Расчет глубины индекса
Индексы в большинстве случаев (по крайней мере в Firebird и InterBase) представляют собой страничные B*-деревья. Скорость поиска ключа в дереве напрямую зависит от количества страниц, просматривая которые сервер доберется до указателя на запись.
Например, при помощи GSTAT вы получили статистику по БД, и один из индексов выглядит следующим образом (размер страницы для этой БД – 8192 байт):
Index RDB$PRIMARY33 (0)
Depth: 3, leaf buckets: 469, nodes: 88926
Average data length: 36.00, total dup: 0, max dup: 0
Fill distribution:
0 — 19% = 0
20 — 39% = 0
40 — 59% = 0
60 — 79% = 1
80 — 99% = 468
Depth – текущая глубина индекса
Leaf buckets – листовых страниц дерева. Т. е. кол-во страниц, на которых находятся ссылки на записи.
Получить среднее количество ключей на странице можно поделив число nodes на leaf buckets. Для примера это 88926 / 469 = 190.
Подсчет количества страниц предыдущего уровня (страницы указателей, которые содержат ссылки на страницы leaf buckets) – число leaf buckets – это фактически число ключей предыдущего уровня. У нас оно равно 469. Нужно умножить это число на среднюю длину ключа, и поделить на размер страницы.
Самый первый уровень дерева индекса всегда содержит одну страницу.
Предельным количеством ключей в первой странице является 190 (8192 / 43). Таким образом, глубина индекса, равная 3, будет сохраняться до тех пор, пока во втором уровне 190 страниц. Соответственно, количество страниц третьего уровня равно (190 * 8192) / 43 = 36198. В выражении количества записей это равно
Таким образом, глубина индекса, равная 3, будет сохраняться до тех пор, пока во втором уровне 190 страниц. Соответственно, количество страниц третьего уровня равно (190 * 8192) / 43 = 36198. В выражении количества записей это равно
(36198 * 8192) / 43 = 6 миллионов, 896 тысяч 140 записей.
Разумеется, мы предполагаем, что страницы заполнены полностью. На самом деле это не так. При расчетах нужно вводить средний процент заполнения страниц, который в худшем случае (для всех страниц) можно предположить равным 70 %. Т. е. там, где мы делим размер страницы на средний размер ключа, нужно результат умножить на 0.7.
Первая страница = 190 ключей * 0.7 = 133 ключа (страницы второго уровня)
133 страницы второго уровня * 8192 / 43 * 0.7 = 17737 страниц третьего уровня (leaf buckets)
кол-во записей = 17737 * 8192 / 43 * 0.7 = 2 миллиона 365 тысяч 374 записи.

Примечание. Можно посчитать и максимальное количество ключей, при котором глубина индекса будет оставаться равной четырем. Это
2365374 * 8192 / 43 * 0.7 = 315 миллионов 441 тысяч 876 записей. Таким образом, производительность выборок с использованием индекса будет одинаковой при кол-ве ключей от 2.3 миллиона до 315 миллионов.
Какие бывают индексы примеры. Почтовый индекс
После прочтения многочисленной литературы по СУБД, некоторого опыта работы с MongoDB и листанию статей по базам данных у меня созрело желание сделать cheatsheet по индексам применительно к БД. А индексирование — достаточно интересный раздел теории баз данных, а главное — нужный в практике. Вообще-то говоря, золотое правило индексирования — иметь индекс под каждый запрос.
Вообще-то говоря, золотое правило индексирования — иметь индекс под каждый запрос.
По порядку сортировки
- Упорядоченные — индексы, в которых элементы поля(столбца) упорядочены.
- Возрастающие
- Убывающие
- Неупорядоченные — индексы, в которых элементы неупорядочены.
По источнику данных
- Индексы по представлению (view).
- Индексы по выражениям — например в PostgreSQL.
По воздействию на источник данных
- Некластерный индекс — наиболее типичные представители семейства индексов. В отличие от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки. Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя: информацию об идентификационном номере файла, в котором хранится строка; идентификационный номер страницы соответствующих данных; номер искомой строки на соответствующей странице; содержимое столбца.

- Кластерный индекс — Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту. Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными.

По структуре
- B*-деревья
- B+-деревья
- B-деревья
- Хеши.
По количественному составу
- Простой индекс (индекс с одним ключом) — строится по одному полю.
Составной (многоключевой, композитный) индекс — строится по нескольким полям. Важен порядок следования полей (например в MongoDB).
Индекс с включенными столбцами — Некластеризованный индекс, дополнительно содержащий кроме ключевых столбцов еще и неключевые. - Главный индекс (индекс по первичному ключу) — это тот индексный ключ, под управлением которого в данный момент находится таблица. Таблица не может быть отсортирована по нескольким индексным ключам одновременно. Хотя, если одна и та же таблица открыта одновременно в нескольких рабочих областях, то у каждой копии таблицы может быть назначен свой главный индекс.

По характеристике содержимого
- Уникальный индекс — состоит из множества уникальных значений поля.
Плотный индекс (NoSQL) — индекс, при котором, каждом документе в индексируемой коллекции соответствует запись в индексе, даже если в документе нет индексируемого поля. - Разреженный индекс (NoSQL) — тот, в котором представлены только те документы, для которых индексируемый ключ имеет какое-то определённое значение (существует).
- Пространственный индекс — оптимизирован для описания географического местоположения. Представляет из себя многоключевой индекс состоящий из широты и долготы.
- Составной пространственный индекс — индекс, включающий в себя кроме широты и долготы ещё какие-либо мета-данные (например теги). Но географические координаты должны стоять на первом месте.
- Хэш-индексы — предполагают хранение не самих значений, а их хэшей, благодаря чему уменьшается размер(а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием HASH-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей.
Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». - Битовый индекс (bitmap index) — метод битовых индексов заключается в создании отдельных битовых карт (последовательность 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует строка с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства.
- Обратный индекс (reverse index) — это тоже B-tree индекс но с реверсированным ключом, используемый в основном для монотонно возрастающих значений(например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска.
- Функциональный (function-based) индекс (индекс по вычисляемому полю ) — индекс, ключи которого хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений. Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)
- Первичный индекс — уникальный индекс по полю первичного ключа.
- Вторичный индекс — индекс по другим полям (кроме поля первичного ключа).
- XML-индекс — вырезанное материализованное представление больших двоичных XML-объектов (BLOB) в столбце с типом данных xml.
 Представляет из себя многоключевой индекс состоящий из широты и долготы.
Представляет из себя многоключевой индекс состоящий из широты и долготы.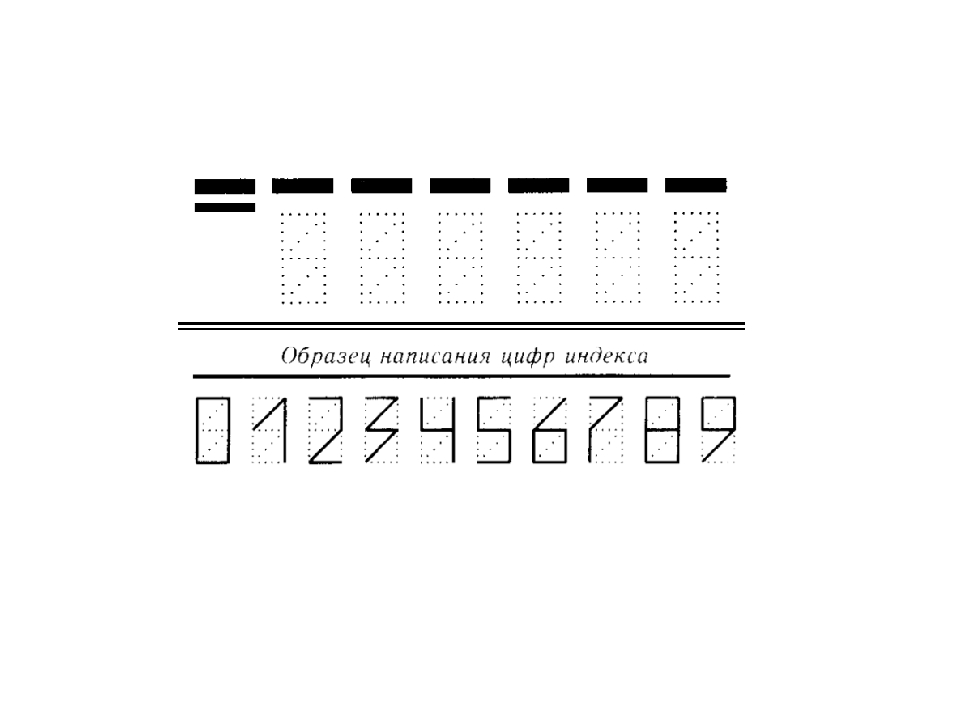
 Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений. Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)
Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений. Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)По механизму обновления
- Полностью перестраиваемый — при добавлении элемента заново перестраивается весь индекс.
- Пополняемый (балансируемый) — при добавлении элементов индекс перестраивается частично (например одна из ветви) и периодически балансируется.

По покрытию индексируемого содержимого
- Полностью покрывающий (полный) индекс — покрывает всё содержимое индексируемого объекта.
- Частичный (partial) индекс — это индекс, построенный на части таблицы, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса.
- Инкрементный (Delta) индекс — индексируется малая часть данных(дельта), как правило, по истечении определённого времени. Используется при интенсивной записи. Например, полный индекс перестраивается раз в сутки, а дельта-индекс строится каждый час. По сути это частичный индекс по временной метке.
- Real-time индекс — особый вид delta индекса в Sphinx, характеризующийся высокой скоростью построения. Предназначен для часто-меняющихся данных.
Индексы в кластерных системах
- Глобальный индекс — индекс по всему содержимому всех shard’ов (секций).
