сколько транзакций в секунду может быть на блокчейне?
А теперь позвольте мне дать чуть более конкретное представление о масштабируемости с точки зрения TPS, проводимых транзакций в секунду. Как мы все знаем, если блокчейн не масштабируется горизонтально, каждый узел, участвующий в консенсусе, должен получить все сообщения. Следовательно, пропускная способность системы будет ограничена наименее способным узлом в сети. Следовательно, пропускная способность домашнего персонального компьютера, то есть 100-1000 TPS, будет вполне разумным ожиданием максимального уровня TPS, который может достичь полностью децентрализованный блокчейн. Другими словами, если не масштабируемый горизонтально блокчейн заявляет о пропускной способности в 10 тысяч TPS, это говорит о том, что система должна быть достаточно централизованной, поскольку узлы с меньшей пропускной способностью не смогут к ней присоединиться. С другой стороны, если блокчейн масштабируется горизонтально, его пропускная способность в теории не ограничена. Однако стоит остерегаться компромиссов между безопасностью, децентрализацией и функциональностью, поскольку невозможно одновременно угодить им всем.
Слой 1 или слой 2?
«Что будет лучшим решением для масштабирования блокчейна, слой 1 или слой 2?» — этот вопрос вызывает столько горячих споров, что мы не могли его не задать, обсуждая «масштабируемость». Однако мы не будем называть их конкретно, поскольку определение слою 1 и слою 2 (layer 1/layer 2), как таковое, не существует. Ограничимся кратким описанием.
В частности, layer 1 используется для представления всех усилий по масштабированию блокчейнов путем изменения существующих алгоритмов консенсуса или предложения новых алгоритмов консенсуса, которые включают все алгоритмы, описанные в этой статье, за исключением внеблокчейновых схем. Однако, как мы уже объяснили, их достижимая «масштабируемость» сильно разнится. С другой стороны, подходы layer 2 по большей части представлены внеблокчейновыми схемами. Будет неуместно сравнивать «слой 1» и «слой 2» с точки зрения масштабируемости, поскольку только одна категория «слоя 1», а именно шардинг, приближается к тому уровню «масштабируемости», что и «слой 2».
На сегодняшний день масштабируемость блокчейна остаётся открытой проблемой без идеального решения. Теоретически, все существующие схемы имеют свои плюсы и минусы и плохо масштабируются во всех ситуациях. Более того, безопасность некоторых схем либо не доказана, либо доказана при определённых теоретических условиях. Да что там говорить: ни одна масштабируемая схема, особенно обладающая строгими доказательствами безопасности, не была успешно реализована и протестирована в реальной жизни из-за трудностей реализации.
И поскольку масштабируемость как задача не решена даже близко, в будущем мы определённо увидим новые системы масштабируемых блокчейнов.
Не пропустите их, подписавшись на наш канал в Телеграме.
Избранное за все время —
Вот некоторые из любимых сообщений о HighScalability …
- Все статьи Интернета о масштабируемости.
- Объясни облако, как будто я 10
- Архитектура YouTube
- Веселое видео: реляционная база данных против NoSQL Fanbois
- Много рыбы Архитектура
- Программирование, управляемое машинным обучением: новое программирование для нового мира
- Джефф Дин о широкомасштабном глубоком обучении в Google
- Масштабирование Pinterest — от 0 до 10 миллиардов просмотров страниц в месяц за два года
- Архитектура Google
- Давайте построим города-производители для людей-производителей на основе новых ресурсов, таких как пропускная способность, вычислительные ресурсы и производство с атомарной точностью
- Секрет масштабирования: вы не можете линейно масштабировать усилия с учетом емкости
- Netflix: что происходит, когда вы нажимаете Play?
- Построение супер масштабируемых систем: Blade Runner встречает автономные вычисления в окружающем облаке
- : аргументы в пользу создания масштабируемых сервисов с отслеживанием состояния в современную эпоху
- Как Twitter хранит 250 миллионов твитов в день с использованием MySQL
- Масштабирование Twitter: делаем Twitter на 10000 процентов быстрее
- Архитектура WhatsApp Facebook купили за 19 миллиардов долларов
- Netflix: что происходит, когда вы нажимаете Play?
- Как в Amazon разрабатывается программное обеспечение?
- Как WhatsApp вырос почти до 500 миллионов пользователей, 11000 ядер и 70 миллионов сообщений в секунду
- Архитектура Flickr
- Руководство для начинающих по масштабированию до более 11 миллионов пользователей на Amazon AWS
- Как объяснить необоснованную эффективность ИТ?
- Мэтт Каттс: 10 уроков, извлеченных с первых дней существования Google
- Архитектура Amazon
- Джефф Дин о широкомасштабном глубоком обучении в Google
- Руководство для начинающих по масштабированию до более 11 миллионов пользователей на Amazon AWS
- Обновление StackOverflow: 560 млн просмотров страниц в месяц, 25 серверов, и все дело в производительности
- Oculus вызывает разлом, но сделка с Facebook позволит избежать кризиса масштабирования виртуальной реальности
- Как я научился перестать беспокоиться и полюбить Использование большого дискового пространства для масштабирования
- Архитектура переполнения стека
- Как PayPal увеличивал объемы ежедневных операций до миллиардов транзакций, используя всего 8 виртуальных машин
- Как Google выполняет проектирование планетарного масштаба для инфраструктуры планетарного масштаба?
- 7 лет уроков по масштабированию YouTube за 30 минут
- Как работает проверка безопасности Facebook
- Архитектура, которую Twitter использует для работы со 150 миллионами активных пользователей, 300 000 запросов в секунду, пожарным шлангом 22 МБ / с и отправкой твитов менее чем за 5 секунд
- Google о системах, устойчивых к задержкам: создание предсказуемого целого из непредсказуемых частей
- Неортодоксальный подход к проектированию баз данных: появление осколка
- Построение супер масштабируемых систем: Blade Runner встречает автономные вычисления в окружающем облаке
- Стартапы создают новую систему мира для ИТ
- Являются ли облачные архитектуры памяти следующим большим достижением?
- Задержка повсюду, и она стоит ваших продаж — как ее сократить
- Как мемристоры все изменят?
- 360-градусный вид всего стека Netflix Архитектура
- DataSift: анализ данных в реальном времени со скоростью 120000 твитов в секунду
- Полезные блоги о масштабируемости
- Обновление архитектуры Pinterest — 18 миллионов посетителей, 10-кратный рост, 12 сотрудников, 410 ТБ данных
- Масштабирование трафика: группа людей по запросу самоуправляемые роботизированные автомобили, которые автоматически заправляются от дешевых солнечных батарей
- Архитектура серверной части для социального продукта
- Почему моя слизистая плесень лучше, чем ваш кластер Hadoop
- VoltDB развеивает шесть городских мифов о SQL и в процессе реализует OLTP масштабируемого Интернета
- Каноническая облачная архитектура
- Как запрограммировать компьютер с 10 терабайтами ОЗУ?
- Джастин.Архитектура телевещания в прямом эфире
- Почему Facebook, Digg и Twitter так сложно масштабировать?
- Для чего, черт возьми, вы на самом деле используете NoSQL?
- Как Google изобрел удивительную сеть центров обработки данных, только они могли создать
- Архитектура социальных игр Playfish — 50 миллионов пользователей в месяц и рост
- Обновленный большой список статей об отключении Amazon
- Использование протоколов сплетен для обнаружения сбоев, мониторинга, обмена сообщениями и других полезных вещей
- Сага Etsy: от разрозненности до счастья — миллиарды просмотров страниц в месяц
- Как Twitter хранит 250 миллионов твитов в день с использованием MySQL
- Архитектура Tumblr — 15 миллиардов просмотров страниц в месяц и масштабировать сложнее, чем Twitter
- Не пора ли избавиться от модели ОС Linux в облаке?
- Состояние NoSQL в 2012 г.
- Ask HighScalability: решение проблем масштабирования с помощью новостных лент в Redis.Любой совет?
- Хронология Facebook: принесла вам сила денормализации
- Идеальная пятая часть замечаний по масштабируемости
- Архитектура ячеек
- Elements Of Scale: создание и масштабирование платформ данных
- Instagram улучшил производительность своего приложения. Вот как.
- Netflix: разработка, развертывание и поддержка программного обеспечения в соответствии с принципами облака
- Архитектура Instagram: 14 миллионов пользователей, терабайты фотографий, сотни экземпляров, десятки технологий
- Как мы можем построить более сложные сложные системы? Контейнеры, микросервисы и непрерывная доставка.
- Потрясающие масштабы AWS и его значение для будущего облака
- Архитектура Instagram Facebook купили за крутой миллиард долларов
- 10 вариаций шаблонов архитектуры ядра для достижения масштабируемости
- Обновления архитектуры StackExchange — бесперебойная работа, Amazon в 4 раза дороже
- Обеспечьте надежную неограниченную масштабируемость с помощью подвижной машины для пиршества
- Архитектура с тегами — масштабирование до 100 миллионов пользователей, 1000 серверов и 5 миллиардов просмотров страниц
- 17 методов масштабирования поворотного стола.FM и Labmeeting миллионам пользователей
- 5 ядов масштабируемости и 3 противоядия масштабируемости облаков
- Секрет масштабирования: вы не можете линейно масштабировать усилия с учетом емкости
- Обязательно посмотрите: 5 шагов к масштабированию MongoDB (или любой БД) за 8 минут
- Что изменения цен на Google App Engine говорят о будущем веб-архитектуры
- Три возраста Google — пакетная, складская, мгновенная
- Большой список 20 распространенных узких мест
- 10 секретов EBay для масштабирования планеты
- Обновление архитектуры Instagram: что нового в Instagram? Стратегия
- : запуск масштабируемого, доступного и дешевого статического сайта на S3 или GitHub
- Документ: Сеть Akamai — 61 000 серверов, 1000 сетей, 70 стран
- LevelDB — быстрая и легкая база данных ключей / значений от авторов MapReduce и BigTable
- Джим Старки создает новый дивный мир, переосмысливая базы данных для облака
- Архитектура Peecho — масштабируемость по доступной цене
- Google+ построен с использованием инструментов, которые вы тоже можете использовать: Closure, Java Servlets, JavaScript, BigTable, Colossus, Quick Turnaround
- Революция облачной архитектуры
- Секрет 10 миллионов одновременных подключений: ядро - проблема, а не решение
- В Redis решено 11 распространенных случаев использования Интернета
- Архитектура TripAdvisor — 40 млн посетителей, 200 млн динамических просмотров страниц, 30 ТБ данных
- 35+ вариантов использования для выбора следующей базы данных NoSQL
- 101 вопрос, который следует задать при рассмотрении базы данных NoSQL
- Удивительный список статей о продвинутых распределенных системах
- Переполнение стека делает медленные страницы в 100 раз быстрее с помощью простой настройки SQL
- Heroku Emergency Strategy: система управления инцидентами и 8-часовая ротация операций для Fresh Minds
- 6 способов не масштабировать, которые сделают вас модными, популярными и любимыми венчурными инвесторами
- Стратегия Империи ацтеков: используйте двойные трубы в акведуке для обеспечения высокой доступности
- Убил ли стек Microsoft MySpace?
- Новая система аналитики в реальном времени Facebook: HBase обрабатывает 20 миллиардов событий в день
- 6 уроков из Dropbox — один миллион файлов сохраняется каждые 15 минут
- Этому не учат, вы узнаете его по крупицам, решая каждую проблему.
- Станет ли Node.Js частью стека? SimpleGeo говорит, что да.
- Совет от Google Pro: используйте предварительные вычисления, чтобы выбрать лучший дизайн
- Netflix: постоянное тестирование отказавшими серверами с помощью Chaos Monkey
- 7 шаблонов проектирования для почти бесконечной масштабируемости
- Для чего, черт возьми, вы на самом деле используете NoSQL?
- Потрясающие масштабы AWS и его значение для будущего облака
- GPU против CPU Smackdown: рост архитектур, ориентированных на пропускную способность
- 8 широко используемых шаблонов проектирования масштабируемых систем
- Отличное вводное видео о масштабируемости от Harvard Computer Science
- Новая система обмена сообщениями Facebook в реальном времени: HBase будет хранить более 135 миллиардов сообщений в месяц
- Facebook со скоростью 13 миллионов запросов в секунду рекомендует: минимизировать дисперсию запросов
- Machine VM + Cloud API — переписывание облака с нуля
- 10 золотых принципов создания успешных мобильных / веб-приложений
- Проблемы с Sharding — чему мы можем научиться из инцидента с Foursquare?
- Google Colossus выполняет поиск в режиме реального времени, выгружая MapReduce
- 6 способов убить ваши серверы — научиться масштабировать на сложном уровне
- Misco: платформа MapReduce для мобильных систем — начало окружающего облака?
- Масштабирование инфраструктуры AWS — инструменты и шаблоны
- Vertical Scaling Ascendant — как твердотельные накопители меняют архитектуру?
- Подумайте о задержке как о псевдопостоянном разделе сети
- 7 стратегий масштабирования, которые Facebook использовал для роста до 500 миллионов пользователей
- Как мы можем стимулировать движение исследований из башни из слоновой кости в производство?
- Подсчет больших данных: как подсчитать миллиард различных объектов, используя только 1.5 КБ памяти
- Google: укрощение длинного хвоста задержки — когда больше машин дает худшие результаты
- Программирование с просьбой о прощении — или как мы запрограммируем 1000 ядер
- Грейс Хоппер — программистам: помните о наносекундах!
- Анатомия технологии поиска: база данных NoSQL Blekko
- Анатомия поисковых технологий: сканирование с использованием комбинаторов
- C для вычислений — Google Compute Engine (GCE)
- Неортодоксальный подход к проектированию баз данных: появление осколка
- 10 золотых принципов создания успешных мобильных / веб-приложений
- Производительность распределенных структур данных, работающих в «согласованной с кешем» сетке данных в памяти
- Архитектура MemSQL — Быстрая (MVCC, InMem, LockFree, CodeGen) и знакомая (SQL)
- Призматическая архитектура — использование машинного обучения в социальных сетях для определения того, что следует читать в Интернете
- Изменение архитектуры: новые сети центров обработки данных сделают ваш код и данные свободными
- Архитектура MemSQL — Быстрая (MVCC, InMem, LockFree, CodeGen) и знакомая (SQL)
- Призматическая архитектура — использование машинного обучения в социальных сетях для определения того, что следует читать в Интернете
- Скрытая история: последний пик трансконтинентальной железной дороги был ранней версией Интернета вещей
- Ваш генератор нагрузки, вероятно, лжет вам — примите красную таблетку и узнайте, почему
- Чему нас научит удивительная гонка на Южный полюс о стартапах?
- Если вы программируете сотовый телефон как сервер, вы делаете это неправильно
- Vertical Scaling Ascendant — как твердотельные накопители меняют архитектуру?
- 10 золотых принципов создания успешных мобильных / веб-приложений
- Умные способы, которыми Chrome скрывает задержку, предугадывая все ваши потребности
- Эпическое обновление TripAdvisor: почему бы не работать в облаке? Великий эксперимент.
- Самое удивительное открытие Google Spanner: NoSQL отсутствует, а NewSQL находится на стадии
- Рецепт 10 ингредиентов Русса для производства 1 миллиона транзакций в секунду на оборудовании стоимостью 5 тысяч долларов
- Sharding The Hibernate Way
- Мать всех дебатов о нормализации базы данных о Coding Horror
- Постоянно записывать все
- Секрет масштабирования №2: денормализация вашего пути к скорости и прибыли Стратегия
- : масштабирование по диагонали — не забудьте масштабировать и увеличивать
- Документ: о разработке и развертывании служб Интернет-масштаба Стратегия
- : три метода преодоления скачков трафика за счет быстрого масштабирования вашего сайта
- ZooKeeper — надежная масштабируемая распределенная система координации
- GridGain: одна вычислительная сеть, множество сетей данных
- Масштабирование искоренения спама с помощью целенаправленных игр: Die Spammer Die!
- Google AppEngine — второй взгляд
- Облачное программирование напрямую направляет распределение затрат на разработку программного обеспечения
- Бумага: конец архитектурной эры (время для полного переписывания)
- В какой-то момент стоимость серверов превышает затраты на программистов
- Бросьте КИСЛОТУ и подумайте о данных
- Как добиться успеха в планировании мощностей, не прилагая особых усилий: интервью с Джоном Олспоу из Flickr о его новой книге
- Десять уроков первого года работы GitHub в 2008 году
- Как Google обслуживает данные из нескольких центров обработки данных
- Стратегия: разбейте кучу собак Memcache
- Построение масштабируемых систем с использованием данных в качестве составного материала
- MySQL и Memcached: конец эпохи?
- Семь признаков, что вам может понадобиться база данных NoSQL
- 7 уроков, извлеченных при создании Reddit до 270 миллионов просмотров страниц в месяц
- Как мы можем стимулировать движение исследований из башни из слоновой кости в производство?
- 6 способов убить ваши серверы — научиться масштабировать на сложном уровне
- Machine VM + Cloud API — переписывание облака с нуля
- Heroku Emergency Strategy: система управления инцидентами и 8-часовая ротация операций для Fresh Minds
- 6 способов не масштабировать, которые сделают вас модными, популярными и любимыми венчурными инвесторами
- Google+ построен с использованием инструментов, которые вы тоже можете использовать: Closure, Java Servlets, JavaScript, BigTable, Colossus, Quick Turnaround
- Шесть горьких уроков о масштабировании системы на миллион пользователей
- 20 крупнейших узких мест Шона Халла, которые снижают и замедляют масштабируемость
- Как Twitter хранит 250 миллионов твитов в день с использованием MySQL
- Устойчивость — это новая норма — глубокий взгляд на то, что это значит, и как ее реализовать
- Переключите базы данных на флэш-память.Теперь. Или вы делаете это неправильно.
- Ask HS: как будут выглядеть программирование и архитектура в 2020 году?
- Обеспечение отказоустойчивости будет таким 2013
- Pinterest сокращает расходы с 54 до 20 долларов в час за счет автоматического отключения систем
- Правила Роберта Скобла для успешного масштабирования стартапов
- Что, если бы машины арендовали, как мы нанимаем программистов?
- Как Facebook делает мобильную работу в масштабе для всех телефонов, на всех экранах и во всех сетях
- Четыре мета-секрета масштабирования в Facebook
- Facebook со скоростью 13 миллионов запросов в секунду рекомендует: минимизировать дисперсию запросов
- Google: укрощение длинного хвоста задержки — когда больше машин дает худшие результаты
- Стратегия Google: древовидное распределение запросов и ответов
- AppBackplane — платформа для поддержки нескольких архитектур приложений
- Меняющееся лицо масштаба — обратная сторона масштабирования в эпоху контекста
- Помимо потоков и обратных вызовов — плюсы и минусы архитектуры приложения
- 42 проблемы с монстрами, которые атакуют по мере увеличения нагрузки
- Когда вся программа представляет собой график — Библиотека сантехники Prismatic
- Лучшее кеширование браузера важнее, чем отсутствие JavaScript или быстрые сети для производительности HTTP
- Архитектура DuckDuckGo — 1 миллион глубоких поисков в день и растет
- Больше чисел, которые должен знать каждый опытный программист
- Чему нас научит удивительная гонка на Южный полюс о стартапах?
- 100 уроков без проклятия от Гордона Рамзи по созданию отличного программного обеспечения
- Как создать сотую культуру разработки программного обеспечения обезьяны?
- Использование облачных вычислений в Yelp — 102 миллиона посетителей в месяц и 39 миллионов отзывов
- Разрушая 4 современных мифа об оборудовании — действительно ли память, жесткие и твердотельные диски — произвольный доступ?
- 10 смертных грехов против масштабируемости
- Это не моя проблема — я их сдам
- 100 уроков без проклятия от Гордона Рамзи по созданию отличного программного обеспечения Архитектура
- Salesforce — как они справляются 1.3 миллиарда транзакций в день
- Масштабируемый почтовый ящик — от 0 до одного миллиона пользователей за 6 недель и 100 миллионов сообщений в день
- Архитектура Cinchcast — производство 1500 часов аудио каждый день
- Архитектура StubHub: удивительная сложность крупнейшего в мире рынка билетов
- IDoneThis — масштабирование почтового приложения с нуля
- Архитектура ESPN в масштабе — работа со скоростью 100 000 единиц в секунду
- Одна история жизни, рассказанная в очередях
- Как на самом деле пакетные запросы могут сократить задержку?
- Как Google поддерживает Интернет вместе с эксабайтами других данных
- 10 вещей, за которыми Bitly следовало следить
- Как Next Big Sound отслеживает более триллиона воспроизведений, лайков и многого другого с помощью системы контроля версий для данных Hadoop
- Как бы вы построили следующий Интернет? Гагары, дроны, вертолеты, спутники или что-то еще?
- 8 способов, которыми Stardog сделал свою базу данных безумно масштабируемой
- Архитектура NYTimes: нет головы, нет мастера, нет единой точки отказа
- Под Сноуденом Light Выбор архитектуры программного обеспечения становится мрачным
- Как HipChat сохраняет и индексирует миллиарды сообщений с помощью ElasticSearch и Redis
- То, что происходит, пока ваш мозг спит, удивительно похоже на то, как компьютеры остаются в здравом уме
- 22 рекомендации по созданию эффективного веб-программного обеспечения с высоким трафиком
- Как на самом деле пакетные запросы могут сократить задержку?
- Развитие архитектуры Bazaarvoice до 500 миллионов уникальных пользователей в месяц
- Одна история жизни, рассказанная в очередях
- Скрытая история: последний пик трансконтинентальной железной дороги был ранней версией Интернета вещей
- Мы наконец-то решили проблему 10K — на этот раз для управления серверами с серверами 2000x, управляемыми с помощью системного администратора
- Google утверждает, что цены на облачные услуги будут соответствовать закону Мура: все ли мы сейчас арендаторы?
- 10 вещей, которые следует знать об AWS
- Масштабируемый компьютер FireBox Warehouse в 2020 году будет иметь 1 тыс. Сокетов, 100 тыс. Ядер, 100 Пбайт NV RAM и сеть 4 Пб / с.