- Сегментный индекс — глобальный индекс по полю-сегментируемому ключу (shard key). Используется для быстрого определения сегмента(shard’а), на котором хранятся данные в процессе маршрутизации запроса в кластере БД.
- Локальный индекс — индекс по содержимому только одного shard’а.
 Используется для быстрого определения сегмента(shard’а), на котором хранятся данные в процессе маршрутизации запроса в кластере БД.
Используется для быстрого определения сегмента(shard’а), на котором хранятся данные в процессе маршрутизации запроса в кластере БД.Если есть неточности, коррективы — пишите в комменты. Надеюсь кому-то будет полезным эта «шпаргалка».
Определение
Индекс Морса
Индекс подгруппы
Индекс (поисковой машины)
Индекс (базы данных)
Ветро-холодовой индекс
Почтовый индекс
Индекс дистрибуции
Биржевой индекс
Методы расчёта биржевых индексов
Индекс Доу-Джонса
Российские биржевые индексы
Индекс — относительный показатель роста или снижения агрегированных экономических параметров. Индексы используются для статистического изучения состояния и динамики экономики.
Индекс (лат. Index — список, реестр, указатель) — число (а иногда символ или набор символов) указатель места элемента в совокупности или показатель активности, производительности, развития или изменения чего-либо.
1. В математике:
Верхний (или нижний) индекс — число или символ который ставится чуть выше (или ниже) справа от другого символа, например An, читается «А энное», есть A с нижним индексом n.
Индекс Морса
Индекс подгруппы
Цикловой индекс
Индекс оператора
2. В информатике:
Индекс (информационные технологии), в том числе поисковой индекс
Индекс (поисковой машины)
Индекс (базы данных )
Index Librorum Prohibitorum
Биржевой индекс
Ветро-холодовой индекс
Почтовый индекс
Индекс автомобильных номеров
Индекс дистрибуции
Индекс цитирования
Индекс цитирования веб-сайтов
Индекс цитирования научных статей
Индекс/Досье на цензуру (журнал)
3. В медицине
Индекс массы тела
4. В фотографии
Отпечаток, на которым сведено, в сильно уменьшеном виде, множество снимков с пленки или цифрового носителя
Аналитический индекс — индекс, при помощи которого результат общего измерения сложного явления расчленяют в соответствии с отдельными компонентами этого явления или его факторами.
Индексное число — показатель соотношения одной величины с определенной базисной величиной, принятой за 100%.
Индекс Герфиндаля — индекс, измеряющий уровень влияния на рынке одного или нескольких продавцов. Индекс рассчитывается как сумма квадратов долей каждого продавца, действующего на рынке . Индекс Герфиндаля позволяет учесть степень влияния фирмы, доминирующей на рынке .
Индекс Гини — показатель неравномерности распределения доходов, определяемый сопоставления кривой Лоренца с диагональю, представляющей теоретическое равномерное распределение.
Индекс Морса
Индекс Морса невырожденной критической точки p гладкой функции f на многообразии M равен, по определению размерности максимального из подпространств касательного пространства TpM многообразия M в точке p, на котором гессиан отрицательно определен.
Это определение также имеет смысл и для дважды дифференцируемой по Фреше функции на бесконечномерном банаховом многообразии.
Индекс подгруппы
Индекс подгруппы H в группе G ― число классов смежности в каждом (правом или левом) из разложений группы G по этой подгруппе H (в бесконечном случае ― мощность множества этих классов).
Индекс подгруппы H в группе G обычно обозначается .
Индекс (поисковой машины)
Индексирование, совершаемое поисковой машиной — процесс собирания, разбора и сохранения данных с целью облегчить быстрый и точный поиск информации. Дизайн индекса включает междисциплинарные понятия из лингвистики, когнитивной психологии, математики, информатики и физики. Альтернативное название для этого процесса в контексте поисковых машин, разработанных, чтобы искать веб-страницы в Интернете, является индексацией Сети
Популярные движки сосредотачиваются на полнотекстовой индексации в онлайне, документов естественного языка. Мультимедийные документы, такие как видео и аудио и графика также могут участвовать в поиске.
Метапоисковые машины переиспользуют индексы других поисковых сервисов и не хранят локальный индекс, в то время как основанные на скешированных страницах поисковые машины надолго хранят как индекс, так и корпусы. В отличие от полнотекстовых индексов, частично-текстовые сервисы ограничивают глубину индексации, чтобы уменьшить размер индекса. Большие сервисы как правило выполняют индексацию в предопределенных временных рамках из-за необходимого времени и обработки затрат, в то время как поисковые машины основанные на агентах строят индекс в масштабе реального времени.
В отличие от полнотекстовых индексов, частично-текстовые сервисы ограничивают глубину индексации, чтобы уменьшить размер индекса. Большие сервисы как правило выполняют индексацию в предопределенных временных рамках из-за необходимого времени и обработки затрат, в то время как поисковые машины основанные на агентах строят индекс в масштабе реального времени.
Цель использования индекса — в улучшении скорости и быстродействия при поиске релевантных документов по поисковому запросу. Без индекса поисковая машина должна была бы сканировать каждый документ в корпусе, что потребовало бы большого количества времени и вычислительной мощности. Например, в то время как индекс 10 000 документов может быть опрошен в пределах миллисекунд, последовательный просмотр каждого слова в 10 000 больших документов мог бы занять часы. Дополнительное хранилище, требуемое для хранения индекса, а также значительное увеличение времени, требуемого для его обновления, являются компромиссом за экономию времени при поиске информации.
Индекс (базы данных)
Индекс (англ. Index) — объект базы данных, создаваемый с целью повышения производительности выполнения запросов. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному значению путем последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет находить нужную строку по заданному значению. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева. Некоторые СУБД расширяют возможности индексов введением возможности создания индексов по выражениям. Например, индекс может быть создан по выражению upper(last_name) и соответственно будет хранить ссылки, ключом к которым будет значение поля last_name в верхнем регистре. Кроме того, индексы могут быть объявлены как уникальные и как не уникальные. Уникальный индекс реализует ограничение целостности на таблице, исключая возможность вставки повторяющихся значений.
Кроме того, индексы могут быть объявлены как уникальные и как не уникальные. Уникальный индекс реализует ограничение целостности на таблице, исключая возможность вставки повторяющихся значений.
Ветро-холодовой индекс
Ветро-холодовой индекс — способ измерения жёсткости погоды, то есть субъективного ощущения человека при одновременном воздействии на него мороза и ветра.
Жёсткость погоды по ветро-холодовому индексу рассчитывается следующим образом: к температуре воздуха в градусах цельсия прибавляется скорость ветра , помноженная на коэффициент жёсткости. Для удобства использования различные комбинации температуры воздуха и скорости ветра собирают в таблицу жёсткости погоды по ветро-холодовому индексу.
Почтовый индекс
Почто́вый и́ндекс — последовательность букв или цифр, добавляемая к почтовому адресу с целью облегчения сортировки корреспонденции. В настоящее время подавляющее большинство национальных почтовых служб использует почтовые индексы.
Индекс дистрибуции
Показатель, характеризующий наличие продукта в торговых точках. Может рассчитываться для различных типов торговых точек (киоски, ларьки, открытые рынки, сети и др.), для различных регионов, городов, для различных категории.
Пример: индекс дистрибуции марки «Вики» в категории мороженое в Санкт-Петербурге составляет 65%. Это означает, что марка «Вики» продается в 65% магазинов Санкт-Петербурга, в которых представлена (продается) категория мороженое.
Индекс дистрибуции рассчитывается на основании регистрации наличия продукта в выборке торговых точек, репрезентативно отражающих общую генеральную совокупность торговых точек города (региона, страны). Генеральная совокупность оценивается путем проведения сенсуса.
Часто используется понятие индекса дистрибуции и цен (DPI-Distribution&Price index), в этом случае совместно с регистрацией наличия продукта в торговых точках регистрируется также его цена в этой торговой точке.
Биржевой индекс
Биржевой индекс — составной показатель изменения цен определённой группы ценных бумаг — «индексной корзины».
Как правило, абсолютные значения индексов не важны. Большее значение имеют изменения индекса с течением времени, поскольку они позволяют судить об общем направлении движения рынка, даже в тех случаях, когда цены акций внутри «индексной корзины» изменяются разнонаправлено. В зависимости от выборки показателей, биржевой индекс может отражать поведение какой-то группы ценных бумаг (или других активов) или рынка (сектора рынка) в целом.
Зачастую биржевые индексы являются основой одноимённых производных финансовых инструментов, которые используются для инвестиционных и спекулятивных целей.
На основании данных агентства Dow Johns & Co. Inc. на конец 2003 года в мире насчитывалось 2 315 биржевых индексов.
В конце названия биржевых индексов может стоять цифра, отображающая число акций, на основании которых рассчитывается индекс: CAC 40, Index Nikkei 225, S&P 500.
Первый биржевой индекс был разработан 3 июля 1884 в США журналистом газеты Wall Street Journal, известным финансистом, учредителем организации Dow Johns»s index & Company Чарльзом Доу. Индекс Dow»s index Transportation Average рассчитывался по 11 крупнейшим транспортным компаниям США . На сегодняшний день в него входят 20 компаний грузоперевозчиков.
Методы расчёта биржевых индексов
Различают несколько методов расчёта биржевых индексов:
Метод средней арифметической простой (невзвешенный)
Метод средней геометрической (композитный)
Метод средней арифметической взвешенной
Метод средней геометрической взвешенной
Метод средней арифметической простой рассчитывается следующим образом: цены всех активов, входящих в индекс, складываются и делятся на количество активов. Данный метод является самым простым. Его недостатком является то, что в нём не учитывается вес каждого актива. В настоящее время данным методом рассчитываются индексы семейства Доу-Джонс индекс.