- Архитектура ESPN в масштабе — работа со скоростью 100 000 дух-ню-с в секунду
- Санджай Гемават из Google О том, что сделало Google Google и большой карьерный совет в области больших данных
- Закон Литтла, масштабируемость и отказоустойчивость: ОС — ваше узкое место.Что ты можешь сделать?
- Как Google поддерживает Интернет вместе с эксабайтами других данных
- Вычислительные архитектуры планетарного масштаба для электронной торговли и как алгоритмы формируют наш мир
- Документ: специализация сетевого стека для повышения производительности
- Как архитектура AOL.Com выросла до 99,999% доступности, 8 миллионов посетителей в день и 200 000 запросов в секунду
- 5 советов по масштабированию баз данных NoSQL: не доверяйте предположениям
- Закон Литтла, масштабируемость и отказоустойчивость: ОС — ваше узкое место.Что ты можешь сделать?
- Вот 1300-летнее решение повышения устойчивости — восстановление, восстановление, восстановление
- Вот почему Microsoft выиграла. И почему они проиграли.
- микросервисов — не бесплатный обед! Обновление
- на Disqus: все еще о реальном времени, но Go уничтожает Python
- 10 ошибок кэширования при блокировке программ
- Bitly: извлеченные уроки по созданию распределенной системы, обрабатывающей 6 миллиардов кликов в месяц
- 9 принципов высокоэффективных программ
- Как Twitter использует Redis для масштабирования — 105 ТБ ОЗУ, 39 млн запросов в секунду, более 10 000 экземпляров
- Все правильно: взгляд на централизованные и децентрализованные системы глазами мгновенного воспроизведения
- 10 стандартных настроек сервера для вашего веб-приложения
- Стратегия: измените проблему
- Давайте построим города-производители для людей-производителей на основе новых ресурсов, таких как пропускная способность, вычислительные ресурсы и производство с атомарной точностью
- Простой способ создания растущей архитектуры стартапа с использованием HAProxy, PHP, Redis и MySQL для обработки 1 миллиарда запросов в неделю
- Великие микросервисы против монолитных приложений Twitter Melee
- Обновление StackOverflow: 560 млн просмотров страниц в месяц, 25 серверов, и все дело в производительности
- Секрет масштабирования: вы не можете линейно масштабировать усилия с учетом емкости
- 10 стандартных настроек сервера для вашего веб-приложения
- Все сотрудники должны быть ограничены только их способностями, а не отсутствием ресурсов
- Большая проблема — это средние данные
- The Machine: новый масштабируемый компьютер HP на базе мемристоров для центров обработки данных — все еще меняет
- Сделайте любую платформу менее отстойной с помощью этих 10 проницательных уроков
- Мы оставляем на столе производительность в 3–4 раза только из-за конфигурации
- Aeron: действительно ли нам нужна еще одна система обмена сообщениями?
- Facebook Mobile Drops Pull For Push-Based Snapshot + Delta Model
- Как League Of Legends увеличила чат до 70 миллионов игроков — для этого нужно много миньонов
- Это не моя проблема — я их сдам
- Instagram улучшил производительность своего приложения.Вот как
- Спасение аутсорсингового проекта от краха: 8 обнаруженных проблем и 8 извлеченных уроков Архитектура
- Vinted: поддержание стабильности загруженного портала за счет развертывания нескольких сотен раз в день
- Мэтт Каттс: 10 уроков, извлеченных с первых дней существования Google
- Бумага: неизменность меняет все Пэт Хелланд
- Учитесь на моей боли — 5 уроков из приключений Элло в быстром масштабировании
- Полное руководство: 5 методов отладки производственных серверов в масштабе
- Фон Нейман дал нам один совет: ничего не создавать.
- Линус: «Будущее за параллельными вычислениями» — пустяк.
- Масштабируемость как услуга Документ
- : управление крупномасштабным кластером в Google с помощью Borg
- Большая проблема — это средние данные
- Многопоточное программирование действительно стало для собак
- The Machine: новый масштабируемый компьютер HP на базе мемристоров для центров обработки данных — все еще меняет
- Все сотрудники должны быть ограничены только их способностями, а не отсутствием ресурсов.
- Архитектура Auth0 — работа в нескольких облачных провайдерах и регионах
- Сделайте любую платформу менее отстойной с помощью этих 10 проницательных уроков
- Черная магия систематического снижения джиттера ОС Linux
- 6 способов победить приближающуюся армию роботов
- Как мы масштабируем серверные системы VividCortex
- Семь самых отвратительных антипаттернов в микросервисах
- HappyPancake: ретроспектива построения простого и масштабируемого фундамента
- Конвергенция, которая меняет все: гравитация данных + контейнеры + микросервисы
- AppLovin: маркетинг для мобильных потребителей по всему миру путем обработки 30 миллиардов запросов в день
- Масштабирование Ким Кардашьян до 100 миллионов просмотров страниц
- Спасение аутсорсингового проекта от краха: 8 обнаруженных проблем и 8 извлеченных уроков Архитектура
- Vinted: поддержание стабильности загруженного портала за счет развертывания нескольких сотен раз в день
- Как отладка похожа на поиск серийных убийц
- Дорога ярости Алголии к мировому API, часть 3
- Архитектура серверной части для социального продукта
- Это.Просто. Этот.
- 64 Сеть, что можно и нельзя делать для игровых движков. Часть IIIa: на стороне сервера
- Почему моя капля воды лучше, чем ваш кластер Hadoop
- Как Autodesk реализовал масштабируемую обработку событий на Mesos
- Хотите IoT? Вот как крупная коммунальная компания США собирает данные об электроэнергии с более чем 5,5 миллионов счетчиков
- Как Uber масштабирует свою рыночную платформу реального времени
- Стимуляторы торговли и очень старая идея повышения вовлеченности пользователей
- Создание глобально распределенных критически важных приложений: уроки из окопов, часть 2
- 7 стратегий для 10-кратных преобразований
- Спросите о высокой масштабируемости: выберите асинхронный сервер приложений или несколько серверов блокировки?
- Как Facebook сообщает вашим друзьям, что вы в безопасности в случае бедствия менее чем за пять минут
- Как новые технологии памяти повлияют на базы данных в памяти?
- Uber идет нестандартно: использование телефонов с драйверами в качестве резервного центра обработки данных
- 5 уроков и 8 изменений в отрасли за 5 лет в качестве технического директора Etsy
- Как Uber масштабирует свою рыночную платформу реального времени
- Как весы Shopify для обработки флэш-продаж от Канье Уэста и Суперкубка
- Какие идеи в IT должны умереть?
- 5 уроков за 5 лет создания Instagram Сегмент
- : восстановление инфраструктуры с помощью Docker, ECS и Terraform
- Глубокие уроки от Google и EBay по построению экосистем микросервисов
- Как влияет использование задержки Docker?
- Бессерверный запуск — долой серверы!
- Злоба, глупость или невнимательность? Использование обзоров кода для поиска бэкдоров
- Переход Google от единого центра обработки данных к отказоустойчивому к собственной многосетевой архитектуре
- Как создать интеграцию вашей системы управления недвижимостью с использованием микросервисов
- Пожертвуем наши органы и неиспользуемые облачные циклы науке
- уроков, извлеченных из масштабирования Uber до 2000 инженеров, 1000 сервисов и 8000 репозиториев Git
- Как Uber управляет миллионом операций записи в секунду, используя Mesos и Cassandra в нескольких центрах обработки данных
- Архитектура клуба для бритья за доллар Unilever купила за 1 миллиард долларов
- Генерация кода: внутреннее святилище производительности базы данных
- Беспощадная история внедрения защиты от спама для почты.Электронная почта Ru Group и при чем тут Tarantool
- Архитектура Always On — выход за рамки традиционного аварийного восстановления
- Как Facebook транслирует прямые трансляции для 800000 одновременных зрителей
- Как Twitter обрабатывает 3000 изображений в секунду
- Гигантская экономика нарушает социальное обеспечение
- Путешествие по тому, как Zapier автоматизирует миллиарды задач автоматизации рабочих процессов
- Облачное программирование напрямую направляет распределение затрат на разработку программного обеспечения
- Что изменения цен на Google App Engine говорят о будущем веб-архитектуры
- Совет от Google Pro: используйте предварительные вычисления, чтобы выбрать лучший дизайн
- Стратегия Google: древовидное распределение запросов и ответов
- Этому не учат, вы узнаете его по крупицам, решая каждую проблему. Стратегия
- : резервное копирование на диск для скорости, резервное копирование на ленту для сохранения бекона, просто спросите у Google
- Три возраста Google — пакетная, складская, мгновенная
- Подсчет больших данных: как подсчитать миллиард различных объектов, используя всего 1,5 КБ памяти
- Результаты поиска Google: централизованное управление, распределенные архитектуры данных работают лучше, чем полностью децентрализованные архитектуры
- Facebook: пример канонической архитектуры для масштабирования миллиардов сообщений
- Каноническая облачная архитектура
- Как я научился перестать беспокоиться и полюбить, используя много дискового пространства для масштабирования
- Руководство для начинающих по масштабированию до более 11 миллионов пользователей на Amazon AWS
- уроков, извлеченных из масштабирования Uber до 2000 инженеров, 1000 сервисов и 8000 репозиториев Git
- Великие микросервисы против монолитных приложений Twitter Melee
- Джастин.Архитектура телевещания в прямом эфире
- Вечная экономия на внутреннем спотовом рынке Netflix
- Во что вы верите сейчас, если не делали этого пять лет назад? Централизованные победы. Децентрализованные убытки.
- Как бы вы построили следующий Интернет? Гагары, дроны, вертолеты, спутники или что-то еще?
- Программирование, управляемое машинным обучением: новое программирование для нового мира
- Архитектура Always On — выход за рамки традиционного аварийного восстановления
- Как вы объясните необоснованную эффективность облачной безопасности?
- Как Google выполняет проектирование планетарного масштаба для инфраструктуры планетарного масштаба?
- Стратегия: разбейте кучу собак Memcache
- Стратегия Google и Netflix: используйте частичные ответы для уменьшения размера запросов
- Вот 1300-летнее решение повышения устойчивости — восстановление, восстановление, восстановление
- Архитектура Tumblr, которую Yahoo купила за крутой миллиард долларов
Сообщений, обучающих основам
Всего сообщений —
заявок по категориям
Щелкните категорию ниже, чтобы просмотреть список всех записей в этой категории.
записей по неделям
Щелкните неделю ниже, чтобы просмотреть список статей, опубликованных в течение этой недели.
- 1 августа 2021 г. — 7 августа 2021 г. (1)
- 11 июля 2021 г. — 17 июля 2021 г. (1)
- 27 июня 2021 г. — 3 июля 2021 г. (1)
- 20 июня 2021 г. — июнь 26, 2021 (1)
- 6 июня 2021 — 12 июня 2021 (2)
- 16 мая 2021 — 22 мая 2021 (1)
- 25 апреля 2021 — 1 мая 2021 (1)
- 4 апреля 2021 г. — 10 апреля 2021 г. (1)
- 14 марта 2021 г. — 20 марта 2021 г. (2)
- 7 марта 2021 г. — 13 марта 2021 г. (1)
- 14 февраля 2021 г. — 20 февраля 2021 (3)
- 31 января 2021 — 6 февраля 2021 (2)
- 24 января 2021 — 30 января 2021 (1)
- 3 января 2021 — 9 января 2021 (1)
- 20 декабря , 2020 — 26 декабря 2020 (2)
- 13 декабря 2020 — 19 декабря 2020 (1)
- 6 декабря 2020 — 12 декабря 2020 (1)
- 22 ноября 2020 — 28 ноября 2020 ( 1)
- 8 ноября 2020 г. — 14 ноября 2020 г. (1)
- 1 ноября 2020 г. — 7 ноября 2020 г. (2)
- 11 октября 2020 г. — 17 октября 2020 г. (1)
- 27 сентября 2020 г. — 3 октября 2020 г. (1)
- 20 сентября 2020 г. — 26 сентября , 2020 (2)
- 13 сентября 2020 г. — 19 сентября 2020 г. (3)
- 30 августа 2020 г. — 5 сентября 2020 г. (2)
- 2 августа 2020 г. — 8 августа 2020 г. (1)
- июль 26 июня 2020 г. — 1 августа 2020 г. (1)
- 5 июля 2020 г. — 11 июля 2020 г. (1)
- 21 июня 2020 г. — 27 июня 2020 г. (1)
- 14 июня 2020 г. — 20 июня 2020 г. (1)
- 7 июня 2020 г. — 13 июня 2020 г. (1)
- 24 мая 2020 г. — 30 мая 2020 г. (1)
- 10 мая 2020 г. — 16 мая 2020 г. (4)
- 3 мая, 2020 — 9 мая 2020 г. (1)
- 26 апреля 2020 г. — 2 мая 2020 г. (2)
- 12 апреля 2020 г. — 18 апреля 2020 г. (2)
- 5 апреля 2020 г. — 11 апреля 2020 г. (2 )
- 29 марта 2020 г. — 4 апреля 2020 г. (1)
- 22 марта 2020 г. — Марк h 28, 2020 (2)
- 15 марта 2020 — 21 марта 2020 (1)
- 8 марта 2020 — 14 марта 2020 (1)
- 1 марта 2020 — 7 марта 2020 (1)
- 23 февраля 2020 г. — 29 февраля 2020 г. (2)
- 16 февраля 2020 г. — 22 февраля 2020 г. (3)
- 9 февраля 2020 г. — 15 февраля 2020 г. (2)
- 2 февраля 2020 г. — 8 февраля , 2020 (2)
- 19 января 2020 г. — 25 января 2020 г. (3)
- 5 января 2020 г. — 11 января 2020 г. (3)
- 8 декабря 2019 г. — 14 декабря 2019 г. (1)
- декабря 1 — 7 декабря 2019 г. (1)
- 24 ноября 2019 г. — 30 ноября 2019 г. (1)
- 10 ноября 2019 г. — 16 ноября 2019 г. (2)
- 27 октября 2019 г. — 2 ноября 2019 г. (3)
- 20 октября 2019 г. — 26 октября 2019 г. (1)
- 13 октября 2019 г. — 19 октября 2019 г. (2)
- 6 октября 2019 г. — 12 октября 2019 г. (1)
- 29 сентября, 2019-5 октября 2019 (3) 9 0006
- 22 сентября 2019 — 28 сентября 2019 (1)
- 15 сентября 2019 — 21 сентября 2019 (3)
- 1 сентября 2019 — 7 сентября 2019 (3)
- 18 августа 2019 — август 24, 2019 (2)
- 11 августа 2019 — 17 августа 2019 (1)
- 4 августа 2019 — 10 августа 2019 (1)
- 28 июля 2019 — 3 августа 2019 (1)
- 21 июля 2019 г. — 27 июля 2019 г. (1)
- 14 июля 2019 г. — 20 июля 2019 г. (2)
- 7 июля 2019 г. — 13 июля 2019 г. (1)
- 23 июня 2019 г. — 29 июня 2019 (2)
- 2 июня 2019 г. — 8 июня 2019 г. (1)
- 12 мая 2019 г. — 18 мая 2019 г. (2)
- 5 мая 2019 г. — 11 мая 2019 г. (1)
- 28 апреля , 2019 — 4 мая 2019 (1)
- 21 апреля 2019 — 27 апреля 2019 (1)
- 14 апреля 2019 — 20 апреля 2019 (3)
- 7 апреля 2019 — 13 апреля 2019 ( 3)
- 31 марта 2019 г. — 6 апреля 2019 г. (2)
- 24 марта 2019 г. — М arch 30, 2019 (1)
- 17 марта 2019 — 23 марта 2019 (2)
- 10 марта 2019 — 16 марта 2019 (1)
- 3 марта 2019 — 9 марта 2019 (4)
- 24 февраля 2019 г. — 2 марта 2019 г. (3)
- 17 февраля 2019 г. — 23 февраля 2019 г. (3)
- 10 февраля 2019 г. — 16 февраля 2019 г. (1)
- 3 февраля 2019 г. — 9 февраля , 2019 (3)
- 27 января 2019 — 2 февраля 2019 (2)
- 20 января 2019 — 26 января 2019 (1)
- 13 января 2019 — 19 января 2019 (2)
- января 6 декабря 2019 г. — 12 января 2019 г. (3)
- 30 декабря 2018 г. — 5 января 2019 г. (2)
- 16 декабря 2018 г. — 22 декабря 2018 г. (2)
- 9 декабря 2018 г. — 15 декабря 2018 г. (2)
- 2 декабря 2018 г. — 8 декабря 2018 г. (3)
- 25 ноября 2018 г. — 1 декабря 2018 г. (1)
- 18 ноября 2018 г. — 24 ноября 2018 г. (1)
- 11 ноября 2018 г. 2018 — 17 ноября 2018 ( 3)
- 4 ноября 2018 г. — 10 ноября 2018 г. (2)
- 28 октября 2018 г. — 3 ноября 2018 г. (2)
- 21 октября 2018 г. — 27 октября 2018 г. (1)
- 14 октября 2018 г. — 20 октября 2018 г. (1)
- 7 октября 2018 г. — 13 октября 2018 г. (1)
- 30 сентября 2018 г. — 6 октября 2018 г. (2)
- 23 сентября 2018 г. — 29 сентября 2018 г. (1)
- 16 сентября 2018 г. — 22 сентября 2018 г. (3)
- 9 сентября 2018 г. — 15 сентября 2018 г. (2)
- 2 сентября 2018 г. — 8 сентября 2018 г. (3)
- 26 августа 2018 г. — сентябрь 1, 2018 (2)
- 19 августа 2018 — 25 августа 2018 (3)
- 12 августа 2018 — 18 августа 2018 (2)
- 5 августа 2018 — 11 августа 2018 (3)
- 29 июля 2018 г. — 4 августа 2018 г. (1)
- 22 июля 2018 г. — 28 июля 2018 г. (2)
- 15 июля 2018 г. — 21 июля 2018 г. (1)
- 8 июля 2018 г. — 14 июля, 2018 (2)
- 1, 2 июля 018 — 7 июля 2018 г. (2)
- 24 июня 2018 г. — 30 июня 2018 г. (1)
- 17 июня 2018 г. — 23 июня 2018 г. (3)
- 10 июня 2018 г. — 16 июня 2018 г. (1) )
- 3 июня 2018 г. — 9 июня 2018 г. (2)
- 29 апреля 2018 г. — 5 мая 2018 г. (1)
- 22 апреля 2018 г. — 28 апреля 2018 г. (5)
- 15 апреля 2018 г. — 21 апреля 2018 г. (2)
- 8 апреля 2018 г. — 14 апреля 2018 г. (3)
- 1 апреля 2018 г. — 7 апреля 2018 г. (3)
- 25 марта 2018 г. — 31 марта 2018 г. (2)
- 11 марта 2018 — 17 марта 2018 (2)
- 4 марта 2018 — 10 марта 2018 (1)
- 25 февраля 2018 — 3 марта 2018 (2)
- 18 февраля 2018 — 24 февраля , 2018 (2)
- 11 февраля 2018 — 17 февраля 2018 (2)
- 4 февраля 2018 — 10 февраля 2018 (1)
- 28 января 2018 — 3 февраля 2018 (4)
- января 14, 2018 — 20 января, 2018 (3)
- 7 января 2018 — 13 января 2018 (2)
- 31 декабря 2017 г. — 6 января 2018 г. (1)
- 17 декабря 2017 г. — 23 декабря 2017 г. (1)
- 10 декабря 2017 г. — 16 декабря 2017 г. (2)
- 3 декабря, 2017 — 9 декабря 2017 г. (3)
- 26 ноября 2017 — 2 декабря 2017 г. (1)
- 19 ноября 2017 — 25 ноября 2017 г. (1)
- 12 ноября 2017 г. — 18 ноября 2017 г. (2 )
- 5 ноября 2017 г. — 11 ноября 2017 г. (3)
- 29 октября 2017 г. — 4 ноября 2017 г. (1)
- 22 октября 2017 г. — 28 октября 2017 г. (4)
- 15 октября 2017 г. — 21 октября 2017 г. (2)
- 8 октября 2017 г. — 14 октября 2017 г. (3)
- 1 октября 2017 г. — 7 октября 2017 г. (2)
- 24 сентября 2017 г. — 30 сентября 2017 г. (4)
- 17 сентября 2017 г. — 23 сентября 2017 г. (2)
- 10 сентября 2017 г. — 16 сентября 2017 г. (3)