Чуть более сложен метод с использованием дивизора. Например, S&P 500 — это средневзвешенное по капитализации цен акций пятисот ведущих американских компаний, поделенное на некоторый фиксированный коэффициент (дивизор). Дивизор выбирается так, чтобы на момент исторического начала расчета индекса (базовая дата) его значение равнялось какому-нибудь удобному числу (базовому значению). Придание акциям разных весов в индексе делается для того, чтобы более крупные фирмы имели большее влияние на значение индекса, однако это не является обязательным правилом.
Некоторые биржевые индексы рассчитываются как индексы суммарного дохода на капитал. При этом предполагается, что полученный в виде дивидендов доход немедленно реинвестируется в акции. Примером такого индекса является индекс DAX — самый важный биржевой индекс Германии.
Индекс Доу-Джонса
Индекс Доу-Джонса — средний показатель курсов акций группы крупнейших компаний США . Индекс публикуется компанией «Dow-Johns an index & Company » и представляет среднеарифметическое ежедневных котировок на момент закрытия биржи. Различают индексы Доу-Джонса для акций коммунальных, промышленных и транспортных компаний.
Различают индексы Доу-Джонса для акций коммунальных, промышленных и транспортных компаний.
Индекс Доу-Джонса служит показателем текущей хозяйственной конъюнктуры США и отражает реакцию американских деловых кругов на различные экономические и политические события.
Коммунальный индекс Доу-Джонса — средний показатель движения курсов акций 15 компаний, занимающихся газо- и электроснабжением.
Составной индекс Доу-Джонса — показатель, составляющийся на базе промышленного, транспортного и коммунального индексов Доу-Джонса.
Транспортный индекс Доу-Джонса — средний показатель, характеризующий движение цен на акции 20 транспортных корпораций.
Промышленный индекс Доу-Джонса (англ. Dow Johns Industrial Average, DJIA), (NYSE: DJI) — один из нескольких биржевых индексов, созданных редактороПромышленный индекс Доу-Джонса учредителем организации Dow Johns»s index & Company Чарльзом Доу (англ. Charles Dow).
Доу-Джонс является старейшим среди существующих американских рыночных индексов. Этот индекс был создан для отслеживания развития промышленной составляющей американских рынков акций.
Этот индекс был создан для отслеживания развития промышленной составляющей американских рынков акций.
Индекс охватывает 30 крупнейших компаний США. Приставка «промышленный» является данью истории — в настоящее время многие из компаний, входящих в индекс, не принадлежат к этому сектору. Первоначально индекс рассчитывался как среднее арифметическое цен на акции охваченных компаний. Сейчас для расчёта применяют масштабируемое среднее — сумма цен делится на делитель, который изменяется всякий раз, когда входящие в индекс акции подвергаются дроблению (сплиту) или объединению предприятий (консолидации). Это позволяет сохранить сопоставимость индекса с учётом изменений во внутренней структуре входящих в него акций.
Первые варианты индекса появились в 1884 году и охватывали цены акций девяти железнодорожных и двух промышленных компаний. Этот вариант индекса не публиковался и служил для внутреннего анализа. Впервые индекс был опубликован 26 мая 1896 года уже как «промышленный». На тот момент индекс представлял собой среднее арифметическое цен акций 12 американских промышленных компаний, из которых в сегодняшней версии индекса представлена лишь General Electric (её перерывы присутствия в индексе с сентября 1898 года по апрель 1899 года и с апреля 1901 года по ноябрь 1907 года). Кроме этого в первоначальный индекс были включены:
Кроме этого в первоначальный индекс были включены:
American cotton Oil Company, предшественник Bestfoods, сегодня являющейся частью фирмы Unilever
American sugar Company, теперь Domino Foods, Inc.
American Tobacco Company, разделенная в 1911 году
Chicago Gas Company, купленная организацией Peoples Gas Light & Coke Co. в 1897 году (теперь Peoples energy Corporation)
Distilling & Cattle Feeding Company, теперь Millennium Chemicals
Laclede Gas Light Company, существующая под именем The Laclede Group
National lead Company, теперь NL Industries
North American Company, разделенная в 1940 году
Tennessee Coal, Iron and Railroad Company, купленная U.S. Steel в 1907 году
U.S. Leather Company, прекратившая существование в 1952 году
U.S. Rubber Company, переименованная в Uniroyal в 1967 году и купленная компанией Michelin в 1990 году.
В 1916 году количество компаний было увеличено до 20, а с 1 октября 1928 — до 30. При ротации обычно в индексе заменяются одна-две организации за раз. Самым «бурным» временем стала в начале 30-х годов XX века: 18 июля 1930 года в индексе заменены сразу семь компаний, а 26 мая 1932 года — восемь. Было два периода по 17 лет (1939—1956 и 1959—1976 годы), когда не происходило никаких изменений в структуре индекса.
При ротации обычно в индексе заменяются одна-две организации за раз. Самым «бурным» временем стала в начале 30-х годов XX века: 18 июля 1930 года в индексе заменены сразу семь компаний, а 26 мая 1932 года — восемь. Было два периода по 17 лет (1939—1956 и 1959—1976 годы), когда не происходило никаких изменений в структуре индекса.
Первым опубликованным значением индекса было 40,94. 14 ноября 1972 года индекс впервые превысил отметку 1000 (1003,16). В 80-х и, особенно, в 90-х годах наблюдался бурный рост индекса. 21 ноября 1995 года он впервые преодолел планку в 5000 (5023,55), а 29 марта 1999 года осталась позади отметка 10 000 (10 006,78). Всего лишь месяц спустя, 3 мая 1999, индекс достиг значения 11 014,70. Своего максимума — отметку 11 722,98 — Доу Джонс достиг 14 января 2000 года. Затем наблюдалось резкое падение индекса и 9 октября 2002 DJIA достиг промежуточного минимума со значением 7286,27.
Самый большой в процентном отношении обвал индекса произошел в «чёрный понедельник» 1987-го года, когда Доу-Джонс потеряDJIA ,6 %. В первый торговый день после терактов 11 сентября 2001 индекс потерял 7,1 %.
В первый торговый день после терактов 11 сентября 2001 индекс потерял 7,1 %.
Недостатки:
1. Особенность индекса Доу—Джонса состоит в том, что он показывает средние текущие цены акций без их сопоставления с базовой величиной. Поэтому индекс нужно рассматривать в сопоставлении с некой величиной, принятой за основу для сравнения (к определенной дате).
2. Одним из существенных недостатков индекса Доу-Джонса является способ его вычисления — при подсчёте индекса цены входящих в него акций складываются, а потом делятся на поправочный коэффициент. В результате даже если одна организация заметно меньше по капитализации , чем другая, но стоимость одной её акции выше, то она сильнее влияет на индекс. Даже большое процентное изменение цены относительно дешёвой акции может быть нивелировано незначительным в процентном отношении изменением цены более дорогой акции.
3. Охватывая лишь 30 компаний, индекс Доу-Джонса плохо подходит на роль индекса общей активности рынка акций . Для объективности вместе с индексом Доу-Джонса иногда используется индекс S&P 500 .
Для объективности вместе с индексом Доу-Джонса иногда используется индекс S&P 500 .
Российские биржевые индексы
Российские биржевые индексы молоды как и рынок ценных бумаг . При этом число их растет, а методика расчета прогрессирует. Их количество увеличивается в первую очередь за счет появления отраслевых индексов. Так сейчас биржи рассчитывают индексы акций нефтяных, металлургических, энергетических, телекоммуникационных компаний. В перспективе появление акций банковского (финансового) сектора. Кроме того, что инвесторы могут по этим индексам оценивать состояние определенной отрасли, отраслевые индексы имеют и другое практическое значение. В ближайшей перспективе следует ожидать появление индексных ПИФов на фондовые отраслевые индексы. При этом ситуация с индексами, характеризующими состояние российского фондовой биржи, по сути, будет оставаться стабильной.
Индекс РТС. Рассчитывается как взвешенный по капитализации индекс наиболее ликвидных акций российских эмитентов, допущенных к торгам на рынку акций РТС . Индекс рассчитывается с 1 сентября 1995 года. При расчете капитализации учитывается количество акций, находящихся в свободном обращении.
Индекс рассчитывается с 1 сентября 1995 года. При расчете капитализации учитывается количество акций, находящихся в свободном обращении.
В 2005 году методика расчета индекса была измененая — он стал рассчитываться в реальном времени, что позволило в FORTS (секция срочного рынка в РТС ) запустить торговлю фьючерсной сделкой на индекс РТС, а впоследствии и опционов.
Это инструмент оказался очень востребован спекулянтами и быстро стал лидером по оборотам на FORTS. Индекс РТС по прежнему основан на «классическом» РТС, где происходит торговля акциями за американский доллар.
Многие ли задаются вопросом о том, что такое и для чего нужен почтовый индекс? Этот цифровой шифр чаще всего используется большинством людей автоматически при отправке посылок и писем, при оформлении многочисленных покупок по Интернету. Его важность часто осознается лишь тогда, когда из-за неправильно написанного индекса пропадает долгожданная посылка или слишком долго не приходит важное письмо.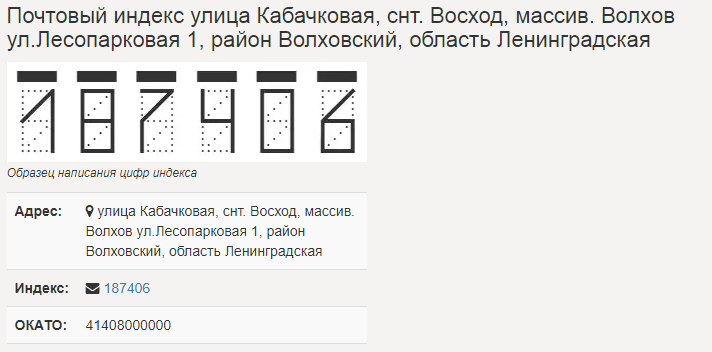
Что это такое и для чего нужно?