- 3 сентября 2017 г. — 9 сентября 2017 г. (1)
- 27 августа 2017 г. — сентябрь 2 сентября 2017 г. (2)
- 20 августа 2017 г. — 26 августа 2017 г. (1)
- 13 августа 2017 г. — 19 августа 2017 г. (3)
- 30 июля 2017 г. — 5 августа 2017 г. (3)
- 23 июля 2017 г. — 29 июля 2017 г. (2)
- 16 июля 2017 г. — 22 июля 2017 г. (2)
- 9 июля 2017 г. — 15 июля 2017 г. (2)
- 2 июля 2017 г. — 8 июля , 2017 (2)
- 28 мая 2017 г. — 3 июня 2017 г. (1)
- 21 мая 2017 г. — 27 мая 2017 г. (2)
- 14 мая 2017 г. — 20 мая 2017 г. (2)
- мая 7, 2017 — 13 мая 2017 (3)
- 30 апреля 2017 — 6 мая 2017 (3)
- 23 апреля 2017 — 29 апреля 2017 (2)
- 16 апреля 2017 — 22 апреля 2017 (1)
- 9 апреля 2017 г. — 15 апреля 2017 г. (3)
- 2 апреля 2017 г. — 8 апреля 2017 г. (1)
- 26 марта 2017 г. — 1 апреля 2017 г. (4)
- 19 марта, г. 2017 — 25 марта 2017 (1)
- 12 марта 2017 — 18 марта 2017 (3)
- 5 марта 2017 — 11 марта 2017 ( 2)
- 26 февраля 2017 г. — 4 марта 2017 г. (4)
- 19 февраля 2017 г. — 25 февраля 2017 г. (3)
- 12 февраля 2017 г. — 18 февраля 2017 г. (2)
- 5 февраля 2017 г. — 11 февраля 2017 г. (3)
- 29 января 2017 г. — 4 февраля 2017 г. (4)
- 22 января 2017 г. — 28 января 2017 г. (2)
- 15 января 2017 г. — 21 января 2017 г. (3)
- 8 января 2017 — 14 января 2017 (1)
- 1 января 2017 — 7 января 2017 (4)
- 18 декабря 2016 — 24 декабря 2016 (3)
- 11 декабря 2016 — декабрь 17, 2016 (3)
- 4 декабря 2016 — 10 декабря 2016 (3)
- 27 ноября 2016 — 3 декабря 2016 (2)
- 20 ноября 2016 — 26 ноября 2016 (3)
- 13 ноября 2016 — 19 ноября 2016 (3)
- 6 ноября 2016 — 12 ноября 2016 (3)
- 16 октября 2016 — 22 октября 2016 (3)
- 9 октября 2016 — 15 октября, 2016 ( 3)
- 2 октября 2016 г. — 8 октября 2016 г. (1)
- 25 сентября 2016 г. — 1 октября 2016 г. (3)
- 18 сентября 2016 г. — 24 сентября 2016 г. (1)
- 11 сентября 2016 г. — 17 сентября 2016 г. (4)
- 4 сентября 2016 г. — 10 сентября 2016 г. (2)
- 28 августа 2016 г. — 3 сентября 2016 г. (4)
- 21 августа 2016 г. — 27 августа 2016 г. (2)
- 14 августа 2016 — 20 августа 2016 (3)
- 7 августа 2016 — 13 августа 2016 (2)
- 31 июля 2016 — 6 августа 2016 (4)
- 24 июля 2016 — июль 30, 2016 (2)
- 17 июля 2016 — 23 июля 2016 (4)
- 10 июля 2016 — 16 июля 2016 (3)
- 3 июля 2016 — 9 июля 2016 (3)
- 26 июня 2016 — 2 июля 2016 (3)
- 19 июня 2016 — 25 июня 2016 (2)
- 12 июня 2016 — 18 июня 2016 (3)
- 8 мая 2016 — 14 мая, 2016 (2)
- 1 мая 2016 г. — 7 мая 2016 г. (2)
- апр. ил 24, 2016 — 30 апреля, 2016 (5)
- 17 апреля 2016 — 23 апреля, 2016 (3)
- 10 апреля 2016 — 16 апреля 2016 (4)
- 3 апреля 2016 — 9 апреля, 2016 (2)
- 27 марта 2016 — 2 апреля 2016 (4)
- 20 марта 2016 — 26 марта 2016 (3)
- 13 марта 2016 — 19 марта 2016 (4)
- 6 марта , 2016 — 12 марта 2016 (3)
- 28 февраля 2016 — 5 марта 2016 (6)
- 21 февраля 2016 — 27 февраля 2016 (3)
- 14 февраля 2016 — 20 февраля 2016 ( 3)
- 7 февраля 2016 г. — 13 февраля 2016 г. (4)
- 31 января 2016 г. — 6 февраля 2016 г. (5)
- 24 января 2016 г. — 30 января 2016 г. (3)
- 17 января 2016 г. — 23 января 2016 г. (5)
- 10 января 2016 г. — 16 января 2016 г. (4)
- 3 января 2016 г. — 9 января 2016 г. (4)
- 27 декабря 2015 г. — 2 января 2016 г. (3)
- 13 декабря 2015 — 19 декабря 2015 (3)
- 6 декабря 2015 г. — 12 декабря 2015 г. (4)
- 29 ноября 2015 г. — 5 декабря 2015 г. (2)
- 22 ноября 2015 г. — 28 ноября 2015 г. (3)
- 15 ноября 2015 г. — 21 ноября , 2015 (3)
- 8 ноября 2015 — 14 ноября 2015 (4)
- 1 ноября 2015 — 7 ноября 2015 (4)
- 25 октября 2015 — 31 октября 2015 (4)
- октябрь 18, 2015 — 24 октября 2015 (3)
- 11 октября 2015 — 17 октября 2015 (5)
- 4 октября 2015 — 10 октября 2015 (3)
- 27 сентября 2015 — 3 октября 2015 (4)
- 20 сентября 2015 г. — 26 сентября 2015 г. (3)
- 13 сентября 2015 г. — 19 сентября 2015 г. (4)
- 6 сентября 2015 г. — 12 сентября 2015 г. (3)
- 30 августа, 2015 — 5 сентября 2015 (5)
- 23 августа 2015 — 29 августа 2015 (3)
- 16 августа 2015 — 22 августа 2015 (4)
- 9 августа 2015 — 15 августа 2015 (3 )
- 2 августа 2015 — 8 августа 2015 (4)
- 26 июля 2015 — 1 августа 2015 (4)
- 19 июля 2015 — 25 июля 2015 (4)
- 12 июля 2015 — 18 июля , 2015 (5)
- 5 июля 2015 — 11 июля 2015 (4)
- 14 июня 2015 — 20 июня 2015 (1)
- 7 июня 2015 — 13 июня 2015 (3)
- май 31 мая 2015 г. — 6 июня 2015 г. (5)
- 24 мая 2015 г. — 30 мая 2015 г. (4)
- 17 мая 2015 г. — 23 мая 2015 г. (4)
- 10 мая 2015 г. — 16 мая 2015 г. (4)
- 3 мая 2015 г. — 9 мая 2015 г. (3)
- 26 апреля 2015 г. — 2 мая 2015 г. (4)
- 12 апреля 2015 г. — 18 апреля 2015 г. (5)
- 5 апреля, г. 2015 — 11 апреля 2015 (3)
- 29 марта 2015 — 4 апреля 2015 (4)
- 22 марта 2015 — 28 марта 2015 (3)
- 15 марта 2015 — 21 марта 2015 (4 )
- 8 марта 2015 — 14 марта 2015 (5)
- 1 марта 2015 — 7 марта 2015 (3)
- 22 февраля, 2015 — 28 февраля 2015 г. (3)
- 15 февраля 2015 г. — 21 февраля 2015 г. (4)
- 8 февраля 2015 г. — 14 февраля 2015 г. (3)
- 1 февраля 2015 г. — 7 февраля 2015 г. (4 )
- 25 января 2015 — 31 января 2015 (3)
- 18 января 2015 — 24 января 2015 (4)
- 11 января 2015 — 17 января 2015 (3)
- 4 января 2015 — 10 января 2015 г. (4)
- 28 декабря 2014 г. — 3 января 2015 г. (2)
- 21 декабря 2014 г. — 27 декабря 2014 г. (2)
- 14 декабря 2014 г. — 20 декабря 2014 г. (5)
- 7 декабря 2014 — 13 декабря 2014 (4)
- 30 ноября 2014 — 6 декабря 2014 (3)
- 23 ноября 2014 — 29 ноября 2014 (3)
- 16 ноября 2014 — 22 ноября , 2014 (3)
- 9 ноября 2014 — 15 ноября 2014 (4)
- 2 ноября 2014 — 8 ноября 2014 (3)
- 26 октября 2014 — 1 ноября 2014 (3)
- октябрь19, 2014 — 25 октября 2014 (3)
- 12 октября 2014 — 18 октября 2014 (4)
- 5 октября 2014 — 11 октября 2014 (3)
- 28 сентября 2014 — 4 октября 2014 (3)
- 21 сентября 2014 г. — 27 сентября 2014 г. (3)
- 14 сентября 2014 г. — 20 сентября 2014 г. (4)
- 7 сентября 2014 г. — 13 сентября 2014 г. (3)
- 31 августа, 2014 г. — 6 сентября 2014 г. (4)
- 24 августа 2014 г. — 30 августа 2014 г. (3)
- 17 августа 2014 г. — 23 августа 2014 г. (4)
- 10 августа 2014 г. — 16 августа 2014 г. (3 )
- 3 августа 2014 г. — 9 августа 2014 г. (4)
- 27 июля 2014 г. — 2 августа 2014 г. (4)
- 20 июля 2014 г. — 26 июля 2014 г. (3)
- 13 июля 2014 г. — 19 июля 2014 г. (3)
- 6 июля 2014 г. — 12 июля 2014 г. (4)
- 29 июня 2014 г. — 5 июля 2014 г. (3)
- 22 июня 2014 г. — 28 июня 2014 г. (3)
- 15 июня 2014 г. — 21 июня 2014 г. (1)
- июнь 8, 2014 — 14 июня 2014 г. (1)
- 1 июня 2014 г. — 7 июня 2014 г. (1)
- 25 мая 2014 г. — 31 мая 2014 г. (1)
- 18 мая 2014 г. — 24 мая 2014 г. (4)
- 11 мая 2014 г. — 17 мая 2014 г. (5)
- 4 мая 2014 г. — 10 мая 2014 г. (3)
- 27 апреля 2014 г. — 3 мая 2014 г. (5)
- 20 апреля 2014 г. 2014 г. — 26 апреля 2014 г. (3)
- 13 апреля 2014 г. — 19 апреля 2014 г. (4)
- 6 апреля 2014 г. — 12 апреля 2014 г. (4)
- 30 марта 2014 г. — 5 апреля 2014 г. (5 )
- 23 марта 2014 г. — 29 марта 2014 г. (4)
- 16 марта 2014 г. — 22 марта 2014 г. (5)
- 9 марта 2014 г. — 15 марта 2014 г. (5)
- 2 марта 2014 г. — 8 марта 2014 г. (4)
- 23 февраля 2014 г. — 1 марта 2014 г. (3)
- 16 февраля 2014 г. — 22 февраля 2014 г. (4)
- 9 февраля 2014 г. — 15 февраля 2014 г. (4)
- 2 февраля 2014 г. — 8 февраля 2014 г. (4)
- 26 января 2014 г. — 1 февраля 2014 г. (3) 90 005 19 января 2014 г. — 25 января 2014 г. (4)
- 12 января 2014 г. — 18 января 2014 г. (5)
- 5 января 2014 г. — 11 января 2014 г. (4)
- 29 декабря 2013 г. — 4 января , 2014 (3)
- 22 декабря 2013 — 28 декабря 2013 (2)
- 15 декабря 2013 — 21 декабря 2013 (3)
- 8 декабря 2013 — 14 декабря 2013 (5)
- декабря 1, 2013 — 7 декабря 2013 г. (3)
- 24 ноября 2013 г. — 30 ноября 2013 г. (4)
- 17 ноября 2013 г. — 23 ноября 2013 г. (3)
- 10 ноября 2013 г. — 16 ноября 2013 г. (4)
- 3 ноября 2013 г. — 9 ноября 2013 г. (4)
- 27 октября 2013 г. — 2 ноября 2013 г. (4)
- 20 октября 2013 г. — 26 октября 2013 г. (3)
- 13 октября 2013 г. 2013 — 19 октября 2013 г. (4)
- 6 октября 2013 г. — 12 октября 2013 г. (3)
- 29 сентября 2013 г. — 5 октября 2013 г. (4)
- 22 сентября 2013 г. — 28 сентября 2013 г. (3 )
- 15 сентября 2013 г. — 21 сентября 2013 г. (4)
- 8 сентября 2013 г. — 14 сентября 2013 г. (3)
- 1 сентября 2013 г. — 7 сентября 2013 г. (4)
- 25 августа 2013 г. — 31 августа , 2013 (3)
- 18 августа 2013 — 24 августа 2013 (4)
- 11 августа 2013 — 17 августа 2013 (3)
- 4 августа 2013 — 10 августа 2013 (3)
- июль 21, 2013 — 27 июля 2013 г. (2)
- 14 июля 2013 г. — 20 июля 2013 г. (4)
- 7 июля 2013 г. — 13 июля 2013 г. (3)
- 30 июня 2013 г. — 6 июля 2013 г. (3)
- 23 июня 2013 г. — 29 июня 2013 г. (5)
- 16 июня 2013 г. — 22 июня 2013 г. (3)
- 9 июня 2013 г. — 15 июня 2013 г. (4)
- 2 июня, г. 2013 г. — 8 июня 2013 г. (4)
- 26 мая 2013 г. — 1 июня 2013 г. (4)
- 19 мая 2013 г. — 25 мая 2013 г. (4)
- 12 мая 2013 г. — 18 мая 2013 г. (5 )
- 5 мая 2013 г. — 11 мая 2013 г. (4)
- 28 апреля 2013 г. — 4 мая 2013 г. (4)
- 21 апреля 2013 г. — 27 апреля 2013 г. (4)
- 14 апреля 2013 г. — 20 апреля 2013 г. (4)
- 7 апреля 2013 г. — 13 апреля 2013 г. (3)
- 31 марта 2013 г. — апрель 6, 2013 (5)
- 24 марта 2013 г. — 30 марта 2013 г. (3)
- 17 марта 2013 г. — 23 марта 2013 г. (4)
- 10 марта 2013 г. — 16 марта 2013 г. (4)
- 3 марта 2013 г. — 9 марта 2013 г. (6)
- 24 февраля 2013 г. — 2 марта 2013 г. (3)
- 17 февраля 2013 г. — 23 февраля 2013 г. (4)
- 10 февраля 2013 г. — 16 февраля, 2013 (4)
- 3 февраля 2013 г. — 9 февраля 2013 г. (6)
- 27 января 2013 г. — 2 февраля 2013 г. (3)
- 20 января 2013 г. — 26 января 2013 г. (5)
- 13 января , 2013 — 19 января 2013 (4)
- 6 января 2013 — 12 января 2013 (4)
- 30 декабря 2012 — 5 января 2013 (3)
- 23 декабря 2012 — 29 декабря 2012 ( 3)
- 16 декабря 2012 г. — декабрь 22, 2012 (3)
- 9 декабря 2012 г. — 15 декабря 2012 г. (4)
- 2 декабря 2012 г. — 8 декабря 2012 г. (3)
- 25 ноября 2012 г. — 1 декабря 2012 г. (4)
- 18 ноября 2012 г. — 24 ноября 2012 г. (2)
- 11 ноября 2012 г. — 17 ноября 2012 г. (3)
- 4 ноября 2012 г. — 10 ноября 2012 г. (3)
- 28 октября 2012 г. — 3 ноября, 2012 (5)
- 21 октября 2012 г. — 27 октября 2012 г. (4)
- 14 октября 2012 г. — 20 октября 2012 г. (5)
- 7 октября 2012 г. — 13 октября 2012 г. (5)
- 30 сентября , 2012 — 6 октября 2012 г. (4)
- 23 сентября 2012 г. — 29 сентября 2012 г. (3)
- 16 сентября 2012 г. — 22 сентября 2012 г. (4)
- 9 сентября 2012 г. — 15 сентября 2012 г. ( 5)
- 2 сентября 2012 г. — 8 сентября 2012 г. (3)
- 26 августа 2012 г. — 1 сентября 2012 г. (4)
- 19 августа 2012 г. — 25 августа 2012 г. (5)
- 12 августа 2012 г. — 18 августа 2012 г. (4)
- 5 августа 2012 г. — 11 августа 2012 г. (5)
- 29 июля 2012 г. — 4 августа 2012 г. (5)
- 22 июля 2012 г. — 28 июля 2012 г. (5)
- 15 июля 2012 г. — 21 июля 2012 г. (4)
- 8 июля 2012 г. — 14 июля 2012 г. (5)
- 1 июля 2012 г. — 7 июля 2012 г. (4)
- 24 июня 2012 г. — 30 июня , 2012 (4)
- 17 июня 2012 г. — 23 июня 2012 г. (5)
- 10 июня 2012 г. — 16 июня 2012 г. (4)
- 3 июня 2012 г. — 9 июня 2012 г. (6)
- май 27, 2012 — 2 июня 2012 г. (3)
- 20 мая 2012 г. — 26 мая 2012 г. (5)
- 13 мая 2012 г. — 19 мая 2012 г. (3)
- 6 мая 2012 г. — 12 мая 2012 г. (5)
- 29 апреля 2012 г. — 5 мая 2012 г. (4)
- 22 апреля 2012 г. — 28 апреля 2012 г. (4)
- 15 апреля 2012 г. — 21 апреля 2012 г. (4)
- 8 апреля, г. 2012 — 14 апреля 2012 г. (4)
- 1 апреля 2012 г. — 7 апреля 2012 г. (4)
- 25 марта 2012 г. — 31 марта 2012 г. (5) 9000 6
- 18 марта 2012 г. — 24 марта 2012 г. (4)
- 11 марта 2012 г. — 17 марта 2012 г. (4)
- 4 марта 2012 г. — 10 марта 2012 г. (3)
- 26 февраля 2012 г. — март 3, 2012 (5)
- 19 февраля 2012 г. — 25 февраля 2012 г. (3)
- 12 февраля 2012 г. — 18 февраля 2012 г. (5)
- 5 февраля 2012 г. — 11 февраля 2012 г. (3)
- 29 января 2012 г. — 4 февраля 2012 г. (5)
- 22 января 2012 г. — 28 января 2012 г. (4)
- 15 января 2012 г. — 21 января 2012 г. (4)
- 8 января 2012 г. — 14 января 2012 (4)
- 1 января 2012 г. — 7 января 2012 г. (4)
- 25 декабря 2011 г. — 31 декабря 2011 г. (3)
- 18 декабря 2011 г. — 24 декабря 2011 г. (5)
- 11 декабря , 2011 — 17 декабря 2011 г. (4)
- 4 декабря 2011 г. — 10 декабря 2011 г. (4)
- 27 ноября 2011 г. — 3 декабря 2011 г. (3)
- 20 ноября 2011 г. — 26 ноября 2011 г. ( 2)
- Нет 13 ноября 2011 г. — 19 ноября 2011 г. (4)
- 6 ноября 2011 г. — 12 ноября 2011 г. (4)
- 30 октября 2011 г. — 5 ноября 2011 г. (4)
- 23 октября 2011 г. — 29 октября 2011 (4)
- 9 октября 2011 г. — 15 октября 2011 г. (1)
- 25 сентября 2011 г. — 1 октября 2011 г. (6)
- 18 сентября 2011 г. — 24 сентября 2011 г. (6)
- 11 сентября , 2011 — 17 сентября 2011 (4)
- 4 сентября 2011 — 10 сентября 2011 (4)
- 28 августа 2011 — 3 сентября 2011 (3)
- 21 августа 2011 — 27 августа 2011 ( 5)
- 14 августа 2011 г. — 20 августа 2011 г. (4)
- 7 августа 2011 г. — 13 августа 2011 г. (4)
- 31 июля 2011 г. — 6 августа 2011 г. (4)
- 24 июля 2011 г. — 30 июля 2011 г. (5)
- 17 июля 2011 г. — 23 июля 2011 г. (4)
- 10 июля 2011 г. — 16 июля 2011 г. (4)
- 3 июля 2011 г. — 9 июля 2011 г. (4)
- 26 июня 2011 г. — 2 июля 2011 г. (5) 900 06
- 19 июня 2011 г. — 25 июня 2011 г. (4)
- 12 июня 2011 г. — 18 июня 2011 г. (6)
- 5 июня 2011 г. — 11 июня 2011 г. (5)
- 29 мая 2011 г. — июнь 4, 2011 (4)
- 22 мая 2011 г. — 28 мая 2011 г. (3)
- 15 мая 2011 г. — 21 мая 2011 г. (5)
- 8 мая 2011 г. — 14 мая 2011 г. (4)
- 1 мая 2011 г. — 7 мая 2011 г. (5)
- 24 апреля 2011 г. — 30 апреля 2011 г. (3)
- 17 апреля 2011 г. — 23 апреля 2011 г. (3)
- 10 апреля 2011 г. — 16 апреля, 2011 (6)
- 3 апреля 2011 г. — 9 апреля 2011 г. (4)
- 27 марта 2011 г. — 2 апреля 2011 г. (4)
- 20 марта 2011 г. — 26 марта 2011 г. (4)
- 13 марта , 2011 — 19 марта 2011 (5)
- 6 марта 2011 — 12 марта 2011 (3)
- 27 февраля 2011 — 5 марта 2011 (4)
- 20 февраля 2011 — 26 февраля 2011 ( 3)
- 13 февраля 2011 г. — 19 февраля 2011 г. (4)
- 6 февраля 2011 г. — 12 февраля 2011 г. (4 )
- 30 января 2011 г. — 5 февраля 2011 г. (4)
- 23 января 2011 г. — 29 января 2011 г. (3)
- 16 января 2011 г. — 22 января 2011 г. (4)
- 9 января 2011 г. — 15 января 2011 г. (3)
- 2 января 2011 г. — 8 января 2011 г. (4)
- 26 декабря 2010 г. — 1 января 2011 г. (3)
- 19 декабря 2010 г. — 25 декабря 2010 г. (4)
- 12 декабря 2010 г. — 18 декабря 2010 г. (3)
- 5 декабря 2010 г. — 11 декабря 2010 г. (3)
- 28 ноября 2010 г. — 4 декабря 2010 г. (5)
- 21 ноября 2010 г. — 27 ноября , 2010 (3)
- 14 ноября 2010 г. — 20 ноября 2010 г. (5)
- 7 ноября 2010 г. — 13 ноября 2010 г. (5)
- 31 октября 2010 г. — 6 ноября 2010 г. (3)
- октябрь 24 октября 2010 г. — 30 октября 2010 г. (7)
- 17 октября 2010 г. — 23 октября 2010 г. (5)
- 10 октября 2010 г. — 16 октября 2010 г. (3)
- 3 октября 2010 г. — 9 октября 2010 г. (4) 90 006
- 26 сентября 2010 г. — 2 октября 2010 г. (6)
- 19 сентября 2010 г. — 25 сентября 2010 г. (4)
- 12 сентября 2010 г. — 18 сентября 2010 г. (3)
- 5 сентября 2010 г. — сентябрь 11, 2010 (6)
- 29 августа 2010 г. — 4 сентября 2010 г. (6)
- 22 августа 2010 г. — 28 августа 2010 г. (5)
- 15 августа 2010 г. — 21 августа 2010 г. (3)
- 8 августа 2010 г. — 14 августа 2010 г. (6)
- 1 августа 2010 г. — 7 августа 2010 г. (5)
- 25 июля 2010 г. — 31 июля 2010 г. (5)
- 18 июля 2010 г. — 24 июля, 2010 (4)
- 11 июля 2010 г. — 17 июля 2010 г. (6)
- 4 июля 2010 г. — 10 июля 2010 г. (3)
- 27 июня 2010 г. — 3 июля 2010 г. (3)
- 20 июня , 2010 — 26 июня 2010 г. (4)
- 13 июня 2010 г. — 19 июня 2010 г. (4)
- 6 июня 2010 г. — 12 июня 2010 г. (4)
- 30 мая 2010 г. — 5 июня 2010 г. ( 5)
- 23 мая 2010 г. — 29 мая 2010 г. (2)
- 16 мая, г. 2010 — 22 мая 2010 г. (2)
- 9 мая 2010 г. — 15 мая 2010 г. (3)
- 2 мая 2010 г. — 8 мая 2010 г. (5)
- 25 апреля 2010 г. — 1 мая 2010 г. (5 )
- 18 апреля 2010 г. — 24 апреля 2010 г. (3)
- 11 апреля 2010 г. — 17 апреля 2010 г. (4)
- 4 апреля 2010 г. — 10 апреля 2010 г. (5)
- 28 марта 2010 г. — 3 апреля 2010 г. (2)
- 21 марта 2010 г. — 27 марта 2010 г. (3)
- 14 марта 2010 г. — 20 марта 2010 г. (3)
- 7 марта 2010 г. — 13 марта 2010 г. (5)
- 28 февраля 2010 г. — 6 марта 2010 г. (4)
- 21 февраля 2010 г. — 27 февраля 2010 г. (5)
- 14 февраля 2010 г. — 20 февраля 2010 г. (4)
- 7 февраля 2010 г. — 13 февраля , 2010 (3)
- 31 января 2010 г. — 6 февраля 2010 г. (6)
- 24 января 2010 г. — 30 января 2010 г. (4)
- 17 января 2010 г. — 23 января 2010 г. (3)
- января 10, 2010 — 16 января 2010 г. (3)
- 3 января 2010 г. — январь 9, 2010 (1)
- 27 декабря 2009 г. — 2 января 2010 г. (2)
- 20 декабря 2009 г. — 26 декабря 2009 г. (2)
- 13 декабря 2009 г. — 19 декабря 2009 г. (4)
- 29 ноября 2009 г. — 5 декабря 2009 г. (1)
- 22 ноября 2009 г. — 28 ноября 2009 г. (5)
- 15 ноября 2009 г. — 21 ноября 2009 г. (2)
- 8 ноября 2009 г. — 14 ноября, г. 2009 (2)
- 1 ноября 2009 г. — 7 ноября 2009 г. (4)
- 25 октября 2009 г. — 31 октября 2009 г. (8)
- 18 октября 2009 г. — 24 октября 2009 г. (3)
- 11 октября , 2009 — 17 октября 2009 г. (4)
- 4 октября 2009 г. — 10 октября 2009 г. (5)
- 27 сентября 2009 г. — 3 октября 2009 г. (3)
- 20 сентября 2009 г. — 26 сентября 2009 г. ( 2)
- 13 сентября 2009 г. — 19 сентября 2009 г. (6)
- 6 сентября 2009 г. — 12 сентября 2009 г. (9)
- 30 августа 2009 г. — 5 сентября 2009 г. (5)
- 23 августа 2009 г.- 29 августа 2009 г. (3)
- 16 августа 2009 г. — 22 августа 2009 г. (6)
- 9 августа 2009 г. — 15 августа 2009 г. (4)
- 2 августа 2009 г. — 8 августа 2009 г. (8)
- 26 июля 2009 г. — 1 августа 2009 г. (7)
- 19 июля 2009 г. — 25 июля 2009 г. (3)
- 12 июля 2009 г. — 18 июля 2009 г. (4)
- 5 июля 2009 г. — июль 11, 2009 (3)
- 28 июня 2009 г. — 4 июля 2009 г. (12)
- 21 июня 2009 г. — 27 июня 2009 г. (5)
- 14 июня 2009 г. — 20 июня 2009 г. (6)
- 7 июня 2009 г. — 13 июня 2009 г. (7)
- 31 мая 2009 г. — 6 июня 2009 г. (11)
- 24 мая 2009 г. — 30 мая 2009 г. (5)
- 17 мая 2009 г. — 23 мая, г. 2009 (5)
- 10 мая 2009 г. — 16 мая 2009 г. (5)
- 3 мая 2009 г. — 9 мая 2009 г. (8)
- 26 апреля 2009 г. — 2 мая 2009 г. (7)
- 19 апреля , 2009 — 25 апреля 2009 г. (7)
- 12 апреля 2009 г. — 18 апреля 2009 г. (9)
- 5 апреля 2009 г. — 11 апреля 2009 г. ( 9)
- 29 марта 2009 г. — 4 апреля 2009 г. (6)
- 22 марта 2009 г. — 28 марта 2009 г. (3)
- 15 марта 2009 г. — 21 марта 2009 г. (9)
- 8 марта 2009 г. — 14 марта 2009 г. (9)
- 1 марта 2009 г. — 7 марта 2009 г. (5)
- 22 февраля 2009 г. — 28 февраля 2009 г. (6)
- 15 февраля 2009 г. — 21 февраля 2009 г. (5)
- 8 февраля 2009 г. — 14 февраля 2009 г. (3)
- 1 февраля 2009 г. — 7 февраля 2009 г. (5)
- 25 января 2009 г. — 31 января 2009 г. (4)
- 18 января 2009 г. — январь 24, 2009 (4)
- January 11, 2009 — January 17, 2009 (8)
- January 4, 2009 — January 10, 2009 (7)
- December 28, 2008 — January 3, 2009 (6)
- December 21, 2008 — December 27, 2008 (2)
- December 14, 2008 — December 20, 2008 (9)
- December 7, 2008 — December 13, 2008 (2)
- November 30, 2008 — December 6, 2008 (12)
- Novem ber 23, 2008 — November 29, 2008 (2)
- November 16, 2008 — November 22, 2008 (3)
- November 9, 2008 — November 15, 2008 (7)
- November 2, 2008 — November 8, 2008 (3)
- October 26, 2008 — November 1, 2008 (6)
- October 19, 2008 — October 25, 2008 (7)
- October 12, 2008 — October 18, 2008 (15)
- October 5, 2008 — October 11, 2008 (7)
- September 28, 2008 — October 4, 2008 (5)
- September 21, 2008 — September 27, 2008 (11)
- September 14, 2008 — September 20, 2008 (2)
- September 7, 2008 — September 13, 2008 (3)
- August 31, 2008 — September 6, 2008 (6)
- August 24, 2008 — August 30, 2008 (4)
- August 17, 2008 — August 23, 2008 (5)
- August 10, 2008 — August 16, 2008 (4)
- August 3, 2008 — August 9, 2008 (2)
- July 27, 2008 — August 2, 2008 (1)
- July 20, 200 8 — July 26, 2008 (6)
- July 13, 2008 — July 19, 2008 (3)
- July 6, 2008 — July 12, 2008 (3)
- June 22, 2008 — June 28, 2008 (1)
- June 8, 2008 — June 14, 2008 (4)
- June 1, 2008 — June 7, 2008 (4)
- May 25, 2008 — May 31, 2008 (13)
- May 18, 2008 — May 24, 2008 (3)
- May 11, 2008 — May 17, 2008 (4)
- May 4, 2008 — May 10, 2008 (3)
- April 27, 2008 — May 3, 2008 (5)
- April 20, 2008 — April 26, 2008 (5)
- April 13, 2008 — April 19, 2008 (2)
- April 6, 2008 — April 12, 2008 (5)
- March 30, 2008 — April 5, 2008 (6)
- March 23, 2008 — March 29, 2008 (5)
- March 16, 2008 — March 22, 2008 (10)
- March 9, 2008 — March 15, 2008 (4)
- March 2, 2008 — March 8, 2008 (9)
- February 24, 2008 — March 1, 2008 (6)
- February 17, 2008 — February 23, 2008 (8)
- February 10, 2008 — February 16, 2008 (6)
- February 3, 2008 — February 9, 2008 (8)
- January 27, 2008 — February 2, 2008 (12)
- January 20, 2008 — January 26, 2008 (5)
- January 13, 2008 — January 19, 2008 (9)
- January 6, 2008 — January 12, 2008 (8)
- December 30, 2007 — January 5, 2008 (6)
- December 23, 2007 — December 29, 2007 (5)
- December 16, 2007 — December 22, 2007 (3)
- December 9, 2007 — December 15, 2007 (10)
- December 2, 2007 — December 8, 2007 (8)
- November 25, 2007 — December 1, 2007 (5)
- November 18, 2007 — November 24, 2007 (6)
- November 11, 2007 — November 17, 2007 (12)
- November 4, 2007 — November 10, 2007 (7)
- October 28, 2007 — November 3, 2007 (5)
- October 21, 2007 — October 27, 2007 (8)
- October 14, 2007 — Oct ober 20, 2007 (7)
- October 7, 2007 — October 13, 2007 (8)
- September 30, 2007 — October 6, 2007 (9)
- September 23, 2007 — September 29, 2007 (5)
- September 16, 2007 — September 22, 2007 (6)
- September 9, 2007 — September 15, 2007 (8)
- September 2, 2007 — September 8, 2007 (6)
- August 26, 2007 — September 1, 2007 (5)
- August 19, 2007 — August 25, 2007 (7)
- August 12, 2007 — August 18, 2007 (3)
- August 5, 2007 — August 11, 2007 (5)
- July 29, 2007 — August 4, 2007 (22)
- July 22, 2007 — July 28, 2007 (18)
- July 15, 2007 — July 21, 2007 (12)
- July 8, 2007 — July 14, 2007 (7)
- July 1, 2007 — July 7, 2007 (1)
Entries by Month
Click on a month below to view a list of articles published during that month.
Начните здесь — Высокая масштабируемость —
Эта страница поможет вам начать работу с высокой масштабируемостью. Вот несколько полезных тем, которые помогут вам начать работу …
- Почему существует сайт с высокой масштабируемостью?
- Полезные вещи для чтения.
- Участвуйте, добавляя собственные ссылки на интересные сайты и статьи.
- Участвуйте, подписавшись на RSS-канал.
- Рассмотрите множество преимуществ регистрации в качестве пользователя.
- Как мне получать уведомления об изменениях содержания и комментариев?
- Contact Высокая масштабируемость.
- Об.
Почему существует сайт с высокой масштабируемостью?
Чтобы помочь вам создавать успешные масштабируемые веб-сайты.
Этот сайт пытается собрать воедино все знания, искусство, науку, практику и опыт создания масштабируемых веб-сайтов в одном месте, чтобы вы могли научиться уверенно создавать свой веб-сайт.
Когда становится ясно, что вы должны развивать свой сайт или умереть, большинство людей понятия не имеют, с чего начать.Это не тот навык, которому вы научитесь в школе или почерпнете из журнальной статьи, когда летите домой на самолете. Нет, создание масштабируемых систем — это совокупность знаний, медленно накапливаемых с течением времени из с трудом добытого опыта и множества неудачных сражений. Надеюсь, этот сайт продвинет вас дальше и быстрее по кривой успеха.
Создатели популярных веб-сайтов в конечном итоге сталкиваются с важным вопросом: как мне масштабировать? Каждый создатель успешных веб-сайтов должен ответить на этот вопрос и применить свои ответы на практике.
Вы можете спросить:
- Как мне справиться с тем, что меня копают или косят?
- На что я могу потратить свой бюджет?
- Как мне добавлять новых и новых пользователей?
- Какое программное обеспечение мне следует использовать? LAMP, WAMP или .Net?
- Следует использовать управляемые или неуправляемые системы? Выделенный, совмещенный, VPS, хостинг или что-то еще?
- Какую машину и операционную систему мне следует использовать?
- Как мне восстановиться после аварии?
- Как мне измерить и улучшить производительность?
- Где мне получить помощь?
- Какой центр обработки данных мне использовать?
- Какого провайдера мне следует использовать?
- Как я могу структурировать свое программное обеспечение для масштабирования?
- Как настроить кеширование?
- Как должна выглядеть моя схема базы данных?
- Какую базу данных мне использовать?
- Какой язык и фреймворк мне следует использовать?
- Как я могу гарантировать, что мои данные всегда доступны и никогда не потеряны?
- Как мне контролировать все мое программное обеспечение и машины?
- Как мне обучить моих программистов созданию программного обеспечения такого типа?
- Как выполнить аварийное переключение веб-серверов, баз данных и т. Д.?
- Как мне перейти в несколько географических регионов?
- Как мне обрабатывать данные сеанса?
- Как мне обеспечить поддержку, обновления и развертывание функций?
У вас наверняка тысячи таких вопросов.Где найти ответы? Ответы есть. Как создать масштабируемый сайт — не секрет, информация просто разложена. И это все же больше искусство, чем наука. Все проблемы разные. У вашего сайта могут быть особые требования, которые делают его достаточно разным, чтобы вы могли воспользоваться советом.
И вот о чем весь этот сайт. Объединение единомышленников, чтобы помочь каждому узнать все, что мы можем, о создании лучших веб-сайтов, которые мы можем.
Полезные вещи для чтения.
Если вам интересен этот сайт, вы, вероятно, захотите создать свой собственный сайт-монстр. Нет лучшего способа учиться, чем учиться у лучших реальных архитектур. Real Life Architectures — это продолжающаяся серия сообщений о том, как действительно успешные веб-сайты, такие как eBay, Flickr, MySpace, LiveJournal и Amazon, создают свои веб-сайты.
Учитесь у тех, кто уже сделал это, и добавьте свой личный поворот, чтобы сделать его своим.
Участвуйте, добавляя свои ссылки на интересные сайты и статьи.
Одно из невероятных бесплатных вознаграждений для пользователей за регистрацию в качестве пользователя High Scalability — это возможность публиковать статьи на главной странице. Количество материалов по темам, связанным с высокой масштабируемостью, огромно и постоянно развивается, поэтому, если люди поделятся тем, что они нашли, это поможет каждому быть в курсе того, что нового.
Все, что вам нужно сделать, чтобы публиковать свои статьи, это:
- Зарегистрируйтесь как пользователь.
- Войти.
- Выберите ссылку опубликовать новую запись вверху страницы.
- Заполните форму и нажмите «Отправить». И вы сделали!
Примите участие, подписавшись на RSS-канал.
Если вы хотите участвовать в работе этого веб-сайта, читая сообщения RSS, просто вставьте следующий URL-адрес в свою любимую программу чтения RSS: http://feeds.feedburner.com/HighScalability. Для ленты комментариев подпишитесь на http://highscalability.squarespace.com/blog/rss-comments.xml.
Рассмотрите множество преимуществ регистрации в качестве пользователя.
Хорошо, если честно, пользы от регистрации в качестве пользователя не так уж и много.Мы ненавидим сайты, которые заставляют вас регистрироваться, прежде чем вы сможете сделать что-нибудь полезное. Мы сделали так, чтобы вы могли делать все самое интересное без регистрации. Но если вы все же зарегистрируетесь, вы можете опубликовать статью и подписаться на изменения статьи по электронной почте. Вот об этом. Надеюсь, позже у нас будут хорошие дверные призы.
Как получить уведомление об изменениях содержания и комментариев?
- RSS, наверное, самый простой способ. Пожалуйста, посмотрите раздел RSS немного раньше на странице.
- Зарегистрированные пользователи могут войти в систему и выбрать Подписаться на обновления страницы в правом верхнем углу страницы.
Правила проводки
Я действительно хочу, чтобы люди публиковали все, что им интересно, но это Интернет. Итак, пожалуйста:
- Не размещайте анонсы о новых версиях продукта, классах и т. Д. Скоро сайт превратится в анонсы, люди перестанут читать, и это будет плохо. Пожалуйста, пришлите мне свое объявление, и я смогу поместить его в свой еженедельный пост с горячими ссылками.
Около
Некоторые люди спрашивали, кто я.Хороший вопрос. Я все еще работаю над этим 🙂 Меня, однако, зовут Тодд Хофф, и мой личный веб-сайт находится по адресу http://toddhoff.com. У меня большой опыт работы с крупномасштабными распределенными системами и давний интерес к этой теме. В конце концов я решил, что, поскольку я все время читаю эти материалы, я могу создать сайт об этом!
Надеюсь, вы найдете этот сайт полезным в повседневной работе в окопах.
Мини FAQ
- Почему некоторые из ваших страниц выглядят ужасно? Во время перехода от Drupal к Squarespace мне пришлось экспортировать контент и попытаться автоматически переформатировать его, чтобы он выглядел презентабельно в Squarespace.К сожалению, этот процесс не всегда срабатывал. Я сделал много ручных правок, чтобы исправить все, что мог, но на этом сайте много контента, и я многое пропустил. Так что я пытаюсь постепенно улучшать его. Если есть страница, которая, по вашему мнению, требует внимания, дайте мне знать.
Высокая масштабируемость —
Эта статья — глава из моей новой книги «Объясни облако, как будто мне 10».Первый выпуск был написан специально для новичков в облаке. Я сделал несколько обновлений и добавил несколько глав — Netflix: Что происходит, когда вы нажимаете Play? и Что такое облачные вычисления? — , которые поднимают его на пару тиков от новичка. Я думаю, что даже достаточно опытные люди могут что-то от этого получить.
Так что, если вы ищете хорошее представление об облаке или знаете кого-нибудь, пожалуйста, взгляните. Думаю, тебе понравится. Я очень горжусь тем, что получилось.
Я собрал эту главу из десятков источников, которые временами были несколько противоречивыми. Факты на местах со временем меняются и зависят от того, кто рассказывает историю и к какой аудитории они обращаются. Я пытался создать как можно более связное повествование. Если есть какие-то ошибки, я буду более чем счастлив их исправить. Имейте в виду, что эта статья не является подробным техническим описанием. Это статья с большой картинкой. Я, например, ни разу не упоминаю слово микросервис 🙂
Netflix кажется таким простым.Нажмите кнопку воспроизведения и видео волшебным образом появится. Легко, правда? Не так много.
Учитывая наше обсуждение в Что такое облачные вычисления? , вы можете ожидать, что Netflix будет обслуживать видео с помощью AWS. Нажмите кнопку воспроизведения в приложении Netflix, и видео, хранящееся в S3, будет транслироваться с S3 через Интернет прямо на ваше устройство.
Совершенно разумный подход… для гораздо меньшего объема услуг.
Но Netflix работает совсем не так. Это намного сложнее и интереснее, чем вы можете себе представить.
Чтобы понять, почему, давайте посмотрим на впечатляющую статистику Netflix за 2017 год.
- Netflix имеет более 110 миллионов подписчиков.
- Netflix работает более чем в 200 странах.
- Netflix приносит около 3 миллиардов долларов дохода в квартал.
- Netflix добавляет более 5 миллионов новых подписчиков в квартал.
- Netflix воспроизводит более 1 миллиарда часов видео каждую неделю. Для сравнения: YouTube транслирует 1 миллиард часов видео каждый день , а Facebook транслирует 110 миллионов часов видео каждый день.
- Netflix проиграл 250 миллионов часов видео за один день в 2017 году. На
- Netflix приходится более 37% пикового интернет-трафика в США.
- Netflix планирует потратить 7 миллиардов долларов на новый контент в 2018 году.
Что мы узнали?
Netflix огромен. Они глобальны, у них много участников, они смотрят много видео и у них много денег.
Другой важный факт — Netflix основан на подписке.Участники платят Netflix ежемесячно и могут отменить подписку в любое время. Когда вы нажимаете кнопку воспроизведения, чтобы расслабиться на Netflix, это должно работать лучше. Недовольные участники отписываются.
Netflix работает в двух облаках: AWS и Open Connect.
Как Netflix делает своих участников счастливыми? Конечно с облаком. На самом деле Netflix использует два разных облака: AWS и Open Connect.
Оба облака должны работать вместе, чтобы обеспечить бесконечные часы удобного для клиентов видео.
Три части Netflix: клиент, серверная часть, CDN.
Netflix можно разделить на три части: клиент, серверная часть и CDN.
Клиент — это пользовательский интерфейс на любом устройстве, используемом для просмотра и воспроизведения видео Netflix. Это может быть приложение на вашем iPhone, веб-сайт на вашем настольном компьютере или даже приложение на вашем Smart TV. Netflix контролирует каждого клиента для каждого устройства.
Все, что происходит до того, как вы нажмете play , происходит в серверной части , которая работает в AWS.Это включает в себя такие вещи, как подготовка всего нового входящего видео и обработка запросов от всех приложений, веб-сайтов, телевизоров и других устройств.
Все, что происходит после того, как вы нажмете play , обрабатывает Open Connect. Open Connect — это настраиваемая глобальная сеть доставки контента (CDN) Netflix. Когда вы нажимаете кнопку воспроизведения, видео подается из Open Connect. Не волнуйтесь; мы поговорим о том, что это значит позже.
Интересно, что в Netflix на самом деле не говорят нажатий на воспроизведение видео , они говорят, что нажатий на начало заголовка .В каждой отрасли есть свой жаргон.
Контролируя все три области — клиент, серверную часть и CDN — Netflix добился полной вертикальной интеграции.
Netflix контролирует просмотр видео от начала до конца. Вот почему он просто работает, когда вы нажимаете кнопку воспроизведения из любой точки мира. Вы надежно получаете контент, который хотите смотреть, тогда, когда вы хотите его смотреть.
Давайте посмотрим, как Netflix добивается этого.
В 2008 году Netflix начал переход на AWSНажмите, чтобы узнать больше…
Важность масштабируемости при разработке программного обеспечения
Масштабируемость — важный компонент корпоративного программного обеспечения. Приоритизация его с самого начала приводит к снижению затрат на обслуживание, лучшему пользовательскому опыту и большей гибкости.