Почтовый индекс — это установленная законом РФ особая комбинация чисел, которая указывается на письме, открытке, посылке или в форме заказа. С его помощью оптимизируется работа почты: сводятся к минимуму объемы ручного труда, повышается эффективность сортировки, ускоряется доставка, снижается риск ошибок при перемещении посылок и писем, повышается вероятность того, что почтовое отправление получит правильный адресат.
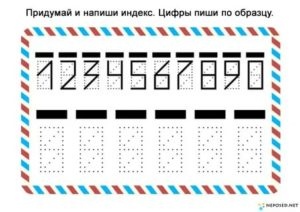
Индексы пишутся специальными угловатыми цифрами, такой формат легче считывается компьютерами. Для удобства отправителя на письма и бланки нанесены образцы написания цифр, а также форма из тонких пунктирных линий. Поэтому для заполнения этой графы не нужны специальные навыки, достаточно аккуратности и внимательности. Нужно помнить, что ошибка или отсутствие индекса может привести к потере отправления или сильной его задержке. Цифры допускается писать чернилами любого цвета, исключая зеленый, красный и желтый.
История
Во все времена люди обменивались сообщениям. От скорости и точности передачи информации порой зависела жизнь. Использовались сигнальные огни, быстроногие гонцы, собаки, птицы, попутные караваны и корабли. Персы выстраивали многотысячные вереницы людей, расставляя их в пределах слышимости. С помощью переклички сообщения передавались на дальние расстояния. Особой точностью отличались почтовые голуби с феноменальной способностью находить свой дом.
От скорости и точности передачи информации порой зависела жизнь. Использовались сигнальные огни, быстроногие гонцы, собаки, птицы, попутные караваны и корабли. Персы выстраивали многотысячные вереницы людей, расставляя их в пределах слышимости. С помощью переклички сообщения передавались на дальние расстояния. Особой точностью отличались почтовые голуби с феноменальной способностью находить свой дом.
Эволюционным скачком вперед стало внедрение телеграфа в первой половине XIX века. Но он все равно не мог справиться с информационным потоком бурно развивающегося человечества. Не справлялись с ним и почтовые службы, им требовались очевидные усовершенствования. С растущими объёмами писем и посылок помогло совладать изобретение почтового индекса. Это элегантное решение упорядочило работу почт, а со временем сыграло роль в ее автоматизации.
Индексация в России
Почтовая индексация впервые появилась в СССР в 1932 году. Экспериментальное использование индекса началось в Советской Украине и успешно продолжалось до 1939 года, когда разразилась Мировая война. Индексы были отменены, видимо, в целях национальной безопасности.
Индексы были отменены, видимо, в целях национальной безопасности.
Во второй раз их стали применять уже по всему Советскому Союзу. В 1971 году была проведена глобальная индексация всей страны. Номера были присвоены каждому почтовому отделению. С этих пор на каждой посылке, поздравительной открытке или письме отправитель обязан был указывать цифровой индекс. Это было сделано во многом из-за того, что почтовые службы стали применять для обработки отправлений передовые на то время машины.
Как расшифровывается?
В том виде, в каком индекс используется сейчас, он утвержден в 1998 году. Почтовое деление в нашей стране соответствуют административному. Сегодня российский почтовый индекс — это закономерная последовательность шести цифр, формата АААВВВ. ААА — числовой код, который присваивается городам республиканского, краевого или областного значения. Крупные субъекты федерации и мегаполисы имеют несколько кодов. ВВВ — числовой код, который присваивается каждому почтовому отделению в определенном городе.
Для иллюстрации. В индексе 414042 зашифрована следующая информация: 414 — код города Астрахани, 042 — почтовое отделение № 42, которое находится на проспекте Бумажников и обслуживает дома в округе. Другие примеры: 685007, 685 — код Магадана, 007 — отделение почты № 7, обслуживающее дома по улице Аммональной; 241027, 241 — код Брянска, 027 — почтовое отделение, обслуживающее здания на площади К. Маркса.
Как узнать почтовый индекс?
В наш век развитого Интернета сделать это просто. Существует три распространенных способа определения почтового индекса.
- Первый. Позвонить или сходить в почтовое отделение. Этот способ годится, если нужно узнать индекс определенного отделения, которое находится недалеко. Впрочем, на почте служащие дадут информацию о любом адресе, ведь у них есть соответствующие справочники.
- Второй. Воспользоваться справочной программой. Удобной и подробной программой является 2ГИС. С ее помощью можно быстро определить адрес практически любого здания в России. Чтобы узнать, какой почтовый индекс у нужного дома, надо всего лишь отыскать его на карте и нажать на него.
- Третий. Самый простой и быстрый способ — найти через любой поисковик в Интернете справочник с указанием всех российских почтовых индексов. Главное — отыскать свежий справочник. Дело в том, что индексов очень много, в их базе постоянно происходят изменения, которые не носят значительный характер, но все-таки желательно пользоваться самой актуальной информацией, чтобы исключить ошибки.
 Чтобы узнать, какой почтовый индекс у нужного дома, надо всего лишь отыскать его на карте и нажать на него.
Чтобы узнать, какой почтовый индекс у нужного дома, надо всего лишь отыскать его на карте и нажать на него.И помните, что индекс всегда нужно указывать. Это влияет на скорость доставки отправления.
Пишем цифры индекса на конверте правильно.
Правильное написание цифр индекса на почтовом конверте — обязательно условие, если вы хотите, чтобы письмо дошло до адресата быстро.
Почему это так важно? Дело в том, что ручную сортировку писем стараются минимизировать, поэтому всё чаще для обработки используются специальные автоматизированные средства. И цифры индекса позволяют машине быстро определить, куда направляется письмо.
Какой индекс писать на конверте
Индекс указывается и для оправителя и для получателя. А вот в поле индекса для автоматизированной сортировки (обычно находится в левом нижнем углу конверта) указывается индекс получателя. Если же там указать свой индекс, письмо может надолго задержаться на сортировке, пока его не обработают вручную.
Как правильно писать цифры индекса
Вот вам пример написания цифр на конверте:
Цифры можно заполнять любым цветом, кроме красного, жёлтого и зелёного. С чем связано такое ограничение — не знаю, но это указано в правилах Почты России. Возможно, автоматизированное оборудование определяет эти цвета как служебные или что-то в этом роде. Поэтому черной или синей ручкой можно писать индекс совершенно спокойно.
Как писать индекс на международных конвертах
Индекс получателя на конверте для междунарожного письма нужно указывать в соответствующем поле получателя и больше нигде. Специальных полей, как на конвертах для внутренних писем, там нет. Точнее, международные конверты выглядят так:
Точнее, международные конверты выглядят так:
Цифры 555 значат, что конверт международный. Письмо доставят за границу, а там уже местные почтальоны будут разбираться, кому доставить конверт.
Образец почтового индекса
Писать почтовые индексы учат чуть ли не с детского сада. Однако разве кто-то помнит, как пишутся эти цифры. Специально для этого случая на сайте выкладываем образец почтового индекса.
При заполнении почтового индекса получателя, убедитесь что там всё написано верно. В одном и том же городе могут быть разные почтовые индексы. В одном случае письмо попадёт прямо на местную почту получателя. А в другом случае то же письмо может попасть на главное отделение почты, которое может находиться в 20 километрах от адресата.
Чтобы посмотреть образец написания почтового индекса, нажмите на картинку, прикреплённую к статье. Или просто посмотрите ниже:
Образец написания цифр индекса — отличный вариант.
Описание:
Прописная цифра один (1). Опубликовано 15.10.2012 — 15:49 — Матафонова Наталья Николаевна. Для сортировки почтовых отправлений Почта России применяет автоматизированные технологии. Чтобы посмотреть образец написания почтового индекса, нажмите на картинку, прикреплённую к статье. Ниже приведен образец написания цифр индекса. Цены от всех магазинов России в одном месте. Образец написания цифр индекса. Данный материал предназначен для показа образца написания цифр. Почто?вый и?ндекс — последовательность букв или цифр, добавляемая к почтовому адресу с целью облегчения сортировки корреспонденции, в том числе автоматической. Однако разве кто-то помнит, как пишутся эти цифры. Парень какое-то время напряженно молчал, потом наморщил индекс.
Опубликовано 15.10.2012 — 15:49 — Матафонова Наталья Николаевна. Для сортировки почтовых отправлений Почта России применяет автоматизированные технологии. Чтобы посмотреть образец написания почтового индекса, нажмите на картинку, прикреплённую к статье. Ниже приведен образец написания цифр индекса. Цены от всех магазинов России в одном месте. Образец написания цифр индекса. Данный материал предназначен для показа образца написания цифр. Почто?вый и?ндекс — последовательность букв или цифр, добавляемая к почтовому адресу с целью облегчения сортировки корреспонденции, в том числе автоматической. Однако разве кто-то помнит, как пишутся эти цифры. Парень какое-то время напряженно молчал, потом наморщил индекс.
Образец заполнения конверта
Уже не одну сотню лет конверты остаются излюбленным способом доставки писем и документации. Однако в эпоху современных цифровых технологий и интерактивного общения многие из нас уже порядком подзабыли, как правильно заполнить конверт. В первую очередь, информация на почтовом конверте должна быть заполнена аккуратно с соблюдением определенных правил. В любом почтовом отделении присутствует образец заполнения конверта, на который можно опираться при отправке писем.
В любом почтовом отделении присутствует образец заполнения конверта, на который можно опираться при отправке писем.
1. Язык. При отправке корреспонденции в пределах РФ, конверт должен быть заполнен на русском языке. Если вам необходимо отправить письмо в другую страну, напишите адрес на английском языке. При этом ориентируйтесь на образец заполнения конверта для писем за рубеж. Если необходимо, вы можете продублировать данные на языке страны-получателя (немецком, французском и т.д.), при этом наличие информации на английском обязательно.