Дизайн программного обеспечения — это балансирующее действие, при котором разработчики работают над созданием лучшего продукта в рамках ограничений по времени и бюджету клиента.
Нет необходимости идти на компромисс. Чтобы удовлетворить требования проекта, будь то технические или финансовые, необходимо идти на компромиссы.
Однако слишком часто компании ставят стоимость выше масштабируемости или даже полностью игнорируют ее важность. К сожалению, это обычное дело в инициативах по работе с большими данными, когда проблемы с масштабируемостью могут погубить многообещающий проект.
Масштабируемость не является «бонусной функцией». Именно качество определяет жизненную ценность программного обеспечения, а создание с учетом масштабируемости экономит время и деньги в долгосрочной перспективе.
Что такое масштабируемость программного обеспечения?
Система считается масштабируемой, если ее не нужно перепроектировать для поддержания эффективной производительности во время или после резкого увеличения рабочей нагрузки.
« Рабочая нагрузка » может относиться к одновременным пользователям, емкости хранилища, максимальному количеству обрабатываемых транзакций или чему-либо еще, что приводит к превышению исходной емкости системы.
Масштабируемость не является основным требованием программы, поскольку немасштабируемое программное обеспечение может хорошо работать с ограниченными возможностями.
Однако отражает способность программного обеспечения расти или изменяться в соответствии с требованиями пользователя.
Любое программное обеспечение, которое может расширяться за пределы его базовых функций, особенно если бизнес-модель зависит от его роста, должно быть настроено на масштабируемость.
Преимущества масштабируемого программного обеспечения
Масштабируемость имеет как долгосрочные, так и краткосрочные преимущества.
Вначале он позволяет компании приобретать только то, что им срочно нужно, а не все функции, которые могут пригодиться в будущем.
Например, компания, запускающая пилотную программу анализа данных, может выбрать массивный пакет корпоративной аналитики или начать с решения, которое просто выполняет функции, которые им нужны вначале.
Популярным выбором является информационная панель, которая извлекает результаты из основных источников данных и существующего корпоративного программного обеспечения.
Когда они станут достаточно большими, чтобы использовать больше аналитических программ, эти потоки данных можно будет добавить на информационную панель вместо того, чтобы заставлять компанию манипулировать несколькими программами визуализации или создавать совершенно новую систему.
Построение таким образом готовится к будущему росту, создавая при этом более компактный продукт, отвечающий текущим потребностям без дополнительных сложностей.
Это также требует меньших предварительных финансовых затрат, что является основным соображением для руководителей, обеспокоенных размером инвестиций в большие данные.
Масштабируемость также оставляет место для изменения приоритетов. Этот стандартный пакет аналитики может потерять актуальность по мере того, как компания переходит к требованиям развивающегося рынка.
Выбор масштабируемых решений защищает первоначальные вложения в технологии. Компании могут продолжать использовать одно и то же программное обеспечение дольше, потому что оно было разработано для роста вместе с ними.
Когда приходит время перемен, создание надежного масштабируемого программного обеспечения значительно дешевле, чем попытки адаптировать менее гибкие программы.
Кроме того, для внедрения новых функций в оперативный режим требуется меньше времени, чем для внедрения совершенно нового программного обеспечения.
В качестве дополнительного преимущества персоналу не потребуется много обучения или убеждения, чтобы принять эту обновленную систему. Они уже знакомы с интерфейсом, поэтому работа с дополнительными функциями рассматривается как бонус, а не рутинная работа.
Последствия ошибок масштабирования
Итак, что происходит, когда программное обеспечение не масштабируется?
Вначале слабое место трудно обнаружить. На ранних этапах разработки приложения нагрузка невелика. При относительно небольшом количестве одновременных пользователей архитектура не особо востребована.
Проблемы возникают при увеличении нагрузки. Чем больше данных хранится или одновременных пользователей собирает программное обеспечение, тем больше нагрузки на архитектуру программного обеспечения.
Ограничения, которые вначале не казались важными, становятся препятствием для продуктивности. Патчи могут решить некоторые из первых проблем, но патчи добавляют сложности.
Сложность делает постоянную диагностику проблем более утомительной (перевод: дороже и менее эффективно).
По мере того, как рабочая нагрузка превышает возможности масштабирования программного обеспечения, производительность падает.
Пользователи испытывают медленную загрузку, поскольку сервер слишком долго отвечает на запросы.Другие потенциальные проблемы включают снижение доступности или даже потерю данных.
Все это препятствует использованию в будущем. Сотрудники найдут обходные пути для ненадежного программного обеспечения, чтобы выполнять свою работу.
Это подвергает компанию риску утечки данных или того хуже.
[Подробнее об этом читайте в нашей статье об опасностях «теневого ИТ».]
Когда программное обеспечение ориентировано на клиента, ненадежность увеличивает вероятность оттока.
Google обнаружил, что 61% пользователей не дадут приложению второй шанс, если у них будет плохой первый опыт. 40% вместо этого переходят прямо к продукту конкурента.
Проблемы с масштабируемостью — это не просто ошибка новичков, которую делают небольшие компании. Даже у Disney возникли проблемы с первоначальным запуском своего приложения Applause, которое должно было дать зрителям дополнительный способ взаимодействия с любимыми шоу Disney. Приложение не могло справиться с потоком одновременных потоковых видео пользователей.
Разочарованные фанаты оставляли отрицательные отзывы, пока приложение не получило единственную звезду в магазине Google Play. Официальным лицам Disney пришлось отключить приложение, чтобы устранить ущерб, и негативная огласка была настолько сильной, что больше никогда не возвращалась в онлайн.
Установка приоритетов
Некоторые компании не уделяют приоритетного внимания масштабируемости, потому что не видят в ней непосредственной пользы.
Масштабируемость отодвигается в пользу скорости, более коротких циклов разработки или более низкой стоимости.
На самом деле есть случаи, когда масштабируемость не является главным приоритетом.
Программное обеспечение, которое должно быть прототипом или небольшим объемом доказательств концепции, не станет достаточно большим, чтобы вызвать проблемы.
Аналогичным образом внутреннее программное обеспечение для небольших компаний с низким фиксированным лимитом потенциальных пользователей может устанавливать другие приоритеты.
Наконец, когда соответствие ACID является абсолютно обязательным, масштабируемость уступает место надежности.
Однако, как правило, масштабируемость проще и требует меньше ресурсов, если рассматривать ее с самого начала.
Во-первых, выбор базы данных имеет огромное влияние на масштабируемость. Переход на новую базу данных требует больших затрат времени и средств. Это нелегко сделать позже.
Принципы масштабируемости
Несколько факторов влияют на общую масштабируемость программного обеспечения:
Использование
Использование измеряет количество одновременных пользователей или возможных подключений. Не должно быть никаких искусственных ограничений на использование.
Его увеличение должно быть таким же простым, как предоставление дополнительных ресурсов программному обеспечению.
Максимум хранимых данных
Это особенно актуально для сайтов с большим количеством неструктурированных данных: загруженный пользователем контент, отчеты сайта и некоторые типы маркетинговых данных.
Проекты в области науки о данных также подпадают под эту категорию. Объем данных, хранящихся в этом виде контента, может резко и неожиданно возрасти.
Возможность быстрого масштабирования максимального объема хранимых данных во многом зависит от стиля базы данных (SQL или NoSQL-серверы), но также очень важно уделять внимание правильному индексированию.
Код
Неопытные разработчики обычно не обращают внимания на соображения кода при планировании масштабируемости.
Код должен быть написан так, чтобы его можно было добавлять или изменять без рефакторинга старого кода. Хорошие разработчики стремятся избежать дублирования усилий, уменьшая общий размер и сложность кодовой базы.
Приложения действительно увеличиваются в размерах по мере их развития, но поддержание чистоты кода минимизирует эффект и предотвратит образование «спагетти-кода».
Масштабирование по сравнению с увеличением
Масштабирование (или «вертикальное масштабирование») предполагает рост за счет использования более совершенного или более мощного оборудования. Дисковое пространство или более быстрый центральный процессор (ЦП) используется для обработки возросшей рабочей нагрузки.
Масштабирование обеспечивает лучшую производительность, чем горизонтальное масштабирование. Все находится в одном месте, что обеспечивает более быстрый возврат и меньшую уязвимость.
Проблема с масштабированием заключается в том, что для роста остается не так много возможностей.Оборудование становится более дорогим по мере того, как оно становится более совершенным. В какой-то момент предприятия сталкиваются с законом об уменьшении прибыли от покупки передовых систем.
Также требуется время, чтобы внедрить новое оборудование.
Из-за этих ограничений вертикальное масштабирование — не лучшее решение для программного обеспечения, которое должно расти быстро и без особого уведомления.
Масштабирование (или «горизонтальное масштабирование») гораздо более широко используется для корпоративных целей.
При горизонтальном масштабировании программное обеспечение растет за счет использования большего, а не более совершенного оборудования и распределения возросшей рабочей нагрузки по новой инфраструктуре.
Затраты ниже, потому что дополнительные серверы или процессоры могут быть того же типа, который используется в настоящее время (или любого совместимого типа).
Масштабирование также происходит быстрее, поскольку ничего не нужно импортировать или перестраивать.
Однако есть небольшой компромисс в скорости. Программное обеспечение с горизонтальным масштабированием ограничено скоростью, с которой серверы могут обмениваться данными.
Однако разница не настолько велика, чтобы ее заметили большинство пользователей, и существуют инструменты, которые помогают разработчикам минимизировать эффект. В результате горизонтальное масштабирование считается лучшим решением при создании масштабируемых приложений.
Рекомендации по созданию высокомасштабируемых систем
Это и дешевле, и проще учесть масштабируемость на этапе планирования. Вот несколько рекомендаций по включению масштабируемости с самого начала:
Используйте программное обеспечение для балансировки нагрузки
Программное обеспечение для балансировки нагрузки имеет решающее значение для систем с распределенной инфраструктурой (например, приложений с горизонтальным масштабированием).
Это программное обеспечение использует алгоритм для распределения рабочей нагрузки по серверам, чтобы гарантировать, что ни один сервер не будет перегружен. Совершенно необходимо избегать проблем с производительностью.
Местоположение имеет значение
Масштабируемое программное обеспечение максимально приближено к клиенту (на уровне приложения). Уменьшение количества раз, когда приложения должны перемещаться по более тяжелому трафику рядом с основными ресурсами, приводит к более высокой скорости и меньшей нагрузке на серверы.
Пограничные вычисления — это еще одна вещь, которую следует учитывать.При увеличении количества приложений, требующих ресурсоемких приложений, сохранение как можно большего объема работы на устройстве снижает влияние зон с низким уровнем сигнала и сетевых задержек.
Кэш, где это возможно
Помните о проблемах безопасности, но кэширование — это хороший способ избежать повторения одной и той же задачи снова и снова.
Lead с API
Пользователи подключаются через множество клиентов, поэтому лидерство с API, которое не предполагает определенный тип клиента, может обслуживать их всех.
Асинхронная обработка
Это относится к процессам, которые разделены на дискретные шаги, которым не нужно ждать завершения предыдущего перед обработкой.
Например, пользователю может быть показано «отправлено!» уведомление, пока электронное письмо еще технически обрабатывается.
Асинхронная обработка устраняет некоторые узкие места, которые влияют на производительность крупномасштабного программного обеспечения.
Ограничьте одновременный доступ к ограниченным ресурсам
Не дублируйте усилия.Если более одного запроса запрашивают один и тот же расчет от одного и того же ресурса, позвольте первому завершиться и просто используйте этот результат. Это увеличивает скорость и снижает нагрузку на систему.
Используйте масштабируемую базу данных
Базы данных NoSQL обычно более масштабируемы, чем SQL. SQL действительно хорошо масштабирует операции чтения, но когда дело доходит до операций записи, он конфликтует с ограничениями, предназначенными для обеспечения соблюдения принципов ACID.
Масштабирование NoSQL требует менее строгого соблюдения этих принципов, поэтому, если соответствие ACID не является проблемой, база данных NoSQL может быть правильным выбором.
Рассмотрите решения PaaS
«Платформа как услуга» избавляет от многих проблем с масштабируемостью, поскольку масштабированием управляет поставщик PaaS. Масштабирование может быть таким же простым, как повышение уровня подписки.
Изучите FaaS
Функция как услуга произошла от PaaS и очень тесно связана. Бессерверные вычисления позволяют использовать только те функции, которые необходимы в данный момент, снижая ненужные требования к внутренней инфраструктуре.
FaaS все еще находится на стадии развития, но, возможно, стоит изучить его как способ сократить эксплуатационные расходы при одновременном повышении масштабируемости.
Не забывайте об обслуживании
Настройте программное обеспечение для автоматического тестирования и обслуживания, чтобы при его расширении работа по обслуживанию не вышла из-под контроля.
Строим с оглядкой на будущее
Приоритет масштабируемости подготавливает ваш бизнес к успеху. Подумайте об этом заранее, и вы воспользуетесь преимуществами гибкости, когда это больше всего понадобится.
Назначьте бесплатную встречу с одним из наших разработчиков, чтобы обсудить, куда вам нужно пойти и как мы можем вас туда доставить!
Запросить консультацию
Что такое масштабируемость и как ее создать?
Когда генеральный директор узнает, что его компания появится в телешоу «Shark Tank», естественной реакцией будет волнение по поводу потенциального роста хоккейной клюшки.Реакция технического директора? «О нет».
Адам Берлински-Шнин, технический директор Apairi, написал об этом опыте в своем блоге для Hacker Noon. В нем он резюмирует распространенное опасение масштабируемости.
«Основная причина, по которой масштабирование является настолько напряженным, заключается в том, что оно не является линейным: ваша система может функционировать безупречно в течение одной минуты, затем небольшое увеличение использования может привести к перебоям в работе, и у вас будет сбой», — сказал он.
Инженеры по всей стране ищут способы оптимального масштабирования собственных технологических стеков без перебоев в работе клиентов или утечки средств.Когда компании готовы к масштабированию, часть этого процесса означает отказ от старых систем. Директор по проектированию Ной Аппель в INTURN, компании, которая превращает избыточные запасы в капитал, сказал, что они полностью пересмотрели свой основной продукт SaaS, чтобы реализовать масштабируемость. Примечательно, что они перевели свой интерфейс с неуклюжих проприетарных систем на поддерживаемые сообществом библиотеки и фреймворки с открытым исходным кодом. А технический директор Бернард Ковальски сказал, что рынок страхования жилья Young Alfred перешел на облако для обеспечения бесконечной масштабируемости.
После выбора технических инструментов необходимо внедрить командные процессы. Как инженеры готовы к большим обязанностям по обработке данных и что делать в случае ошибки или сбоя? Планируйте время для технического обучения и корректировок. Когда придет время масштабироваться, команда будет готова.
Что такое масштабируемость?
Масштабируемость — это способность продукта, компании, системы, команды и т. Д. Предоставлять услуги, отвечающие растущему спросу.
Молодой Альфред
Бернард Ковальски
ГЛАВНЫЙ ТЕХНОЛОГИЧЕСКИЙ ДИРЕКТОР
Технический директорБернард Ковальски сказал, что масштабируемость — это сочетание технических инструментов и командных процессов.Трудно добавить больше серверов, процессоров и памяти без применения передовых методов обработки рабочей нагрузки. На рынке страхования жилья Young Alfred масштабирование в облаке означает постоянный мониторинг, ведение журнала и оповещение.
Опишите, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Существует два основных фактора, определяющих масштабируемость. Во-первых, это программное обеспечение, проектные решения и ИТ-инфраструктура.Второй — масштабируемость команд и процессов. Без опытных инженеров, настраивающих обе части двигателя, сложно создавать масштабируемые системы.
Масштабирование также может быть вертикальным или горизонтальным. Обычно мы думаем о горизонтальном масштабировании, когда мы добавляем в систему больше узлов для выполнения дополнительной работы, а не о вертикальном масштабировании, когда мы просто добавляем больше памяти, больше или более быстрых процессоров и больше хранилища на отдельные машины.
Вертикальное масштабирование легко, если у вас изначально есть больше долларов, но оно имеет жесткие ограничения.Для проектирования систем, которые, как ожидается, будут выполнять на порядки больше работы, планирование горизонтальной масштабируемости имеет решающее значение. Возможность быстрого увеличения вычислительной мощности и управления затратами особенно важна для стартапов с экспоненциальной траекторией роста.
Как создать эту технологию с учетом масштабируемости?
Облако — лучший способ масштабирования. Для среднего стартапа он обеспечивает практически бесконечную масштабируемость для правильно спроектированных систем.
Облако — лучший способ масштабирования. ”
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Микросервисы вместе с архитектурными шаблонами, такими как CQRS или источник событий, построенные на современной облачной инфраструктуре, помогают с масштабированием, поскольку вы разбиваете большие сложные проблемы на более управляемые части. Сервисы SaaS, такие как ECS, Kubernetes, эластичное хранилище, CDN, балансировщики нагрузки, озера данных и другие, позволяют разработчикам программного обеспечения и архитекторам создавать системы, которые могут естественно масштабироваться.Docker также меняет правила игры для многих разработчиков программного обеспечения.
Иметь все эти технологии под рукой — это здорово, но их сочетание может усложнить задачу. Мы постоянно ищем компромисс между сложностью.
Процесс создания масштабируемой системы — это только половина успеха; другая половина — работа в масштабе. Мы должны уметь диагностировать и устранять проблемы приложений, возникающие из базовой инфраструктуры, при соблюдении требований SLA.
Здесь нам нужно следовать передовым методам построения для облака с надлежащим ведением журналов, мониторингом и предупреждениями.Что касается тестирования, очень важны более низкие среды, максимально приближенные к производственной среде. Мы используем канареечные или сине-зеленые стратегии выпуска, при которых вы можете безопасно запускать новые версии своих приложений, сводя к минимуму риск негативного впечатления клиентов.
Наконец, такие подходы, как проектирование на основе предметной области, помогают снизить сложность архитектуры. Наличие надлежащего конвейера CI / CD значительно снижает болевые точки при разработке и развертывании множества взаимосвязанных сервисов.Лучше всего автоматизировать как можно больше всех аспектов процесса разработки.
Просмотреть вакансии + узнать больше
Обычный
Эрик Родригес
ВИЦЕ-ПРЕЗИДЕНТ ПО ОПЕРАЦИЯМ
Вице-президент по операциям компании Common, занимающейся технологиями в сфере недвижимости, Эрик Родригес сказал, что автоматизация помогает им масштабироваться, а также сокращает расходы. Оттуда команда инженеров может сосредоточиться на критических проблемах.
Опишите, что для вас значит масштабируемость.Почему масштабируемость важна для создаваемой вами технологии?
Масштабируемость — это возможность делать больше с меньшими затратами. Масштабирование — важная часть деятельности любой компании. Вам необходимо постоянно думать о действиях, которые можно автоматизировать, чтобы сократить расходы, а также убедиться, что ваши сотрудники сосредоточены на наиболее важных вопросах для вашего бизнеса.
Поскольку Common стремится создать постоянный бренд и новое поколение систем управления недвижимостью, нам необходимо обеспечить эффективное масштабирование, чтобы сократить расходы владельцев и застройщиков объектов собственности, которыми мы управляем.Это позволяет нам в любое время предоставлять нашим участникам восхитительный опыт самообслуживания.
Масштабируемость — это возможность делать больше с меньшими затратами. ”
Как создать эту технологию с учетом масштабируемости?
Как оператор, каждый раз, когда я работаю с командой разработчиков над технологией строительства, мне нравится сначала обрисовывать каждый этап процесса в потоке.Составив схему процесса, я заставляю себя и других определить, какие части процесса, по нашему мнению, можно автоматизировать. Я часто задаю вопрос: «Почему это нельзя автоматизировать?»
Этот вопрос является основой для масштабируемости и позволяет нам определять места, где автоматизация может нанести ущерб опыту наших клиентов, а также способствовать согласованности на пути вперед. Еще мне нравится думать о том, как сделать инструмент максимально самообслуживаемым, чтобы нам не приходилось постоянно беспокоить команду инженеров о внесении изменений по мере того, как мы узнаем больше о поведении пользователей или по мере расширения возможностей.Это не всегда возможно, но важно помнить об этом.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Наша операционная группа в значительной степени полагается на Salesforce, поскольку это платформа, которая может быть создана для удовлетворения конкретных потребностей вашей команды и интегрирована с множеством различных сторонних инструментов. С помощью Salesforce мы смогли автоматизировать различные точки взаимодействия на пути к покупке, а также автоматизировали планирование и выполнение задач по всей нашей воронке продаж.Сейчас мы даже начинаем изучать автоматизацию процессов с помощью роботов, чтобы помочь нам автоматизировать любую длительную ручную задачу, которую необходимо выполнить команде.
Просмотреть вакансии + узнать больше
ИНТУРН
Ной Аппель
ИНЖЕНЕРНЫЙ ДИРЕКТОР
Технический директорНоа Аппель сказал, что масштабируемость INTURN, компании, которая превращает избыточные запасы в капитал, требует дополнительного обучения инженеров их клиентов по мере их масштабирования.Чтобы улучшить качество обслуживания клиентов, команда Appel встроила в свой технологический стек новые языки, фреймворки и философию.
Опишите, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Масштабируемость в мире B2B SaaS требует возможности подключать, поддерживать и удовлетворять потребности крупных компаний, которым необходимо совершать операции с все более крупными наборами данных. Это также означает возможность принимать на работу новых инженеров по мере роста нашей собственной инженерной команды для удовлетворения потребностей более крупных корпоративных клиентов.По мере того, как мы начинаем внедрять корпоративные бренды в сфере моды и товаров повседневного спроса, эта способность принимать, обрабатывать и считывать огромные объемы данных, обеспечивая при этом исключительный пользовательский интерфейс, ставит задачу масштабируемости на первый план.
Масштабируемость в мире B2B SaaS требует способности привлекать, поддерживать и удовлетворять потребности крупных компаний. ”
Как создать эту технологию с учетом масштабируемости?
При капитальном ремонте нашего основного продукта SaaS, начиная с масштабируемости, мы перевели серверную часть из монолитного в приложение для микросервисов и перевели нашу клиентскую часть с неуклюжих проприетарных систем на поддерживаемые сообществом библиотеки и платформы с открытым исходным кодом.Мы также перестраиваем наши системы DevOps, чтобы лучше понимать, как взаимодействуют наши распределенные сервисы.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
В рамках этого недавнего капитального ремонта мы ввели в наш технологический стек новые языки, фреймворки и философию, и все это с целью создания программного обеспечения, которое может обрабатывать большие наборы данных, улучшая при этом удобство работы наших конечных пользователей. На уровне обслуживания мы представили Go, чтобы сделать возможным переход к приложению микросервисов.
В качестве промежуточного программного обеспечения мы ввели GraphQL в стек для обработки запросов, сделанных из нашего веб-приложения сразу нескольким службам. А во внешнем интерфейсе мы обновили пользовательский интерфейс и пользовательский интерфейс, чтобы изящно обрабатывать запросы на доступ к большим объемам данных и управление ими. Объем данных, передаваемых от сервера к клиенту, увеличивается по мере того, как мы привлекаем более крупных корпоративных клиентов, и именно эти технологии позволяют нам масштабироваться для удовлетворения их потребностей.
Просмотреть вакансии + узнать больше
Crunchyroll
Джерри Вонг
АРХИТЕКТОР ИНФРАСТРУКТУРЫ
Архитектор инфраструктурыДжерри Вонг сказал, что масштабируемость реализована во всех инженерных процессах в компании Crunchyroll, занимающейся цифровыми медиа и манга аниме.При анализе архитектурного дизайна компания спрашивает, может ли технология поддерживать текущий масштаб, а также может ли он поддерживать в 10 раз больше пользователей в том же масштабе.
Опишите своими словами, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Масштабируемость означает, что все компоненты продукта — включая архитектуру, инфраструктуру, а также базовые службы — способны обрабатывать текущие запросы клиентов и корректно удовлетворять будущие потребности.Масштабируемость — очень важный краеугольный камень нашей технологии и платформы, потому что она служит нашим поклонникам во всем мире. Имея более 2 миллионов платных подписчиков, наши поклонники ожидают от нашей платформы видео по запросу высочайшего качества, стабильности и функциональности.
Как создать эту технологию с учетом масштабируемости? Каким конкретным стратегиям или инженерным приемам вы следуете?
Концепция масштабируемости, встроенная в наши процессы проектирования, побуждает всех инженеров разрабатывать и думать с учетом масштабируемости микросервисов, экземпляры которых они создают.Для каждой концепции продукта всегда проводится архитектурный анализ концепции продукта, за которым сразу же следует техническое открытие. При анализе архитектурного проекта мы всегда задаем два вопроса: «Может ли этот проект поддерживать текущую шкалу Crunchyroll?» и «Может ли этот дизайн поддерживать в 10 раз больше пользователей нынешней шкалы Crunchyroll?» Это простой, но эффективный вопрос, который открывает проблему масштабируемости и побуждает инженеров очень широко рассматривать свои проектные решения.
Эти вопросы задают, создаем ли мы новый конвейер непрерывной доставки, новую службу машинного обучения, которая сможет давать более точные рекомендации пользователям, или даже планируем построить вместо покупки решение.
Уходя от архитектурного дизайна, мы всегда доводим его до совершенства. Никто не ожидает, что первоначальный дизайн чего-либо также будет идеальным с первого дня. В нашей компании есть вспомогательные функции, которые стимулируют эффективные итерации, такие как множество нагрузочных тестов QA / QE, тестов производительности и т. Д.По сути, после того, как технология запущена в производство, итерация этой технологии является нашим ключом к успеху с точки зрения масштабируемости.
Наши инженерные процессы побуждают всех инженеров разрабатывать и думать с учетом масштабируемости микросервисов, которые они создают ».
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
AWS — наш облачный провайдер для создания масштабируемой инфраструктуры.Большое количество сервисов, предоставляемых AWS, позволяет нам легко создавать, строить и развертывать сервисы, которые содержат основные функции нашей платформы VOD в глобальном масштабе.
Наблюдаемость — это следующая ключевая концепция, которую мы используем для эффективного измерения того, насколько хорошо работает служба, и выявления ключевых проблемных компонентов, в которых мы можем затем выполнить итерацию и исправить. New Relic — один из основных инструментов наблюдения, который мы используем для измерения и поддержки масштабируемости за счет наблюдаемости.Сети доставки контента (CDN) — еще одна важная технология, которую мы используем, чтобы лучше обслуживать наших поклонников. Сети CDN позволяют нам кэшировать видеоресурсы ближе к периферийным местоположениям наших клиентов, чтобы обеспечить им лучший и более производительный опыт за счет кэширования популярных ресурсов.
Просмотреть вакансии + узнать больше
Instacart
Дастин Пирс
Вице-президент по инфраструктуре
Вице-президентпо инфраструктуре Дастин Пирс сказал, что разработка системы с ограничениями помогла контролировать масштабируемость онлайн-службы доставки продуктов Instacart.Автоматические выключатели и средства управления, ограничивающие доступ к данным, помогают небольшим изменениям в поведении клиентов или изменениях кода превращаться в проблемы размером с приливную волну.
Опишите своими словами, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Масштаб преувеличивает недостатки — вот почему масштабируется простота. Каждая часть вашей системы должна быть очень хорошо определена и понятна для масштабирования. По мере того, как вы масштабируете систему, вы вводите новую сложность в виде новых видов отказов.Чем больше компьютеров и больше подключений, тем больше шансов на то, что что-то пойдет не так. Обоснование этих режимов отказа и повышение устойчивости вашей системы очень важно. Не менее важно убедиться, что вы извлекаете уроки из сбоев системы и возвращаете полученные знания в систему в форме дополнительной устойчивости.
Масштаб преувеличивает недостатки — вот почему масштабируется простота ».
Как создать эту технологию с учетом масштабируемости? Каким конкретным стратегиям или инженерным приемам вы следуете?
При приближении к масштабу одним из наиболее важных аспектов является проектирование систем с ограничениями.Запись и чтение данных из базы данных часто являются наиболее острыми проблемами масштабирования. Поскольку небольшие изменения в поведении пользователей или кода могут превратиться в масштабную приливную волну, вам необходимо разработать автоматические выключатели и средства управления, ограничивающие доступ к данным. На самых ранних этапах масштабирования это означает, что разработчики должны привыкать выполнять работу партиями. Наиболее распространенный механизм — это интерфейсы запросов, поскольку они требуют разбиения на страницы и ограничивают объем данных, который может быть возвращен из любого данного запроса.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Веб-серверыи другие службы без отслеживания состояния используют неизменяемую инфраструктуру и автоматическое масштабирование. Это позволяет нам быстро наращивать мощности по мере необходимости. При работе с облачной инфраструктурой мы не устраняем и не отлаживаем отдельный узел. Если один из узлов плохо себя ведет, его просто заменяют. Netflix сделал популярным этот менталитет «крупный рогатый скот, а не домашние животные». Что касается баз данных, мы упрощаем работу с помощью типичных систем РСУБД, которыми управляет наш облачный провайдер.Мы используем наше приложение, чтобы ограничить доступ к этим базам данных и сохранить их размер и рабочую нагрузку управляемыми, распределяя нагрузку по нескольким базам данных, которые содержат части данных. Это процесс, называемый горизонтальным сегментированием.
Просмотреть вакансии + узнать больше
TrueAccord
Джеффри Линг
ИНЖЕНЕРНЫЙ ДИРЕКТОР
В финтех-компании TrueAccord инженерам предоставляется свобода в выборе способов разработки своих услуг.Директор по инжинирингу Джеффри Линг сказал, что они поддерживают сплоченность команд благодаря тому, что опытные инженеры выступают в роли архитекторов и дают советы.
Опишите своими словами, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Программное обеспечение для масштабирования — это больше, чем просто серверы, работающие при высокой нагрузке. Речь также идет о том, чтобы наша команда могла быстро и безопасно создавать функции. Включение, которое требует размышлений как об организации, так и о технологиях.
Масштабирование важно для нас, потому что мы работаем с миллионами активных учетных записей в соответствии со строгими федеральными и государственными правилами соответствия. Если наша система работает неправильно, мы несем ответственность за любые ошибки, которые она допускает. Хуже того, наши потребители потеряют доверие к нам и нашей способности помочь им расплатиться с долгами. Мы постоянно работаем над тем, чтобы позволить нам продолжать создавать новые функции и удовлетворять потребности потребителей, одновременно преодолевая эти ограничения.
Как создать эту технологию с учетом масштабируемости?
Каждый инженер имеет полную автономию в выборе того, как они хотят разрабатывать свои услуги, хотя мы предоставляем рекомендуемый набор инструментов с лучшими практиками в качестве руководства.Мы поддерживаем взаимосвязь благодаря тому, что опытные инженеры выступают в роли архитекторов, чтобы находить точки повторного использования и давать советы по возможным неблагоприятным последствиям.
По мере того, как мы создаем нашу технологию, мы стараемся поддерживать очень четкое разделение задач по всей системе. Мы согласовываем границы обслуживания с учетом потребностей наших команд, работая над сценариями с целью сокращения объема межгрупповой работы, необходимой для каждого сценария.
Программное обеспечение для масштабирования — это больше, чем просто серверы, работающие при высокой нагрузке.”
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
В качестве серверной части мы используем Go, Scala и Java, а также узел, где это необходимо. Go отлично подходит для легких микросервисов, таких как лямбда-функции, в то время как Scala и Java отлично подходят для сложной бизнес-логики, требующей более выразительного языка.
Мы используем целый набор продуктов AWS для размещения наших сервисов и обучения моделей машинного обучения. Мы масштабируем серверы с помощью Kubernetes и масштабируем наши склады с помощью Snowflake.
Для нашей команды мы ориентируемся на архитектуру с помощью Miro, который заслуживает особого упоминания как отличный инструмент для совместной работы с интерактивной доской и диаграммами. У нас есть живая версия нашей архитектуры, которую каждый может комментировать и задавать вопросы. Это позволило командам работать над архитектурой асинхронно, поскольку мы принимаем удаленную работу.
Просмотреть вакансии + узнать больше
Товарищи по почте
Санкет Агарвал
МЕНЕДЖЕР, ИНЖИНИРИНГ
Во время появления заказов на домоседу служба доставки Postmates неожиданно выросла.Менеджер по проектированию Санкет Агарвал сказал, что внедренные процессы проверки кода и проектирования в сочетании с наймом нужных специалистов помогли удовлетворить потребности клиентов, сохранив при этом безопасность основных сотрудников.
Опишите своими словами, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Масштабируемость обеспечивает высококачественное обслуживание нашей постоянно растущей клиентской базы. Нам необходимо масштабировать нашу человеческую организацию, нашу культуру и сделать наши системы надежными.Мы также берем на себя большую социальную ответственность по мере того, как мы масштабируемся, особенно когда мы предоставляем основные услуги и работу во время пандемии.
Postmates сейчас в той точке, где масштабирование является образом жизни. Любая строка кода, которую мы добавляем, затрагивает миллионы пользователей. Это приносит проблемы и возможности. С одной стороны, нам нужны процессы и автоматизация, чтобы избежать ошибок, но с другой стороны, мы можем использовать возможности нашей пользовательской базы для создания волшебного опыта. Например, Postmates может порекомендовать вам еду, которая может вам понравиться.Вы можете получить такой опыт только с помощью данных и масштаба.
Масштабируемость обеспечивает высококачественное обслуживание нашей постоянно растущей клиентской базы ».
Как создать эту технологию с учетом масштабируемости?
Надежные инженерные практики и культура одержимости потребителями являются ключом к созданию продуктов с любовью, заботой и масштабируемостью. Мы часто заботимся о том, чтобы сэкономить несколько миллисекунд, чтобы улучшить взаимодействие с пользователем.
Мы заботимся о нашем процессе проверки кода, процессе проектирования и обучаем людей самодостаточности. Мы также инвестируем в патологоанатомический процесс, в ходе которого мы выявляем и решаем ключевые проблемы с нашими системами.
Ключевым моментом является найм нужных людей. Благодаря нашему бренду мы смогли привлечь одни из лучших талантов, которые может предложить отрасль. Они привносят опыт создания этих систем и дают нам возможность предвидеть передовой опыт.
Во время пандемии у нас был наплыв людей, пытающихся оставаться дома и заказывать еду, и вы должны реагировать на всплеск спроса.Мы не могли к этому подготовиться. Но наша команда собиралась по выходным, чтобы не светить. Способность быстро реагировать и адаптироваться также является ключом к масштабируемости, особенно в гиперконкурентной среде.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
В Postmates мы полагаемся на закаленные в боях технологии. Мы создали множество нестандартных технологий, которые не подходят для нашего сценария использования или масштаба. Но мы также сильно полагаемся на открытый исходный код, чтобы не изобретать колесо.
Мы создали внутреннюю систему картографирования и планирования, которая позволяет сопоставить курьеров с доставками в больших масштабах. Это помогает оптимизировать время доставки при сбалансированном дозировании. У нас также есть хорошо масштабируемая инфраструктура данных поверх BigQuery, которая, наряду с машинным обучением, позволяет использовать механизмы рекомендаций, такие как наш канал или поиск.
Большинство наших приложений построено на сервис-ориентированной архитектуре. Мы используем технологии с открытым исходным кодом, такие как Kubernetes и Docker, для размещения наших сервисов.
Просмотреть вакансии + узнать больше
Грамматика
Кирилл Голоднов
СТАРШИЙ ИНЖЕНЕР ПО ПРОГРАММНОМУ ОБЕСПЕЧЕНИЮ
Старший инженер-программист Кирилл Голоднов знал, что, когда программа редактирования Grammarly станет доступной в Google Docs, ожидается резкий рост. Замена языков программирования, удаление устаревших экземпляров AWS и добавление уровня кэширования подготовили их к скачкам трафика.
Опишите своими словами, что для вас значит масштабируемость.Почему масштабируемость важна для создаваемой вами технологии?
Цифровой помощник по письмуGrammarly используется миллионами людей каждый день в веб-браузерах и на разных устройствах, и мы постоянно расширяем доступность. Чтобы обеспечить эту поддержку, мы доставляем сложные предложения по написанию на миллионы устройств в режиме реального времени по всему миру, что означает, что мы обрабатываем миллионы одновременных подключений к серверу, для чего требуются сотни серверов. Поскольку Grammarly продолжает ускорять рост, поиск решений этих проблем является ключом к поддержанию бесперебойной работы наших пользователей.
Мы считаем важным применять детальный подход к масштабируемости и не полагаться на добавление дополнительных серверов, не думая более критически о наших конвейерах ».
Как создать эту технологию с учетом масштабируемости?
Мы считаем важным применять детальный подход к масштабируемости и не полагаться на добавление дополнительных серверов, не задумываясь более критически о наших конвейерах. Горизонтальная масштабируемость не может решить все проблемы, потому что она создает новые; в частности, необходимость запускать и управлять тысячами серверов.Мы используем ряд тактик, чтобы уменьшить эту потребность на порядок. Оптимизируем наши алгоритмы и нейронные сети. Мы также стремимся определить языки программирования и среды выполнения, которые снизят нагрузку на наш сервер.
Мы исторически использовали Common Lisp в нашем механизме предложений, но он не был оптимизирован для высоконагруженных процессов, необходимых для нашего продукта. Поэтому мы недавно заменили его на Clojure, диалект Lisp, работающий на JVM. В результате мы смогли отключить многие из наших экземпляров AWS.Мы также обнаружили, что иногда помогает добавление слоя кэширования. Когда мы готовились к поддержке Grammarly в Google Docs, мы ожидали большого скачка трафика. В этом сценарии у нас отлично сработало кеширование.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Наша команда работает на AWS. Для вычислений мы запускаем контейнеры Docker в сервисе эластичных контейнеров AWS с автоматическим масштабированием, что довольно типично в наши дни.Для нас более сложной задачей является масштабирование хранилища и обработки данных. Пользователи Grammarly, которые пишут документы в редакторе Grammarly, должны быть уверены в том, что они могут безопасно хранить их там, поэтому нам нужно было найти творческие решения для обеспечения распределенности этого хранилища и устойчивости к сбоям. В конечном итоге мы разработали индивидуальную архитектуру на основе AWS DynamoDB и S3, координируемую Apache ZooKeeper, для обеспечения согласованности хранимых документов. Для рабочих процессов с большими данными наша команда использует Kafka под управлением AWS, а также Apache Spark на AWS EMR, а также AWS Athena и Redshift.
Grammarly нанимает сотрудников | Смотреть 27 вакансий
Discord
Дейзи Чжоу
СТАРШИЙ ИНЖЕНЕР ПО ПРОГРАММНОМУ ОБЕСПЕЧЕНИЮ
Старший инженер-программист Дейзи Чжоу заметила рост числа пользователей социальной платформы Discord из-за COVID-19. Вне пандемии инженеры Discord пытаются автоматизировать масштабирование, чтобы действовать проактивно для роста пользователей, а не реагировать на трафик клиентов.
Опишите своими словами, что для вас значит масштабируемость.Почему масштабируемость важна для создаваемой вами технологии?
В Discord мы создаем гостеприимную платформу, где каждый может разговаривать, общаться со своими друзьями и создавать свои сообщества. В последнее время, когда так много людей перемещают большую часть своей жизни в Интернет, мы наблюдаем огромный, неожиданный рост активных пользователей более чем на 50 процентов по сравнению с предыдущим годом. Discord всегда был известен как быстрый и надежный продукт. Масштабируемость — это инженерная работа, необходимая для поддержания качества, которого ожидают пользователи, даже в условиях такого неожиданного роста.
Как создать эту технологию с учетом масштабируемости?
Мы запускаем службы без отслеживания состояния, которые можно легко масштабировать вверх или вниз, когда это возможно. Настроить, как и когда выполнять автоматическое масштабирование заранее, намного проще, чем вручную масштабировать при резком изменении трафика. Это также упрощает многие другие аспекты обслуживания службы, поэтому почти всегда стоит настраивать службы таким образом с самого начала, когда это возможно.
Для большинства других оптимизаций масштабирования поиск баланса между ранним отказом от чрезмерного проектирования и своевременной готовностью к поддержке большей нагрузки является самой сложной частью.Трудно точно определить, но идеальное время для начала работы над масштабируемостью — это после того, как проблемы, с которыми мы столкнемся, будут устранены, но до того, как они сокрушат нас. Мы используем комбинацию показателей использования ресурсов и показателей производительности для измерения производительности нашей системы, а также взаимодействия пользователей с нашей системой. Некоторыми явными индикаторами того, что сервису нужно немного любви, являются несколько более горячих сегментов, немного сниженная производительность в периоды пиковой нагрузки или снижение производительности для отдельных опытных пользователей и групп.
Наши конкретные стратегии зависят от конкретной проблемы. За последние несколько месяцев мы работали над двумя важными проектами масштабирования инфраструктуры чата Discord, в которых используются довольно общие стратегии: объединение запросов и горизонтальная масштабируемость. Недавно мы создали службу, которая находится перед нашей базой данных сообщений, которая теперь объединяет запросы и позволит нам легко добавлять другие оптимизации в будущем. Другой — это реорганизация нашей службы гильдий, которая по мере роста наших крупнейших сообществ начала изо всех сил обрабатывать 100 000 подключенных сеансов за один процесс Эликсира.Мы горизонтально масштабировали процессы Elixir, чтобы мы могли масштабироваться по мере увеличения количества подключенных сеансов.
Мы запускаем службы без отслеживания состояния, которые можно легко масштабировать вверх или вниз, когда это возможно ».
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Многие Discord работают на Google Cloud Platform (GCP), и, когда это возможно, мы запускаем сервисы без сохранения состояния как группы экземпляров GCP с автоматическим масштабированием.
Многие из наших сервисов с отслеживанием состояния, которые поддерживают соединения с клиентами, а также обрабатывают и распространяют сообщения в реальном времени, написаны на Elixir, который хорошо подходит для рабочей нагрузки по передаче сообщений в реальном времени. Но в последние годы мы столкнулись с некоторыми ограничениями масштабирования. Discord написал и предоставил открытый исходный код для нескольких библиотек, которые облегчают некоторые проблемы, с которыми мы столкнулись при управлении большой распределенной системой Elixir с сотнями серверов. К ним относятся ZenMonitor для объединенного мониторинга, Manifold для пакетной передачи сообщений между узлами и Semaphore, который полезен для регулирования, когда службы приближаются к своим пределам.
В культурном отношении мы не уклоняемся от опробования новых технологий, когда наши нынешние не идут вразрез. ScyllaDB и Rust — два примера, когда наши исследования окупились, и они стали хорошим решением некоторых наших проблем.
Просмотреть вакансии + узнать больше
Удеми
В компании edtech Удеми, вице-президент по инжинирингу Влад Берковски и старший директор по инжинирингу Кэтлин Ван сказали, что масштабируемость — это создание решений, которые фокусируются на проблемах клиентов без добавления сложностей.Для этого они внедрили инфраструктуру гибридного облака и запустили веб-сайт из частного и общедоступного облака.
Кэтлин Ван
SR. ДИРЕКТОР ПО ТЕХНИКЕ
Опишите своими словами, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
«Масштабируемость означает создание высококачественных продуктов и услуг, которые решают бизнес-задачи», — сказал Ван. «Это важно, потому что по мере роста нашего бизнеса потребности в функциях и возможностях естественным образом усложняются.Проектирование и создание решений, ориентированных на ключевые проблемы клиентов, без излишней сложности или нежелательного взаимодействия с пользователем, имеет решающее значение для предоставления высококачественных продуктов и услуг, которые могут способствовать и поддерживать рост бизнеса. Решения, которые мы создаем, должны быть эффективными и гибкими, чтобы соответствовать потребностям бизнеса ».