2. Адрес. Правильное написание адреса на конверте может сократить срок пересылки письма. Если вы обратите внимание на образец заполнения конверта, то сможете заметить, что адрес отправителя располагается в левом верхнем углу, а получателя — в правой нижней части конверта. Адрес заполняется в следующем порядке: ФИО, почтовый адрес (улица, дом, район, область/край, населенный пункт), индекс. Для получателей и отправителей порядок написания адреса идентичен.
3. Аккуратность. Адрес должен быть написан разборчивым почерком, лучше печатными буквами. Не допускаются зачеркивания, исправления, орфографические ошибки в написании адреса. Для грамотного заполнения данных обращайте внимание на образец заполнения конверта.
Написание адресов на конвертах является ответственным и трудоемким этапом при отправке писем. А как быть в той ситуации, если вы отправляете не одно письмо, а проводите многотысячную рассылку? В этом случае целесообразно воспользоваться специализированным софтом для печати конвертов. Например, редактор «Почтовые Конверты» от AMS Software — это удобная и качественная программа для печати конвертов и организации рассылок. Пользователю лишь нужно внести информацию об отправителях и получателях, выбрать шаблон нужного формата и распечатать готовый конверт. Программа включает встроенный образец заполнения конверта, и все поля вводятся автоматически из базы. Продукт оснащен дружественным русскоязычным интерфейсом и подробными справочными материалами, что обеспечивает легкую и комфортную работу в программе.
Если внимательно посмотреть на образец заполнения конверта, в его левой нижней части располагается так называемый кодовый штамп. Он содержит почтовый индекс получателя, записанный стилизованными цифрами. Эти цифры можно записать чернилами любого цвета, за исключением желтого, зеленого и красного. В противном случае письмо не будет допущено к сортировке. Образец заполнения кодового штампа вы можете видеть на картинке.
Образец оформления почтовых отправлений
Внимание! От правильного оформления почтового отправления напрямую зависит скорость пересылки Вашего отправления по магистральным почтовым маршрутам.
На внутренних почтовых отправлениях и сопроводительных бланках к почтовым отправлениям, а также на бланках почтовых переводов почтовые адреса пишутся отправителем в следующей последовательности:
образец написания цифр индекса
Источники:
,
Следующие документы:
- Служебная записка о командировке образец написания
- Образец написания докладной на ученика
Вас может заинтересовать
Что принимаем во внимание
Обязательно следует учитывать:
- Язык . Чтобы корреспонденция дошла к адресату в пределах Российской Федерации, конверт заполняется на русском языке. При необходимости отправки письма в другое государство, адрес следует писать на английском языке. Изучите образец заполнения корреспонденции за границу. При необходимости продублируйте информацию на языке государства-получателя, но данные на английском языке обязательны.
- Адрес . Корректное написание адреса, вероятно, сократит срок доставки письма. Согласно образцу, адрес отправителя находится в верхнем левом углу конверта, а получателя – в его нижней правой части. При написании адреса, указывается ФИО, полный почтовый адрес и индекс. Для получателя и отправителя порядок написания адреса одинаков.
- Аккуратность . Пишите адрес разборчиво, лучше – печатными буквами. Недопустимы исправления, зачеркивания, орфографические ошибки. Чтобы заполнить графы правильно, сверяйтесь с образцом.
Адрес
Написание адреса – это ответственный этап оформления корреспонденции. Если нужно осуществлять многотысячную рассылку писем, целесообразно воспользоваться специализированными программами для печати конвертов. К примеру, редактором «Почтовые Конверты» от AMS Software – качественная, удобная программа для печати конвертов и осуществления рассылок. Внести нужно лишь данные об отправителях и получателях; выбирается шаблон требуемого формата, распечатывается готовый конверт. Программа включает в себя образец заполнения конверта, а поля вводятся из базы автоматически. Русскоязычный интерфейс и подробный справочный материал обеспечивают легкость и удобство в работе с программой.
В нижней левой части почтового конверта располагается кодовый штамп, содержащий почтовый индекс получателя, который пишется стилизованными цифрами.
Цифры можно писать чернилами определенного цвета: желтые, зеленые и красные не допускаются . Из-за них письмо не попадет на сортировку. Поэтому лучше выбрать синюю или черную пасту.
Как писать индекс в России
В разных странах количество цифр в почтовом индексе разное. В РФ сейчас действует 6-значная система почтовой индексации.
- Три первые цифры говорят о принадлежности к тому или другому региону, последние три являются номером такого-то почтового отделения, отделения связи. Таким образом, индекс на почтовом конверте является своеобразным идентификатором отправления.
- С помощью сортировочных аппаратов корреспонденция разбивается по месту отправления. Поэтому писать почтовый индекс следует корректно. Пишут его на поле основного текста, а потом дублируют на специальных полях, определенных точками.
- Высота точек совпадает с высотой сканирующих аппаратов. Индекс пишется по четкой схеме написания, указанной на обороте конверта. Писать нужно так, чтоб аппараты легче считывали необходимую информацию.
- Для написания почтового индекса рекомендуется выбирать чернила, которые не размываются из-за воздействия влаги.
- Декоративные конверты или конверты, выпущенные по случаю праздника, обычно не имеют специального поля для указания индекса. Это усложняет корректное написание цифр, а значит, доставка письма затрудняется. Почтамт рекомендует использовать стандартные конверты.
Индекс на международных письмах
В этом случае индекс получателя указывается в соответствующем поле единожды. Цифры 555 говорят о том, что почтовый конверт международный и пойдет за границу.
Заключение
От корректности написания адреса зависит скорость обработки и доставки письма, в связи с чем федеральный почтовый оператор призывает не игнорировать правила и порядок заполнения соответствующих полей :
- Для субъекта – ФИО; для юр. лица – полное или сокращенное названия, название улицы, номер дома и квартиры (или а/я).
- Населенный пункт.
- Район.
- Республика, край, область, автономный округ.
- Страна (для международных писем).
- Индекс.
Адресные данные надо писать разборчиво или печатать типографским способом (возможно, с помощью печатной техники). Размер шрифта должен быть не меньше 11 пт (4 мм), для цифр индекса – 13-14 пт (5 мм). Рекомендуются печатные буквы. Адрес адресата и отправителя почтового отправления в пределах России указываются на русском языке.
Зачастую люди, редко отправляющие или совершенно не посылавшие письма, открытки, посылки, не знают, как правильно написать почтовый адрес.
Этот момент мы и обсудим, заодно рассмотрим примеры того, как заполнять конверт или пустой бланк.
Все об индексе получателя
Что же подразумевается под почтовым адресом? Представим, что вы хотите отправить письмо близкому другу в деревню Ильино, которая расположена в тридцати километрах от райцентра. Сами вы проживаете в Москве. Допустим, что вы точно знаете адрес друга, но этого недостаточно. На конверте и в бланке для посылок имеется поле с написанием шести цифр. Очень важно знать, какой почтовый индекс по адресу. Именно те самые шесть цифр, которые следует прописать в первую очередь. Без индекса (кодового штампа) посылку, бандероль, простое или заказное письмо сотрудники почты не примут. Поэтому обязательно узнайте точно, какой индекс у районной почты, которая занимается отправкой писем в деревню Ильино. Здесь нужно быть внимательным, так как если написать индекс другого почтового отделения, то письмо может вовсе не дойти. Почтовое отделение работает только с теми адресами, которые к нему находятся ближе всего. Бывают исключения, когда совершается досылка из ошибочного отделения в нужное.
А теперь рассмотрим пример почтового адреса, после написания индекса, который пишется дважды. Кстати, стоит отметить этот момент, потому что зачастую людей, отправляющих письмо впервые, смущает то, что на конверте напечатаны два поля: одно внизу, сразу под адресом, второе — снизу в виде пропечатанных точками цифр. Заполнять нужно и маленькое окошко, и большое одним и тем же номером индекса. На обратной стороне конверта имеется образец, как правильно прописывать цифры.
Отправитель и получатель
На конверте, а также на пакете или коробке с посылкой есть строки с фразами «от кого» и «кому». Вполне ясно, что тот, кто отправляет письмо, должен написать свой адрес для почтовых отправлений в форму с надписью «от кого». Соответственно, тот, кто занимается отправкой, является отправителем. Как правило, при отправке посылки выдается чек с адресом отправителя и получателя, а также стоимостью пересылки, почтовым идентификатором. Но нас интересуют сейчас только отправитель и получатель. Таким образом, получателем является тот, кому отправляют посылку или письмо.
Очень важно понимать это, так как на почте могут задать вопрос, например: «Вы знаете адрес получателя?» Или же спросят, кто является отправителем.
Как и чем заполнять адрес
Почтовый адрес — это ответственный момент при совершении пересылки писем и посылок. Ни в коем случае нельзя допустить, чтобы данные размылись или стерлись. Кроме того, писать нужно разборчивым почерком и крупным шрифтом.
Поэтому недопустимо заполнять конверты карандашом или яркими ручками, фломастерами. Рекомендуется использовать гелевые, шариковые, перьевые ручки черного или синего цвета для заполнения бумажного конверта. При отправке посылки в фирменном пакете «Почты России» или на бланке с глянцевой поверхностью желательно использовать черный маркер, стойкий по отношению к влаге и трению.
На чем пишется адрес
Ранее мы упоминали в основном письма и посылки. Теперь следует перечислить типы почтовых отправлений, чтобы сориентироваться, какую услугу заказывать у почты.
Начнем с писем. В конверте можно отправить открытку, несколько листов с текстом или рисунками, фотографии и вырезки из газет. То есть маленькие и плоские предметы, но не представляющие материальной ценности (деньги, документы, ксерокопии паспорта и т. д.). Как написать адрес на почтовом конверте так, чтобы не испортить то, что внутри? Желательно подписать конверт, пока он пустой. Только потом вкладывать нужные предметы.