Мы проектировали нашу инфраструктуру с учетом масштабируемости ».
Влад Берковский
ВИЦЕ-ПРЕЗИДЕНТ ПО ТЕХНИКЕ
Как создать эту технологию с учетом масштабируемости?
«Решение об архитектуре системы обычно зависит от приложения», — сказал Берковский.«Конкретные проблемы могут возникнуть в отношении времени отклика сайта, объема чтения и записи данных и т. Д. Вообще говоря, существует три варианта масштабирования технологии: горизонтальное дублирование, разделение системы по функциям и разделение системы на отдельные части.
«В Udemy мы проектировали нашу инфраструктуру с учетом масштабируемости. Если инфраструктура не масштабируется, масштабируемость приложения не спасет положение. Вот почему мы приняли гибридную облачную архитектуру: запуск сайта как из частного, так и из общедоступного облака.Частное облако обеспечивает предсказуемую производительность и стоимость, а общедоступное облако обеспечивает практически неограниченную емкость для горизонтального масштабирования по мере необходимости.
«Что касается людей, мы — компания DevOps. Наши инженеры пишут, а затем используют свой код в производственной среде. Это постоянное владение повышает качество и подотчетность. Цель групп по эксплуатации сайта — дать разработчикам возможность сохранить это право собственности ».
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
«Как только вопрос емкости будет решен и емкость будет обеспечена, следующие большие вопросы будут связаны с масштабируемостью приложения», — сказал Берковски.«Очень сложно предсказать, какие части системы станут узкими местами по мере роста нагрузки на сайт. Вот почему мы используем «игровые дни», когда проводим стресс-тестирование нашего сайта или его компонентов, чтобы выявить узкие места при определенных профилях нагрузки.
«Автоматизация необходима для увеличения масштабов рабочих групп на объекте. Автоматизация помогает сместить акцент с выполнения повторяемых задач вручную на их автоматизацию и сосредоточение внимания на более важной стратегической работе. В Udemy мы приняли подход «инфраструктура как код» к управлению инфраструктурой.Мы не разрешаем вносить изменения в инфраструктуру напрямую вручную; любые изменения должны быть реализованы в виде кода, чтобы гарантировать предсказуемые и повторяемые результаты.
«Мы используем такие популярные инструменты настройки и оркестровки, как Ansible и Terraform. Поскольку эти инструменты не зависят от производителя, они одинаково хорошо работают как в публичном, так и в частном облаке. Это позволяет нам использовать один и тот же набор инструментов на нескольких облачных платформах, сокращая наши усилия по управлению этими платформами ».
Просмотреть вакансии + узнать больше
BigCommerce
Сандип Ганапатираджу
ВЕДУЩИЙ ИНЖЕНЕР ПО РАЗРАБОТКЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Сандип Ганапатираджу, ведущий инженер-разработчик программного обеспечения, сказал, что целью масштабируемости платформы электронной коммерции BigCommerce является увеличение числа клиентов, пользующихся минимальным количеством технических изменений.Множественное моделирование типов клиентов и их использования помогает им спланировать, когда выпускать новые бизнес-функции.
Опишите своими словами, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Для меня это больше связано со способностью платформы адаптироваться к растущему использованию клиентов с наименьшим количеством необходимых изменений.
Это означает наличие четкой стратегии с предварительным моделированием различных сценариев использования клиентами на основе того, как бизнес видит вероятность роста использования в течение следующих нескольких месяцев, включая выпуски продуктов из альфа-, бета-версий и становление общедоступными.
У нас может быть четкий план масштабируемости, когда мы рассчитываем следующие «x» месяцев, когда мы ожидаем, что использование клиентов вырастет на «y», в то время как система способна выдерживать нагрузку «y + z» в течение короткого периода времени.
Масштабируемость — это в большей степени способность платформы адаптироваться к растущему потреблению клиентов с минимальным количеством необходимых изменений ».
Как создать эту технологию с учетом масштабируемости? Поделитесь некоторыми конкретными стратегиями или инженерными приемами, которым вы следуете.
Мы проводим несколько симуляций. Мы создаем примеры того, как самый крупный пользователь создает еще более широкое использование, средний пользователь работает со средним уровнем использования, а также внезапный короткий всплеск использования, такой как продажи.
Каждый из этих сценариев тщательно продумывается, не забывая о бизнесе. Затем мы информируем бизнес, чтобы помочь запланированному развертыванию новых функций.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
BigCommerce использует JMeter и запросы для объяснения планов быстрой проверки.Затем мы используем BlazeMeter, когда у нас есть надежный тест для проверки общей производительности системы.
Мы много контролируем производство с помощью информационных панелей Grafana, чтобы увидеть, как различные сервисы работают в производственной среде. Мы также используем канареечные развертывания, чтобы выпустить новую версию для определенной группы пользователей программного обеспечения, чтобы увидеть любые беспрецедентные ошибки или масштабы. New Relic предупреждает, если запросы копируются и время ожидания превышает «x» процентов за заданное время. Мы также отслеживаем запросы, которые занимают много времени, с помощью инструментов распределенной трассировки, чтобы увидеть, какая конкретная микрослужба замедляет общий запрос.
Просмотреть вакансии + узнать больше
Соврн
Тео Чу
ИНЖЕНЕРНЫЙ МЕНЕДЖЕР, ТОРГОВЛЯ
Для Sovrn масштабируемость имеет решающее значение, поскольку их сеть обрабатывает десятки тысяч запросов API в секунду. Технический менеджер Тео Чу сказал, что они должны предвидеть будущий спрос при строительстве, чтобы предотвратить задержки и сделать клиентов счастливыми.
Опишите своими словами, что для вас значит масштабируемость.Почему масштабируемость важна для создаваемой вами технологии?
Масштабируемость означает создание наших технологий и продуктов с нуля с учетом будущего масштабирования. Это означает предвидение будущего спроса и возможность удовлетворить этот спрос без необходимости перепроектирования или капитального ремонта нашей системы. Масштабируемость особенно важна для нас, поскольку мы обрабатываем десятки тысяч запросов API в секунду. Наши конвейеры данных обрабатывают и анализируют миллиарды событий в день. Мы поддерживаем трафик от крупных издателей в Интернете, и наши партнеры ожидают, что мы будем управлять их масштабами ежедневно, не жертвуя задержками или надежностью.
Масштабируемость означает создание наших технологий и продуктов с нуля с учетом будущего масштабирования ».
Как создать эту технологию с учетом масштабируемости?
Создание для масштабируемости означает проектирование, создание и обслуживание инженерных систем с глубоким техническим пониманием используемых нами технологий и ограничений производительности наших систем. Наш подход заключался в том, чтобы обеспечить масштабируемость снизу вверх как с технической точки зрения, так и с точки зрения продукта.В техническом плане мы полагаемся на базовые технологии и платформы, обеспечивающие масштабирование.
Что касается продукта, то мы обнаруживаем, что создание базовых компонентов на раннем этапе для ожидаемого масштаба приносит гораздо больше пользы, чем необходимость повторного проектирования системы позже. Это было проиллюстрировано нашим продуктом Optimize, где мы смогли без особых усилий масштабировать нашу базу данных для обработки сотен миллионов сопоставлений в предыдущих итерациях.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Мы полагаемся на ряд технологий, которые поддерживают и обрабатывают данные в большом масштабе, включая Cassandra, Kafka и Spark.Поскольку это базовые блоки нашей системы, мы сильно оптимизируем их и тестируем каждый компонент под нагрузкой, кратной нашему текущему масштабу, чтобы обеспечить масштабируемость и устранить любые узкие места. Поскольку наша инфраструктура полностью построена на AWS, мы также используем инструменты AWS, поддерживающие масштабируемость, такие как группы автомасштабирования.
Просмотреть вакансии + узнать больше
Optiver
Уилл Вуд
ИНФРАСТРУКТУРА И КОНТРОЛЬ КОМАНДЫ
Optiver, глобальный производитель электронных товаров, использует собственный капитал на свой страх и риск для обеспечения ликвидности финансовых рынков.Инженеры и трейдеры Optiver объединяются, чтобы найти простые решения сложных проблем. Уилл Вуд из Чикаго сказал, что для обеспечения масштабируемости технологий его команда использует системы нагрузочного тестирования, которые они создают сами, чтобы увидеть, как их технология реагирует в конкретных ситуациях.
Опишите, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Масштабируемость означает возможность легко справиться со следующим загруженным рыночным днем.Технология, которую я создаю, находится в центре окружающей среды, поэтому, если у нее возникнут проблемы с производительностью, влияние будет большим. Если он будет хорошо масштабироваться, фирма сможет оставаться полностью активной в экстремальных рыночных условиях. Моя цель состоит в том, чтобы эта технология имела такие же характеристики производительности в экстремальный день, как и в средний день.
Моя цель состоит в том, чтобы эта технология имела такие же характеристики производительности в экстремальный день, как и в средний.”
Как создать эту технологию с учетом масштабируемости?
Я стараюсь максимально уменьшить разброс в производительности. Для этого я выбираю алгоритмы с постоянной производительностью, использую простые функции языка программирования и сохраняю ресурсы, используемые моей системой, изолированными от помех.
Я также проектирую свои системы для обработки определенной нагрузки, которая обычно является некоторой оценкой экстремального дня, и веду себя детерминированным образом, если эта нагрузка превышена.Затем я отслеживаю фактическую производительность и нагрузку в производственной среде, сигнализируя мне, когда последняя приближается к заданному пороговому значению.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости?
В моей команде мы создаем собственные системы для нагрузочного тестирования. Это позволяет нам тестировать очень конкретные сценарии и адаптироваться к меняющимся рыночным условиям и требованиям бизнеса. Мы также разработали систему для мониторинга производительности наших приложений в производственной среде.Это дает нам регулярную обратную связь о том, как работают наши технологии, и позволяет нам быстро замечать любое снижение производительности.
Просмотреть вакансии + узнать больше
Jellyvision
Алексей Бугош
ГЛАВНЫЙ ИНЖЕНЕР ПО ПРОГРАММНОМУ ОБЕСПЕЧЕНИЮ
При открытой регистрации обращений за медицинской помощью инструменты Jellyvision должны уметь справляться с наплывом трафика. Багош говорит, что его команда полагается на данные за предыдущие годы, частое нагрузочное тестирование и такие инструменты, как AWS, чтобы обеспечить готовность своих систем к напряженному сезону.
Почему масштабируемость важна для создаваемой вами технологии?
В Jellyvision мы сталкиваемся с довольно интересным набором проблем масштабируемости. Наш продукт ALEX Benefits Counselor используется сотрудниками, чтобы помочь им выбрать свое медицинское обслуживание каждый год во время открытого набора. Поскольку большинство наших клиентов имеют открытую регистрацию в течение тех же нескольких осенних месяцев, мы наблюдаем резкую, но предсказуемую структуру нагрузки. Возможность увеличения и уменьшения масштабов этих систем и быстрого получения результатов является ключом к нашей способности помогать нашим пользователям.
Внутренние службы используют автоматическое масштабирование на случай, если мы увидим какие-либо большие неожиданные всплески трафика, но они эффективны в наше непиковое время ».
Как создать эту технологию с учетом масштабируемости?
Первая и самая важная стратегия, которую мы имеем, — это определение ожидаемого использования наших систем при первоначальной разработке требований. Эти требования определяют наши ожидания при проверке кода и дизайна и помогают нам выбрать правильные базовые технологии и шаблоны архитектуры для наших систем.
Этот процесс заставляет нас делать осознанный выбор в отношении того, какая логика должна работать во интерфейсных приложениях JavaScript, а какая логика должна жить в наших внутренних службах. Наш интерфейс полностью обслуживается сетью CDN, которая перенесла большую часть проблем с масштабируемостью на AWS. Поскольку наши серверные службы работают в основном независимо, мы можем добавлять экземпляры по желанию. Внутренние службы используют автоматическое масштабирование на случай, если мы видим какие-либо большие неожиданные всплески трафика, но они эффективны в наше непиковое время.
Другая часть нашей стратегии зависит от накопленных за годы данных о наших ожидаемых уровнях нагрузки, основанных на количестве клиентов и исторических уровнях нагрузки. Мы проводим всестороннее нагрузочное тестирование, приближающееся к пиковым временам, и корректируем наши базовые параметры, чтобы у автомасштабирования было меньше работы.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости?
Jellyvision ориентирована на AWS. Мы используем Cloudfront и S3 вместе для обслуживания нашего внешнего кода JavaScript и медиаресурсов.Мы находимся в процессе перевода наших основных сервисов с Elastic Beanstalk на ECS и Fargate.
Для ведения журналов и показателей Sumo Logic является нашим поставщиком. Мы полагаемся на информационные панели Sumo Logic, оповещения и доступ к нашим историческим данным, чтобы подготовиться к нашему напряженному сезону.
Просмотреть вакансии + узнать больше
Hudson River Trading
Джейсон Мачта
ВЕДУЩИЙ РАЗРАБОТЧИК
Компания HRT, занимающаясяFintech, создала свои собственные инструменты и запатентованные функции обеспечения надежности для решения проблем с масштабируемостью.Однако Маст считает не только инструменты, но и культуру своей команды, оказавшую наибольшее влияние на масштабируемость. Он говорит, что, принимая «долгосрочное мышление», инженеры вдохновляются на создание систем, способных справляться с новыми функциями и факторами стресса.
Опишите, что для вас значит масштабируемость. Почему масштабируемость важна для создаваемой вами технологии?
Масштабируемость означает понимание того, как используются текущие мощности и как технологии будут вести себя по мере приближения к насыщению или превышения его.Это особенно важно при работе на финансовых рынках, где объемы сильно различаются, а всплески активности могут неожиданно подавить систему, которая, казалось, имела значительный запас.
В сфере финансов возможности могут быть мимолетными. Неспособность масштабироваться для удовлетворения потребностей роста может быстро отразиться на чистой прибыли. В проприетарной торговле необходимо учитывать несколько параметров роста: объем рынка, географию и классы активов, наш каталог торговых моделей и сложность машинного обучения.Наш успех зависит от способности реагировать на расширение по всем этим параметрам.
В сфере финансов возможности могут быть мимолетными. Неспособность масштабироваться для удовлетворения потребностей роста может быстро отразиться на чистой прибыли ».
Как создать эту технологию с учетом масштабируемости?
Создание масштабируемых технологий начинается с корпоративной культуры. Мы стремимся нанимать разработчиков, которые могут рассуждать о сложных системах и создавать среду разработки, в которой ценится долгосрочное мышление.Мы развиваем это мышление посредством открытой совместной разработки и итеративного процесса проверки кода, при котором мы поощряем масштабируемость и ремонтопригодность.
Кроме того, мы используем обширный вычислительный кластер для исследований и разработок. Это органично способствует модульному дизайну за счет улучшения параллелизма в кластере и повышения производительности. Поскольку в производственной среде мы запускаем одно и то же программное обеспечение, эти аспекты масштабируемости хорошо переносятся и в рабочую среду. Между тем, набор автоматических стресс-тестов позволяет постоянно анализировать производительность и возможности масштабирования.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости?
Основным элементом нашей технологии, который способствует масштабированию, является набор усовершенствованных библиотек, обеспечивающих эффективную связь между компонентами. Прямой доступ к кратким структурам данных через совместно используемую память или сетевой транспорт с нулевым копированием облегчает создание распределенных решений.
Мы встроили в наш сетевой стек запатентованные функции обеспечения надежности, обеспечивающие многоадресную передачу данных с использованием современного сетевого оборудования, которое обеспечивает высокоскоростное разветвление данных для потенциально огромного массива узлов обработки.Мы также создали специальные инструменты, которые ежедневно оценивают использование производственной среды и равномерно распределяют рабочую нагрузку.
Тем временем мы создали платформу уведомлений поверх Redis и инструменты визуализации с использованием Grafana, которые постоянно сообщают об использовании системы на уровне оборудования, операционной системы и программного обеспечения.
Просмотреть вакансии + узнать больше
20 спиц
Райан Фишер
ОСНОВАТЕЛЬ
По мнению Фишера, основателя агентства по развитию 20spokes, создание масштабируемой технологии должно быть простым.То есть, по его словам, инженеры должны сохранять свою архитектуру легкой и «легкой для обновления и изменения». Таким образом, продукты могут удовлетворить потребности пользователей сегодня и в будущем.
Опишите, что для вас значит масштабируемость.
Масштабируемость — это способность адаптироваться к изменениям и новым потребностям. В мире технологий это в основном связано с тем, сколько пользователей может управлять конкретным приложением или сайтом без проблем с производительностью. Важно помнить исходное определение, поскольку вы хотите, чтобы ваш продукт не только мог выдерживать повышенную активность, но и мог адаптировать свой набор функций для удовлетворения потребностей клиента.Это очень важно для выбранной вами технологии, поскольку она должна быть гибкой и устранять препятствия, мешающие изменениям.
Во время разработки один из лучших способов улучшить масштабирование — это не инструменты, а экспертные оценки ».
Как вы строите свою технологию с учетом масштабируемости?
Построение в масштабе делает все просто. Все основные фреймворки, используемые сегодня, прекрасно масштабируются — когда возникают проблемы с масштабированием, это, как правило, связано с тем, как был спроектирован продукт.Во многих случаях продукт может быть чрезмерно спроектирован, что приводит к проблемам масштабирования не только из-за требований к серверу, но и из-за создания новых функций.
Сохранение простоты означает создание независимых и небольших компонентов, что упрощает их обновление и изменение. То же самое можно сделать и с серверной архитектурой.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости?
Мы используем такие сервисы, как Datadog, для мониторинга производительности.Набор инструментов Google Firebase улучшается и очень полезен для мониторинга производительности мобильных приложений.
Во время разработки один из лучших способов улучшить масштабирование — это не инструменты, а экспертные оценки. Перед объединением и развертыванием весь наш код проходит экспертную оценку, чтобы убедиться, что он соответствует нашим стандартам.
Просмотреть вакансии + узнать больше
Сфера
Альбион Х.
ПРОГРАММНЫЙ АРХИТЕКТОР
Sphera, компания, занимающаяся разработкой программного обеспечения для управления рисками, не может позволить себе, чтобы ее платформы испытывали даже момент простоя.Вот почему команда инженеров обратилась к Microsoft Azure, надежной технологии, которую, по словам Albion, имеет все необходимое для масштабирования и поддержки каждого из ее продуктов. «Использование управляемых и проверенных технологий позволяет нам сохранять сосредоточенность наших команд на более творческих начинаниях и создании ценности для бизнеса», — сказал Альбион.
Почему масштабируемость важна для создаваемой вами технологии?
Наша цель — сделать SpheraCloud лучшей платформой для повышения операционной эффективности SaaS.Наши клиенты работают по всему миру с десятками тысяч пользователей — они полагаются на наше программное обеспечение для управления операциями на своих предприятиях и визуализации рисков в режиме реального времени. В этой среде даже очень небольшие простои могут привести к серьезным сбоям в работе и увеличению риска.
Даже очень небольшие простои могут привести к серьезным сбоям в работе и увеличению риска ».
Как создать эту технологию с учетом масштабируемости?
Люди — самая важная часть масштабной головоломки.Мы убедились, что ясность ролей и обязанностей имеет решающее значение для успеха масштабных инициатив. Отсутствие ясности обычно приводит к тому, что что-то не выполняется, потому что никто не считает, что он владеет им, или к тому, что несколько команд разрабатывают одну и ту же функцию без какой-либо координации. Последний сценарий не только тратит впустую деньги, но также может вызвать длительное недовольство между командами и подорвать моральный дух сотрудников.
После исследований в области организационного поведения наш инженерный отдел организован в «группы» не более чем из пяти человек для максимального вовлечения и сотрудничества.Масштабирование межкомандного сотрудничества и общения происходит через главы и гильдии, как это популяризировано Spotify.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости?
Наше программное обеспечение работает в Microsoft Azure, и мы стремимся использовать его основные возможности для обеспечения масштабируемости и надежности. SpheraCloud состоит из нескольких модулей, которые легко интегрируются друг с другом, создавая ощущение единой сплоченной платформы. Они развернуты в службе приложений Azure, что позволяет нам автоматически масштабировать каждый модуль по горизонтали на основе показателей нагрузки и производительности.
Мы храним наши данные в базе данных SQL Azure, которая может масштабироваться и поддерживать даже самые требовательные веб-приложения. Мы пользуемся преимуществами этой архитектуры, чтобы направлять все наши наиболее требовательные операции «чтения», такие как создание отчетов или поиск, на реплики «только для чтения».
Мы используем кэш Azure для Redis, полностью управляемое хранилище кэша в памяти для данных сеанса, таких как файлы cookie пользователя, роли и разрешения, а также ресурсы приложения. Redis дает нам время отклика менее миллисекунды и снижает нагрузку на базу данных, обеспечивая еще большую масштабируемость.
Просмотреть вакансии + узнать больше
Carminati Consulting
Бретань Карминати
ПРЕЗИДЕНТ
Когда началась пандемия, Carminati Consulting пришлось масштабировать свой продукт ImmuwareTM, чтобы удовлетворить потребности клиентов здравоохранения, пострадавших от COVID-19, и сделать это быстро. Карминати сказал, что, поскольку программное обеспечение было разработано с учетом индивидуальных требований соответствия для каждого клиента, они смогли быстро создать новые функции для поддержки администраторов учреждений, контролирующих болезнь.
Почему масштабируемость важна для создаваемой вами технологии?
Наш продукт SaaS, ImmuwareTM, представляет собой комплексное решение для здоровья сотрудников и профессионального здоровья. После пандемии COVID-19 мы быстро настроили продукт для удовлетворения требований постоянно меняющейся среды медицинских организаций, которые борются за безопасность медицинских работников во время пандемии. Мы не смогли бы обслуживать наших новых или существующих клиентов, если бы не наша гибкая и масштабируемая платформа.
Мы не смогли бы обслуживать наших новых или существующих клиентов, если бы не наша гибкая и масштабируемая платформа ».
Как создать эту технологию с учетом масштабируемости?
С самого начала ImmuwareTM создавался как онлайн-сообщество для клиентов из сферы здравоохранения, а это означает, что задача организации — обеспечить соответствие своих сотрудников определенным видам деятельности, связанной со здравоохранением.Таким образом, мы обеспечили сотрудникам, руководителям и администраторам по охране труда доступ к необходимым данным, отчетам и информационным панелям для обеспечения соблюдения нормативных требований.
С момента первоначального внедрения мы масштабировали ImmuwareTM для конкретных нишевых ролей, таких как администраторы COVID-19, назначенные для наблюдения за мониторингом симптомов. Поскольку ImmuwareTM был разработан с понятием «типы записей», то есть у каждого клиента разные требования соответствия и, следовательно, разные типы записей, которые необходимо отслеживать, мы можем легко предложить индивидуальное и быстрое развертывание для клиентов, просто ищущих конкретную запись. типа «ежедневные проверки здоровья на COVID-19.”
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости?
Облачный хостингAzure очень важен для нас. Без веб-служб Azure мы не смогли бы легко масштабироваться во время пиковых нагрузок и не смогли бы интегрироваться с внешними системами.
Просмотреть вакансии + узнать больше
Автомобиль
Брэд Смит
ДИРЕКТОР ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
При определении требований к масштабируемости системы команда Брэда Смита в Automox всегда начинает с проектирования.Директор по разработке программного обеспечения сказал, что он думает о масштабируемости не только как о приложении или системе, но и о том, как это относится ко всей организации. Смит держит свою организацию впереди всех, прося инженеров использовать тесты и показатели для принятия решений и никогда не пытаться чрезмерно компенсировать производительность и масштабирование.
Опишите своими словами, что для вас значит масштабируемость.
Масштабируемость может быть громким словом.Я думаю, что большинство людей называют это приложением или системой, которая увеличивает производительность пропорционально службам, которые берут на себя эту нагрузку. Но вы должны думать не только о масштабировании веб-сервисов; организация также должна иметь возможность масштабироваться. Если услуга считается масштабируемой, нам нужны люди и процессы, чтобы поддерживать эту услугу на опережение.
Здесь, в Automox, масштабируемость является важной частью того, как мы строим нашу инфраструктуру и организации и развертываем наши приложения.
Клиенты полагаются на нас, чтобы убедиться, что на их конечных точках установлены последние исправления.Мы должны быть в состоянии удовлетворить их спрос. Каждый раз, когда Microsoft выпускает большой вторник обновлений, наша система должна быть в состоянии реагировать на дополнительную нагрузку, не подводя наших клиентов. Большую часть времени мы принимаем вызов. Но бывают моменты, когда мы терпим неудачу. Неудача — это нормально, если вы извлечете уроки из нее и в следующий раз заставите систему масштабироваться дальше.
Как создать эту технологию с учетом масштабируемости?
При определении требований к масштабируемости системы мы всегда начинаем с сеанса проектирования.Мы собираемся вместе и проводим мозговой штурм. У команды есть возможность обсудить потенциальные проблемы или подводные камни и определить, как выглядит успех. Каждая заинтересованная сторона представлена за столом.
Существует естественная тенденция делать приложения и системы пуленепробиваемыми, но лучше вносить инкрементные изменения, выпускать их, измерять их и принимать решения на основе данных в будущем. Мы используем тесты и показатели, чтобы принимать решения, и стараемся держаться подальше от ветра.
В стартапе первостепенное значение имеет компромисс между производительностью и масштабируемостью.Никогда не пытайтесь чрезмерно компенсировать производительность и масштаб. В девяноста процентах случаев вам это не понадобится. Плата за ресурсы, которые вы, возможно, никогда не будете использовать, не обеспечивает масштабируемости. Это заставит вас медленно реагировать, когда возникнет следующая потребность в масштабировании.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Некоторые из инструментов, которые мы используем, чтобы упростить масштабирование, — это Kubernetes, эффективные метрики с Prometheus и сервисы, размещенные на AWS, такие как RDS.Kubernetes дает нам возможность масштабировать наши сервисы (монолитные и микросервисы) с автоматизацией и небольшими усилиями.
Мы в значительной степени полагаемся на метрики для оценки работоспособности наших приложений и сервисов. Prometheus вместе с Таносом предлагает масштабируемую серверную часть метрики, которая будет расти вместе с нами.
Когда дело доходит до наших хранилищ данных, мы обычно используем размещенные предложения, такие как RDS от Amazon. Каждый раз, когда вы можете доверить один аспект своего стека проверенному партнеру, это на одну вещь меньше, на которую вам придется тратить время и деньги.Если команде не нужно беспокоиться о масштабировании или резервном копировании PostgreSQL, это победа.
Наконец, мы используем Jira для управления проектами и отслеживания работы. Если вы не понимаете, сколько работы может выполнить ваша команда, вы никогда не узнаете, как и когда масштабировать свою команду. Точность в отношении плановой и внеплановой работы является ключом к предсказанию того, когда следует увеличивать или уменьшать масштаб.
Просмотреть вакансии + узнать больше
Максвелл
Бен Райт
СТАРШИЙ ИНЖЕНЕР ПО ПРОГРАММНОМУ ОБЕСПЕЧЕНИЮ
Без прозрачной и поддерживаемой кодовой базы старший инженер-программист Бен Райт сказал, что сотрудники Maxwell не смогут достичь своей конечной цели: открыть процесс домовладения.Для этого команда Райта сосредоточила свои усилия на создании клиентской инфраструктуры компании с многократно используемой компонентной архитектурой. Они также создают внешнюю библиотеку компонентов, к которой каждый член команды может получить доступ и на которую может положиться.
Опишите своими словами, что для вас значит масштабируемость.
Для интерфейсного инженера масштабируемость означает создание обслуживаемой базы кода, которая может расти с привлечением дополнительных пользователей и разработчиков. Это важно для Maxwell как компании и для наших технологий, особенно потому, что, в конечном итоге, наша миссия — дать людям возможность сделать ипотечное кредитование более простым и доступным.Как вы понимаете, повышение прозрачности достижимо и эффективно только при увеличении числа пользователей и клиентов. Нам нужны данные и масштаб, чтобы иметь большое влияние в этой огромной отрасли, поэтому масштабируемость имеет решающее значение. Если мы не будем думать о масштабируемости, мы не добьемся успеха как компания.
Как создать эту технологию с учетом масштабируемости?
Мы сосредоточились на создании клиентской части с многократно используемой компонентной архитектурой. Мы создали внешнюю библиотеку компонентов, которая может служить источником достоверной информации при разработке, проектировании и принятии решений о продуктах.Библиотека позволяет нам поддерживать согласованный дизайн в нашем пользовательском интерфейсе / пользовательском интерфейсе, устанавливать шаблоны в коде наших компонентов и предоставлять рекомендации новым разработчикам по созданию новых страниц или соответствующих компонентов.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Мы используем ESLint и RuboCop для обеспечения единого стиля кода, тщательные проверки кода (как асинхронные, так и личные) для обеспечения качества кода, тщательное автоматическое тестирование для предотвращения ошибок и непредвиденных последствий и многое другое.
Просмотреть вакансии + узнать больше
Восстание артефактов
Остин Мюллер
СТАРШИЙ ИНЖЕНЕР ПО ПРОГРАММНОМУ ОБЕСПЕЧЕНИЮ
Когда дело доходит до масштабируемости сайта, старший инженер-программист Artifact Uprising Остин Мюллер видит свою работу в том, чтобы на производительность не влияло количество посетителей сайта в любой конкретный день. Чтобы воплотить это видение в жизнь, его команда использует AWS S3 и Lambda в дополнение к автоматическому масштабированию кластеров Kubernetes для обработки настраиваемых заказов цифровых фотографий по мере их поступления.
Опишите своими словами, что для вас значит масштабируемость.
Поскольку мы производим и продаем товары, активность на нашем сайте сильно зависит от времени суток и сезона. По этой причине масштабируемость должна быть на первом месте.
Масштабируемость означает наличие надежного сервиса, способного обслуживать два или два миллиона клиентов без простоев, перерывов или задержек в обслуживании. Во-вторых, мы хотим убедиться, что наша инфраструктура может увеличиваться или уменьшаться без ручного контроля.Наша цель — не тратить зря ресурсы, если нашим сайтом пользуются только два человека, и не допустить, чтобы наш клиентский опыт пострадал, если наш сайт используют два миллиона человек.
Как создать эту технологию с учетом масштабируемости?
Часть нашего повседневного мышления — это заранее думать о том, что мы создаем, и как это будет вести себя под нагрузкой. Это означает проектирование нашей инфраструктуры и приложений таким образом, чтобы они могли автоматически увеличиваться и уменьшаться для обработки всплесков трафика.
Наша команда прилагает много усилий для изучения и внедрения передовых методов масштабирования. Мы используем Amazon Web Services (AWS), в котором есть замечательные функции масштабируемости, для многих частей нашей инфраструктуры. Мы хотим быть уверены в том, что у нас есть все необходимое, чтобы использовать эти услуги в полной мере.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Одной из важнейших функций нашего приложения является возможность загружать и хранить фотографии.Эта служба должна иметь возможность масштабирования, тем более что для нее требуется большой сетевой трафик. Мы стараемся свести время ожидания загрузки к минимуму, даже если тысячи людей загружают фотографии одновременно.
Мы можем использовать возможности AWS S3 и Lambda для предоставления бесконечно масштабируемого сервиса, который не ухудшается, независимо от того, сколько фотографий загружается. Мы также используем автоматическое масштабирование кластеров Kubernetes для обработки заказов по мере их поступления. По мере того, как в очереди появляется все больше заказов, мы можем автоматически запускать новые серверы, чтобы гарантировать быструю и эффективную обработку заказов.
Просмотреть вакансии + узнать больше
StackHawk
Тофер Ламей
СТАРШИЙ ИНЖЕНЕР ПО ПРОГРАММНОМУ ОБЕСПЕЧЕНИЮ
Старший инженер-программист Тофер Лами подчеркивает масштабируемость в своей работе в StackHawk из-за ее роли в создании высококачественного программного продукта для клиентов. По словам Лами, для того, чтобы профессионалы-разработчики могли работать с кодовой базой максимально продуктивно, через конвейер CI / CD должно проходить определенное количество наборов изменений.Не только это, но и процесс и архитектура тестирования / развертывания должны функционировать без сбоев.
Опишите своими словами, что для вас значит масштабируемость.
Масштабируемость для меня означает, что поставляемое программное обеспечение соответствующим образом масштабируется на нескольких уровнях. Возможность легко выявлять и устранять проблемы среды позволяет каждому члену команды эффективно работать с кодовой базой.
Когда речь идет о программном продукте, за который люди будут платить деньги, масштабируемость относится к тому, как этот продукт справится с рабочей нагрузкой своих пользователей (людей или нет).Продукт должен предсказуемо масштабироваться с точки зрения производительности и использования ресурсов для обеспечения функциональности. Такие факторы, как мониторинг использования ресурсов и ключевых показателей системы, разработка сервисов для распределения рабочих нагрузок ресурсов, использование проверенных технологий, а также написание и профилирование высокопроизводительного кода — все это способствует масштабируемости.
На ранних этапах развития компании важнее проявлять гибкость и понимать, что это за продукт. На этом этапе нет необходимости создавать масштабные проекты для Facebook.Однако по мере роста компании необходимо определять потребности и ожидания в отношении масштабируемости и учитывать их в бюджете.
Как создать эту технологию с учетом масштабируемости?
У нас около полдюжины инженеров, поэтому нам нужна некоторая масштабируемость процесса разработки. Мы должны учитывать, что несколько инженеров одновременно работают над одной и той же кодовой базой.
Что касается программного обеспечения, мы думаем о масштабируемости как о требовании при планировании новых функций.Поскольку требования к функциональности обсуждаются, мы говорим о потребностях в масштабируемости. Некоторые общие вопросы в рамках обсуждения включают: Что нужно масштабировать в этом сценарии? Что сломается в первую очередь по мере увеличения использования этой функциональности? Какие ресурсы затронуты?
Затем, по мере реализации функциональности, мы совместно работаем над вариантами дизайна и вариантами выбора. Наш процесс разработки предусматривает автоматическое тестирование и ручную проверку кода, помогающую выявлять проблемы. Затем мы развертываем изменения в средах, которые пытаются отразить производственную среду, включая мониторинг и оповещения.Таким образом, мы можем быть уверены, что новые изменения масштабируются соответствующим образом.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Чтобы помочь масштабировать процессы разработки, мы используем GitFlow, чтобы упростить управление наборами изменений в наших проектах. Весь наш процесс сборки / развертывания автоматизирован с использованием сочетания Docker Compose, Kubernetes и AWS CodeBuild / ECS. В рамках GitFlow мы выполняем слияния с ветвями на основе автоматических тестов и одноранговых проверок кода. Мы внедряем изменения в тестовые среды, которые точно отражают производственную среду, поэтому у нас есть высокая степень уверенности в том, что масштабируемость не пострадает.
Некоторые технологии, которые мы используем, потому что знаем, что они масштабируются, — это Spring Boot, Python, Kotlin, AWS RDS / PostgresSQL и Redis. Кроме того, мы используем Logz.io и Grafana для отслеживания и обработки предупреждений в наших системах. Наши внутренние службы взаимодействуют друг с другом с помощью gRPC, а не JSON / REST. gRPC — это хорошо масштабируемая технология Google, которая реализует RPC без сохранения состояния с использованием не зависящих от языка определений, называемых protobufs. GRPC предоставляет способ определения и совместного использования общих определений сообщений и методов RPC по всем направлениям.Мы также отказались от Kubernetes, потому что мы можем легко настроить правила масштабирования сервисов в зависимости от использования ресурсов. Поскольку наши службы не имеют состояния, относительно легко запускать новые экземпляры для обработки рабочей нагрузки.
Просмотреть вакансии + узнать больше
Лапа грузовика для жидкостей
Леонардо Амигони
CTO
Технический директорFluid Truck Share Леонардо Амигони ценит скомпилированный язык программирования Google Golang из-за его легкости.Он сказал, что это позволило его команде сосредоточиться на бизнес-потребностях общественной платформы для совместного использования грузовиков, а не на собственных технологиях. Fluid Truck Share построен на архитектуре микросервисов, поэтому команда инженеров может масштабировать отдельные части системы.
Опишите своими словами, что для вас значит масштабируемость.
Масштабируемость — это характеристика программной системы или организации, которая описывает ее способность хорошо работать при повышенной рабочей нагрузке.Хорошо масштабируемая система может поддерживать уровень эффективности при повышенных эксплуатационных требованиях.
Масштабируемость становится все более актуальной для Fluid Truck по мере того, как мы привлекаем больше клиентов и выходим на новые рынки. По этой причине мы отошли от традиционной парадигмы монолитного приложения в пользу микросервисной архитектуры. В традиционном монолитном приложении все системные функции записаны в одном приложении. Часто они группируются по типу функции, контроллерам или службам.Например, система может сгруппировать всю регистрацию пользователей и управление ими в рамках модуля авторизации. Этот модуль может содержать собственный набор сервисов, репозиториев или моделей. Но в конечном итоге они по-прежнему содержатся в единой кодовой базе приложения.
Когда определенные области кодовой базы нуждаются в масштабировании с увеличением пользовательского спроса, монолитные приложения часто требуют масштабирования всего приложения. С помощью микросервисов разделение компонентов системы позволяет частям системы масштабироваться индивидуально.
Как создать эту технологию с учетом масштабируемости?
Fluid Truck адаптировал Golang и Kubernetes для наших потребностей в микросервисе. Легкость Golang позволила нам сосредоточиться на потребностях нашего бизнеса, а не на наших технологиях. Его простота позволила нам расширить нашу инфраструктуру и поддерживать нашу платформу, объединяя разработчиков с любым опытом.
Более того, мы выбрали Go из-за его простой модели параллелизма.В среде, где параллелизм и параллелизм являются обязательными, подпрограммы Go позволили нам масштабировать процессы между несколькими ядрами процессора, используя более простую многопоточную модель выполнения, чем та, что была у нас раньше.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Kubernetes позволяет нам управлять нашей инфраструктурой, развертывая не зависящие от машины микросервисы, которые можно реплицировать где угодно.Это инструмент оркестровки контейнеров, который обеспечивает масштабирование нашей платформы в зависимости от спроса. Микросервисы легко масштабируются с помощью комбинации балансировщиков нагрузки и наборов репликации. Мы стремились автоматизировать масштабируемость нашей платформы за счет контейнеризации наших микросервисов. Kubernetes был тем инструментом, который помог нам справиться с этой задачей.
Просмотреть вакансии + узнать больше
Торговый стол
Крис Янсен
СТАРШИЙ ИНЖЕНЕР ПО ПРОГРАММНОМУ ОБЕСПЕЧЕНИЮ
Когда шесть лет назад старший инженер-программист Крис Янсен впервые присоединился к The Trade Desk, компания, занимающаяся рекламными технологиями, обрабатывала два миллиона запросов в секунду во всем мире.Сейчас они обрабатывают до 11 миллионов. Янсен сказал, что, помимо других стратегий, его команда добилась большого успеха в рефакторинге собственного кода, чтобы уменьшить сложность и оптимизировать использование памяти.
Опишите своими словами, что для вас значит масштабируемость.
Когда я думаю о масштабируемости, я думаю о буквально масштабируемости нашей платформы. Масштабируемость важна для The Trade Desk, потому что, как мы часто говорили внутри компании, мы сделали только 2 процента.Рекламная отрасль — это отрасль с оборотом 600 миллиардов долларов, и мы всегда расширяем свой кусок пирога. Чтобы успешно расти так же быстро и быстро, как мы, мы должны как можно раньше задуматься о масштабируемости. Он встроен в то, как мы думаем о каждой функции, которую мы здесь разрабатываем и создаем.
Как создать эту технологию с учетом масштабируемости?
Распределенная архитектура — это фундаментальный строительный блок для масштабируемости. Это позволяет каждому крупному компоненту масштабироваться независимо по мере нашего роста.Например, в Trade Desk компоненты, которые обрабатывают входящие рекламные возможности или запросы ставок, должны были масштабироваться быстрее, чтобы учесть новые источники инвентаря, такие как подключенное телевидение. Сравните это с нашим пользовательским интерфейсом, где рост пользователей был более линейным.
Другой основной стратегией для нас является частый анализ производительности центрального процессора и памяти, чтобы увидеть, что мы можем улучшить. Мы добились большого успеха в рефакторинге нашего собственного кода, чтобы упростить его и оптимизировать использование памяти.
Какие инструменты или технологии использует ваша команда для поддержки масштабируемости и почему?
Мы все чаще обращаемся к контейнерным компонентам и инструментам, таким как Kubernetes и Airflow, для управления и масштабирования. Контейнеры проще в управлении и более гибкие, чем выделенные серверы. Мы также используем Spark для более точной аналитики и машинного обучения.
Просмотреть вакансии + узнать больше
Ответы отредактированы для большей ясности.Изображения через перечисленные компании.Масштабируемость — обзор | Темы ScienceDirect
Масштабируемость
Масштабируемость в системе IoT должна поддерживать как можно больший спектр приложений, устройств, рабочих нагрузок и сложности — балансировка бизнес-требований, таких как экономическая эффективность, с эксплуатационными требованиями к гибкости и возможностью повторного использования компонентов для различных Сервисы. Например, те же компоненты, которые используются в очень простом приложении, также должны использоваться в очень большой сложной распределенной системе.В идеале компоненты можно быстро настраивать и масштабировать (даже во время работы).
Масштабирование может означать добавление все большего количества конечных точек в систему IoT. Это может означать увеличение скорости, с которой данные поступают к конечным точкам, от них или обрабатываются ими, или масштабирование может быть связано с количеством полуавтономных систем IoT, которыми управляют из одной инфраструктуры. Например, решение с несколькими арендаторами может позволить многим клиентам совместно использовать одну услугу или инфраструктуру, вместо того, чтобы управлять выделенной услугой или экземпляром услуги для каждого нового клиента: гораздо менее масштабируемое решение.
Плохая масштабируемость создает множество рисков в IoT, включая влияние на доступность из-за нехватки емкости и неспособности системы управления справляться с управляемыми группами. Поскольку эти функции являются более сложными, чем проблемы безотказной работы и несанкционированного удаления, мы поместили их в класс требований совместимости, гибкости и промышленного дизайна.
Кроме того, система IoT может быть спроектирована с учетом масштабируемости в качестве основного требования, но при этом будут неверно представлены детали из-за неполной перспективы и подходящих вариантов использования, на которых основываются оценки.
В качестве примера распространенной ошибкой Enterprise IT является разработка программного или аппаратного обеспечения для данной задачи в изолированной среде, предполагая, что никто никогда не будет пытаться использовать данные, программное обеспечение или оборудование в другой среде или для новых , операционные или дополнительные приложения и услуги. Но вот, несколько лет спустя кто-то находит умный способ использовать данные или программное обеспечение совершенно неожиданным образом, но в другой, менее изолированной и менее безопасной среде.Поскольку программное обеспечение никогда не предназначалось для работы в менее гигиеничной операционной среде , результатом является функционально работоспособная, но небезопасная система.
Критическая точка зрения на масштабируемость IoT — это предвосхищение того, чего вы еще не могли себе представить. Существуют ли технические требования, которые могут упростить интеграцию имеющейся системы IoT с другими системами? Возможно, масштабируемость может быть связана не с вашей системой, а с масштабируемостью другой системы, которая хочет взаимодействовать с вашей системой или использовать ее.
Будет очень сложно предсказать, как устройство или актив Интернета вещей (программное обеспечение, оборудование, система или услуга) будет объединяться, переупаковываться, настраиваться, использоваться и повторно использоваться после запуска. Небольшие изменения в программном обеспечении могут позволить использовать совершенно новые сервисы и интерфейсы с системами, которые не предполагались при проектировании системы, превращая предположительно небольшую, ориентированную на нишу систему IoT в очень большую систему IoT.