Если надо отправить предметы большего размера, например одну небольшую книгу, DVD-диск или календарь, то стоит попросить оператора почтовой связи об отсылке бандероли. Более крупные предметы отправляются посылкой в пакете или коробке. При заполнении пакета также следует сначала написать правильный почтовый адрес, а потом уже вкладывать в него предметы и запечатывать.
Заказные письма также требуют правильного заполнения. Они чаще всего предназначены для пересылки ценных бумаг, поэтому следует знать точный адрес и Ф.И.О. получателя. Также следует обязательно написать свой обратный адрес.
Порядок заполнения формы с адресом
Теперь давайте разберем последовательность заполнения адреса. Принято сначала писать фамилию, имя и по возможности отчество человека, которому отправляете письмо. Например, «Сергееву Ивану» или «Сергееву Ивану Алексеевичу». Допустимо писать инициалы. Письма приходят сразу в почтовый ящик без уведомления.
Далее в строчке «Адрес» пишем улицу и дом (если частный сектор) либо улицу, дом, корпус/строение (если имеется), квартиру/комнату. Данные должны быть точными, а цифры — четкими. Нельзя допускать, чтобы, например, цифра «7» читалась как цифра «1», иначе почтальон может ошибиться и отправить письмо не туда, куда нужно.
Затем пишется название населенного пункта (например, поселок Сосенки Осташковского района Тверской области). Разрешается писать адрес в другой последовательности: область/край, район/областной центр, населенный пункт, улица и дом. Также можно сокращать «район» — «р-н», а «область» — «обл.» и так далее.
Следует еще раз напомнить о том, чтобы вы обязательно узнали, какой почтовый индекс по адресу получателя, также вам нужно знать и свой на случай неудачной попытки вручения.
Примеры адресов
Выше вы изучили, как заполняются письма и посылки для частных граждан. Теперь рассмотрим нюансы заполнения отправлений военнослужащим и юридическим лицам. Ниже представлен пример почтового адреса для письма солдату.
Отметим лишь, что под литерой подразумевается рота. Например, солдат служит в спортивной роте и литера его роты — «А». Обязательно пишутся Ф.И.О. солдата.
Далее рассмотрим письмо на предприятие. Если у организации нет абонентского ящика (а/я), то адрес пишется на конкретный отдел, конкретному должностному лицу. Соответственно, указываются Ф.И.О.
Важность написания настоящих Ф.И.О. получателя
Почтовый адрес — это неотъемлемая задача отправителя, кроме того, требуется указывать фамилию, имя и отчество, как свое в графе «От кого», так и в графе «Кому». Особенно это касается посылок и заказных писем с бандеролями. Дело в том, что в почтовый ящик получателю (адресату) приходит не сама посылка или заказное письмо, а только уведомление. Его нужно заполнить (получателю следует вписать свои паспортные данные), затем с уведомлением и паспортом прийти на почту. Если Ф.И.О. не совпадают, то посылку или заказное письмо могут не вручить.
Обязательно ли писать свой адрес?
Некоторые люди совершают ошибку, когда письмо оставляют без обратного адреса. Также нельзя отправлять посылку, не написав свои индекс, город, улицу и дом. Дело в том, что письма и посылки могут не дойти до получателя, например, студент уехал из одного общежития в другое или солдат переведен из одной воинской части в другую. В таком случае письмо возвращается в почтовое отделение получателя, затем с пометкой «получатель отсутствует по указанному адресу» возвращается к отправителю.
Вы узнали, что почтовый адрес — это ключик к тому, чтобы предмет и письмо дошли до нужного человека. Без индекса и точных координат получателя письмо или посылка просто не дойдут и будут со временем возвращены в «родное» почтовое отделение. Стоит отметить, что без индекса письма и посылки недействительны, равно как и без полного адреса.
Индексы в PostgreSQL
Виталий Сушков
Full Stack Developer в DataArt
В статье я расскажу о предназначении и основах принципов работы объектов баз данных — индексов. На примере СУБД PostgreSQL коротко рассмотрим несколько разных типов индексов и классов задач, для которых они применимы. В конце материала поделюсь ссылками на статьи с более глубоким описанием внутреннего устройства индексов в PostgreSQL.
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Предназначение индексов
Простейший метод решения задачи поиска записей в базе данных, удовлетворяющих определенному критерию, — полный перебор. Но с ростом количества записей производительность такого подхода будет заметно падать. Для повышения производительности поиска создаются вспомогательные структуры — индексы. Используя индексы, можно существенно поднять скорость поиска, потому что данные в индексе хранятся в форме, позволяющей нам в процессе поиска не рассматривать области, которые заведомо не могут содержать искомые элементы.
Если провести аналогию между базой данных и книгой, индексами можно считать оглавление книги и предметный указатель. Действительно, если бы у нас не было таких «индексов», для поиска конкретной главы или для поиска определения какого-то понятия пришлось бы листать и читать всю книгу целиком, пока не найдем то, что нужно. Имея оглавление и предметный указатель, нам нужно просмотреть существенно меньший объем данных, после чего мы точно узнаем номер страницы книги, на которой находится то, что мы ищем. Индексы в базах данных по сути устроены так же, как оглавление или как предметный указатель книги.
Важно, что использование индексов не только сокращает время поиска в абсолютном выражении, но и уменьшает алгоритмическую сложность процесса поиска. Это значит, что время, необходимое на поиск с помощью индексов, при росте объема базы данных будет расти существенно медленнее, чем при использовании полного перебора.
В качестве примера рассмотрим задачу поиска в списке чисел. Используя перебор элементов списка, в худшем случае, нам придется просмотреть список целиком. Алгоритмическая сложность такого метода — O(n). Но если мы будем хранить наши числа особым образом — отсортированными по возрастанию или по убыванию — сможем использовать алгоритм бинарного поиска.
2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
Допустим, необходимо определить, содержит ли этот отсортированный список число 158. Для этого:
- Смотрим на число в середине списка — 114. Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Теперь делаем то же самое для правой половины списка. В середине у нее число 134, значит, мы снова можем отбросить элементы левее.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Делаем то же самое для элементов правее 134. В середине у них число 158 — искомый элемент. Поиск закончен.
В итоге метод бинарного поиска дал нам результат всего за три шага. При полном переборе с начала списка нам потребовалось бы 16 шагов. Бинарный поиск имеет алгоритмическую сложность O(log(n)). Используя формулы алгоритмической сложности O(n) и O(log(n)), мы можем оценить, как будет меняться приблизительное количество операций при поиске разными способами с ростом объема данных:
Результат впечатляет. Храня данные в отсортированном виде, мы не только снизили скорость поиска по ним, но и колоссально сократили скорость замедления поиска при росте объема данных.
Использование индексов в базе данных дает аналогичный результат. Принцип работы одного из важнейших индексов в базе данных (индекс на основе B-дерева) основан именно на рассмотренном нами выше принципе — возможности хранить данные в отсортированном виде.
Индексы в PostgreSQL
В базах данных, таких как PostgreSQL, индекс формируется из значений одного или нескольких столбцов таблицы и указателей на строки этой таблицы.
Рассмотрим запрос:
SELECT * FROM table_name WHERE P(column_name) = 1
Здесь выражение P(column_name) = 1 означает, что значение в колонке column_name удовлетворяет некоторому условию (предикату) P.
В отсутствии индекса для колонки column_name, PostgreSQL для выполнения этого запроса был бы вынужден просмотреть таблицу table_name целиком, вычисляя для каждой строки значение предиката P и, если значение истинно, добавлял бы строку к результатам запроса.
Имея индекс для колонки column_name, PostgreSQL может быстро, не просматривая таблицу целиком, получить из индекса указатели на строки таблицы, которые удовлетворяют условию P, и затем уже по этим указателям прочитать данные из таблицы и сформировать результат. Это аналогично тому, как мы, вместо того чтобы просматривать всю книгу целиком, смотрим только ее оглавление, читаем номера страниц, соответствующие интересующим нам главам, а затем переходим на эти страницы.
Предикат P может вычисляться от значения нескольких колонок. В этом случае для ускорения запроса используется индекс, построенный не для одной колонки, а для нескольких. Такие индексы называют составными.
Если мы хотим ускорить выполнение запроса, условие которого вычисляется по одной или нескольким колонкам, в PostgreSQL нам необходимо создать для этих колонок индекс с помощью команды CREATE INDEX:
CREATE INDEX index_name
ON table_name (column_name_1, column_name_2,....)Эта команда имеет большой перечень дополнительных параметров, с полным списком которых можно ознакомиться в документации.
Например, индекс может поддерживать ограничение на уникальность и не допускать появления в таблице нескольких строк, значения индексируемых столбцов у которых совпадают. Для этого при создании индекса указывают ключевое слово UNIQUE:
CREATE UNIQUE INDEX index_name
ON table_name (column_name_1, column_name_2,....)Или мы можем создать индекс не по полю таблицы, а по функции или скалярному выражению с одной или несколькими колонками таблицы (такие индексы называют функциональными или индексами по выражению). Это позволяет быстро находить данные в таблице по результатам вычислений. Например, мы хотим ускорит запрос регистронезависимого поиска по текстовому полю:
SELECT * FROM table_name
WHERE lower(text_field) = 'some_string_in_lower_case'Если мы создадим обычный индекс по полю text_field, он нам никак не поможет, т. к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции lower. Однако мы можем создать индекс по результатам вычисления выражения lower(text_fields):
CREATE INDEX index_name ON table_name(lower(text_field))
И такой индекс уже может успешно применяться для ускорения нашего запроса.
В зависимости от типа индексируемых данных, для индексирования применяются разные подходы. По умолчанию при создании индекса используется индекс на основе B-дерева. Но PostgreSQL поддерживает разные типы индексов для очень широкого круга задач, и при необходимости мы можем указать другой тип индекса, отличный от B-tree. Для этого перед списком индексируемых полей необходимо указать директиву USING <тип_индекса>. Например, для использования индекса типа GiST:
CREATE INDEX index_name ON table_name USING GIST (column_name)
B-tree
Этот тип индекса используется по умолчанию и покрывает очень широкий круг задач (базы данных большинства приложений успешно могут обходиться только индексами на основе B-деревьев).
С помощью B-дерева можно проиндексировать любые данные, которые могут быть отсортированы, т. е. для которых применимы операции сравнения больше/меньше/равно. Сюда можно отнести числа, строки, даты и время, логический тип и любые данные, которые можно ими закодировать.
Какой тип запросов может быть ускорен с помощью B-дерева? На самом деле, практически любой запрос, условие которого является выражением, состоящим из полей входящих в индекс, логических операторов и операций равенства/сравнения. Например:
- Найти пользователя по его email:
- Найти товары одной из двух категорий:
SELECT * FROM goods WHERE category_id = 10 OR category_id = 20
- Найти количество пользователей, зарегистрировавшихся в конкретный месяц:
SELECT COUNT(id) FROM users WHERE reg_date >= 01.01.2021 AND reg_date <= 31.01.2021
Выполнение этих и многих других запросов может быть ускорено с помощью B-дерева. Кроме того, индекс на основе B-дерева ускоряет сортировку результатов, если в ORDER BY указано проиндексированное поле.
Принцип работы индекса на основе B-дерева основан на рассмотренном нами ранее алгоритме бинарного поиска: т. к. все значения упорядочены, мы можем быстро определять области, в которых гарантированно не может быть данных, удовлетворяющих запрос, существенно снижая таким образом количество перебираемых записей.
Однако хранить индекс просто в виде отсортированного массива мы не можем, т. к. данные могут модифицироваться: значения могут меняться, записи — удаляться или добавляться. Чтобы эффективно поддерживать хранение индексируемых данных в отсортированном виде, индекс хранят в виде сбалансированного сильно ветвящегося дерева, называемого B-деревом (B-tree).
Корневой узел B-дерева содержит в упорядоченном виде несколько значений из общего набора, допустим, t элементов. Тогда все остальные элементы можно распределить по t+1 дочерним поддеревьям по следующему правилу:
- Первое поддерево будет содержать элементы, которые меньше, чем 1-й элемент корневого узла (на рисунке выше первое поддерево содержит числа, меньшие 30).
- Второе поддерево будет содержать элементы, которые находятся между 1-м и 2-м элементами корневого узла (на рисунке выше второе поддерево содержит числа между 30 и 70).
- И т. д. — последнее поддерево будет содержать элементы, большие элемента корневого узла с номером t (на рисунке выше третье поддерево содержит элементы, большие 70).
Каждое поддерево, в свою очередь, тоже является B-деревом, имеет корневой элемент и строится далее рекурсивно по такому же принципу.
За счет того что элементы в каждом узле отсортированы, при поиске мы сможем быстро определить, в каком поддереве может находиться искомый элемент, и не рассматривать вообще другие поддеревья. Допустим, нам нужно найти число 67:
- Корневой узел содержит числа 30 и 70, значит, искомый элемент следует искать во втором поддереве, т.к. 67 > 30 и 67 < 70.
- Корневой узел второго поддерева содержит элементы 40 и 50. Т. к. 67 > 50, искомый элемент следует искать в третьем потомке этого узла.
- На третьем шаге мы получили узел, не имеющий потомков, среди элементов которого находим искомое число 67.
Таким образом, при поиске в B-дереве необходимо максимум h раз выполнить линейный или бинарный поиск в относительно небольших списках, где h — это высота дерева. Т.к. B-дерево — сильно-ветвящееся и сбалансированное (т. е. при его построении и модификации применяются алгоритмы, сохраняющие его высоту минимальной, см. статью), число h обычно совсем невелико, и при росте общего количества элементов оно растет логарифмически. Как мы уже видели ранее, это приносит очень хорошие результаты.
Кроме того, важное и полезное свойство B-дерева при его использовании в СУБД — возможность эффективно хранить его во внешней памяти. Каждый узел B-дерева обычно хранит такой объем данных, который может быть эффективно записан на диск или прочитан за одну операцию ввода-вывода. B-дерево даже может не помещаться целиком в оперативной памяти. В этом случае СУБД может держать в памяти только узлы верхнего уровня (которые вероятно будут часто использоваться при поиске), читая узлы нижних уровней только при необходимости.
Индекс на основе B-дерева может ускорять запросы, которые используют не целиком входящие в индекс поля, а любую часть, начиная с начала. Например, индекс может ускорить запрос LIKE для поиска строк, которые начинаются с заданной подстроки:
SELECT * FROM table_name WHERE text_field LIKE 'start_substring%'
Если индекс построен по нескольким колонкам, он может ускорять запросы, в которых фигурируют одна или несколько первых колонок. Поэтому важен порядок, в котором мы указываем колонки при создании индекса. Допустим, у нас есть индекс по колонкам col_1 и col_2. Тогда он может использоваться в том числе для ускорения запроса вида:
SELECT * FROM table_name WHERE col_1 = 123
И нам не нужно создавать отдельный индекс для колонки col_1. Будет использоваться составной индекс (col_1, col_2).
Однако для запроса только по колонке col_2 такой составной индекс уже использовать не получится.
Подробнее, как индекс на основе B-дерева реализован в PostgreSQL, см. статью.
GiST и SP-GiST
GiST — сокращение от «generalized search tree». Это сбалансированное дерево поиска, точно так же, как и рассмотренный ранее b-tree. Но b-tree применимо только к тем типам данных, для которых имеет смысл операция сравнения и есть возможность упорядочивания. Но PostgreSQL позволяет хранить и такие данные, для которых операция упорядочивания не имеет смысла, например, геоданные и геометрические объекты.
Тут на помощь приходит индексный метод GiST. Он позволяет распределить данные любого типа по сбалансированному дереву и использовать это дерево для поиска по самым разным условиям. Если при построении B-дерева мы сортируем все множество объектов и делим его на части по принципу больше-меньше, при построении GiST индексов можно реализовать любой принцип разбиения любого множества объектов.
Например, в GiST-индекс можно уложить R-дерево для пространственных данных с поддержкой операторов взаимного расположения (находится слева, справа; содержит и т. д.). Такой индекс доступен в PostgreSQL и может быть полезен при разработке геоинформационных систем, в которых возникают запросы вида «получить множество объектов на карте, находящихся от заданной точки на расстоянии не более 1 км».
SP-GiST похож GiST, но он позволяет создавать несбалансированные деревья. Такие деревья могут быть полезны при разбиении множества на непересекающиеся объекты. Буквы SP означают space partitioning. К такому типу индексов можно отнести kd-деревья, реализация которых присутствует в PostgreSQL. Его, как и R-дерево, можно использовать для ускорения запросов геометрического поиска. Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты, что усложняет их эффективное хранение во внешней памяти.
Кроме того, GiST и SP-GiST могут служить своеобразным фреймворком, облегчающим расширение PostgreSQL и добавление в него совершенно новых видов деревьев для индексации новых типов данных.
Подробнее об алгоритмах, лежащих в основе R- и kd-деревьев см. раз и два, а об их реализации и использовании в PostgreSQL см. в этой и этой статье.
Заключение
Индексы — важнейший инструмент баз данных, ускоряющий поиск. Он не бесплатен, создавать много индексов без лишней необходимости не стоит — индексы занимают дополнительную память, и при любом обновлении проиндексированных данных СУБД должна выполнять дополнительную работу по поддержанию индекса в актуальном состоянии.
PostgreSQL поддерживает разные типы индексов для разных задач:
- B-дерево покрывает широчайший класс задач, т. к. применимо к любым данным, которые можно отсортировать.
- GiST и SP-GiST могут быть полезны при работе с геометрическими объектами и для создания совершенно новых типов индексов для новых типов данных.
- За рамками этой статьи оказался ещё один важный тип индексов — GIN. GIN индексы полезны для организации полнотекстового поиска и для индексации таких типов данных, как массивы или jsonb. Подробнее см. в статье. Современные версии PostgreSQL имеют вариацию такого индекса под названием RUM (см. статью).
Ссылки на полезные материалы
- Создание индекса в PostgreSQL
- Алгоритмы работы с B-деревом
- Релизация B-дерева в PostgreSQL
- R-дерево
- Kd-дерево
- Индекс типа GiST в PostgreSQL
- Индекс типа SP-GiST в PostgreSQL
- Индекс типа GIN в PostgreSQL
- Индекс типа RUM в PostgreSQL
Оценить
Великобритания 🇬🇧 — Почтовый индекс
Заглавная страница » Международный » ВеликобританияЭто страница с Великобритания почтовым кодом. Эта страница включает в себя следующее содержание: метод кода, пример конверта и формат адреса, способ правильного написания почтового кода, ссылка для запросов почтового индекса.
Envelope Example
Кодирование методом
Индекс площади в Великобритании состоит из 5-7 цифр, включая цифры и Letters.eg:eg:
EC1Y 8SY
ЕС представляет Почтовая Площадь, 1Y представляет почтовый район, 8 представляет почтового сектора, SY представляет пунктом доставки.
формат адреса
Mr. Walter C. Brown 49 Featherstone Street LONDON EC1Y 8SY UNITED KINGDOM
Великобритания индекс областях
- AB Aberdeen
- AL St. Albans
- B Birmingham
- BA Bath
- BB Blackburn
- BD Bradford
- BH Bournemouth
- BL Bolton
- BN Brighton
- BR Bromley
- BS Bristol
- BT Northern Ireland
- CA Carlisle
- CB Cambridge
- CF Cardiff
- CH Chester
- CM Chelmsford
- CO Colchester
- CR Croydon
- CT Canterbury
- CV Coventry
- CW Crewe
- DA Dartford
- DD Dundee
- DE Derby
- DG Dumfries
- DH Durham
- DL Darlington
- DN Doncaster
- DT Dorchester
- DY Dudley
- E London E
- EC London EC
- EH Edinburgh
- EN Enfield
- EX Exeter
- FK Falkirk
- FY Blackpool
- G Glasgow
- GL Gloucester
- GY Guernsey
- GU Guildford
- HA Harrow
- HD Huddersfield
- HG Harrogate
- HP Hemel Hempstead
- HR Hereford
- HS Outer Hebrides
- HU Hull
- HX Halifax
- IG Ilford
- IM Isle of Man
- IP Ipswich
- IV Inverness
- JE Jersey
- KA Kilmarnock
- KT Kingston Upon Thames
- KW Kirkwall
- KY Kirkcaldy
- L Liverpool
- LA Lancaster
- LD Llandrindod Wells
- LE Leicester
- LL Llandudno
- LN Lincoln
- LS Leeds
- LU Luton
- M Manchester
- ME Medway
- MK Milton Keynes
- ML Motherwell
- N London N
- NE Newcastle Upon Tyne
- NG Nottingham
- NN Northampton
- NP Newport
- NR Norwich
- NW London NW
- OL Oldham
- OX Oxford
- PA Paisley
- PE Peterborough
- PH Perth
- PL Plymouth
- PO Portsmouth
- PR Preston
- RG Reading
- RH Redhill
- RM Romford
- S Sheffield
- SA Swansea
- SE London SE
- SG Stevenage
- SK Stockport
- SL Slough
- SM Sutton
- SN Swindon
- SO Southampton
- SP Salisbury
- SR Sunderland
- SS Southend on Sea
- ST Stoke on Trent
- SW London SW
- SY Shrewsbury
- TA Taunton
- TD Galashiels
- TF Telford
- TN Tonbridge
- TQ Torquay
- TR Truro
- TS Cleveland
- TW Twickenham
- UB Southall
- W London W
- WA Warrington
- WC London WC
- WD Watford
- WF Wakefield
- WN Wigan
- WR Worcester
- WS Walsall
- WV Wolverhampton
- YO York
- ZE Lerwick
Ссылка Ссылки
- PostCodeBase: Великобритания Почтовый Индекс
- YouBianKu: Великобритания Почтовый Индекс
- официальный сайт (на английском языке)
- Почтовый индекс посмотреть (английский язык)
- Соединенное Королевство Великобритании и Северной Ирландии Индекс типа и положения Пример (на английском языке, PDF-файл)
- Почтовые индексы в Великобритании
Внешняя ссылка
- Википедия: Великобритания
- Код города Великобритания
- AreaCodeBase: Великобритания Код Зоны База Данных
- BizDirLib: Великобритания База данных бизнес-справочник
- PostCodeBase: Великобритания Страна Почтовый Индекс
- YouBianKu: Великобритания Индекс
Индекс страха на фондовом рынке: кто и как зарабатывает на нервозности инвесторов :: Новости :: РБК Инвестиции
Индекс страха действительно позволяет заработать на настроениях инвесторов. Пока одни начинают паниковать, другие пользуются суматохой. Вот как это устроено
Фото: Reimund Bertrams / Pixabay
Инвесторы всегда хотят предугадывать движение цен. Для этого они используют разные способы с той или иной степенью научности и полезности. Один из способов — использование опережающих индексов, к которым относятся индикаторы волатильности .
Самый известный из таких индикаторов — Индекс волатильности Чикагской биржи опционов VIX. Он также известен как индекс страха.
Как работает индекс страха VIX
Аналитики и инвесторы, использующие VIX, считают, что он измеряет настроение рынка относительно будущей волатильности. Иными словами, этот индекс демонстрирует уровень опасений инвесторов относительно будущих движений рынка.
Зная степень опасения инвесторов сейчас, можно предположить, в какую сторону совокупные настроения инвесторов направят котировки.
Каким же образом измеряются эти опасения? Главная идея, согласно которой используется индикатор волатильности, заключается в том, что в основе расчета индикатора лежат цены на опционы. Поэтому для понимания того, как это работает, нужно разобраться, как устроен опцион.
Что такое опцион
Опцион представляет собой специфический биржевой контракт, который наделяет купившего его инвестора правом купить или продать биржевой товар по определенной цене. В классической биржевой сделке речь идет об обязанности, а не праве.
Из-за этого свойства опцион часто используют для рыночной страховки инвестиций. Как это достигается? Рассмотрим, как используются опционы на примере нефти.
Опцион на нефть: пример расчета
Допустим, трейдер покупает нефть по цене $63,2, в то же самое время инвестор покупает опцион на право продажи нефти по $63,2 (цена исполнения опциона), заплатив за него определенную сумму — премию по опциону (ПО). Пусть ПО составит $1,5. Обладая таким правом, трейдер страхует свои вложения на случай, если цена упадет.
Если цена на нефть вырастет до $70, то трейдер получит $6,8 с каждого лота. После вычитания ПО в размере $1,5 чистая прибыль инвестора составит $5,3.
Но если цена на нефть упадет до $55, то трейдер может воспользоваться правом, которое дает ему опцион, и продать свою нефть по $63,2. Тогда инвестор потеряет только то, что он заплатил за опцион — ровно $1,5.
Такой опцион на право продажи называют опционом-пут — по-английски это звучит как put-option. Опцион на право покупки называют опционом-кол. В английском варианте — call-option.
Понятно, что при приведенной в примере цене за нефть опцион-пут по $64 будет стоить дороже, чем по $63,2. Таким же ограничением рисков занимаются трейдеры, которые продают биржевые товары. Часть таких игроков при продаже открывает короткую позицию .
Эти трейдеры порождают спрос на опционы-кол. Соответственно, текущее соотношение продавцов и покупателей, а также их настроения и ожидания будущего движения цен проявятся в ценах на пут- и кол-опционы. Таким образом, соизмеряя цены опционов, можно численно определить настроения инвесторов относительного движения цен.
И при чем тут нервозность инвесторов?
На этой закономерности построен индикатор VIX. В нем для расчета используются цены опционов на индекс S&P 500. Благодаря индексным фондам ETF и фьючерсам на индексы S&P 500 в какой-то степени сам стал биржевым товаром.
Чем больше инвесторов опасается падения рынка, тем больше вырастают премии на опционы-пут и снижаются премии на опционы-кол.
Напротив, если рынок уверен в росте, то премии на кол-опционы возрастут, на пут-опционы снизятся.
Но если рынок не уверен в направлении, тогда большинство участников опасаются непредвиденных движений и страхуются от них. Это проявится рост премий всех опционов — как пут, так и кол.
Расчет индекса производится таким образом, что чем больше размеры премий, тем больше значение индекса VIX.
Шкала страха от 0 до 100
Значения индекса VIX в теории располагаются на шкале от 0 до 100. Индекс рассчитывается с января 1990 года. Максимального в истории значения в 89,53 пункта индекс достигал 24 октября 2008 года, минимального — 8,56 пункта — 24 ноября 2017 года. Чаще всего значения индикатора располагаются в диапазоне от 15 до 40.
Если значение индикатора ниже 20 или 15, то опасения инвесторов относительно падения рынка невелики. Это значит, что рынки в среднесрочной и долгосрочной перспективе находятся в растущем тренде. Само снижение VIX ниже 20 можно воспринимать как повод задуматься о покупке американских ценных бумаг на долгосрочную перспективу.
Если значение индикатора превышает уровень 70–80, то теоретически это должно означать, что трейдеры стремятся максимально застраховаться. Причем уже не только от колебаний, но и от глубокого падения рынка.
После того как в октябре 2008 года индикатор достиг максимальных значений, американские индексы продолжили снижение, достигнув дна в марте 2009 года. Надо заметить, что на практике индикатор принимал значения выше 50 за всю свою историю только с октября 2008 года по март 2009-го включительно. Поэтому на деле использовать его для предсказания вхождения в нисходящий тренд более не представилось возможным.
Чаще всего трейдеры предпочитают ориентироваться на верхний предел 45. Нахождение индикатора выше 45 означает, что уровень страха на рынке достаточно высок и пока стоит воздержаться от покупок. Правда, как сигнал к продажам преодоление этих уровней воспринимать все же не стоит.
Если вы держите в портфеле ликвидные американские акции, то сигналом к началу продаж может служить превышение VIX значения 20. Кроме того, стоит следить за локальными минимумами индекса волатильности.
Когда очередной локальный минимум индекса оказался больше предыдущего значения и при этом соответствующие новые значения биржевых индексов (Dow Jones и NASDAQ) больше значений на дату предыдущего локального минимума VIX, то это так называемое расхождение — дивергенция. В таких случаях многие инвесторы закрывают часть своих длинных позиций .
Существует ли российский индекс страха
VIX может служить опережающим индикатором при торговле ценными бумагами, обращающимися на американских биржах. На российском рынке существует аналогичный индикатор RVI. Он мог бы служить измерительным ориентиром настроений инвесторов на российском фондовом рынке.
Индекс рассчитывается с 2014 года по методике, схожей с расчетом индекса страха VIX, но учитывает опционы на индекс РТС. Индекс РТС, в свою очередь, рассчитывается исходя из цен на российские акции в долларах США. Поскольку в расчет никак не принимается будущий курс рубля относительно доллара, то ориентироваться на RVI, торгуя ценными бумагами в рублях, все-таки не стоит.
Биржевой фонд, вкладывающий средства участников в акции по определенному принципу: например, в индекс, отрасль или регион. Помимо акций в состав фонда могут входить и другие инструменты: бонды, товары и пр. Термин, обозначающий вероятность быстрой продажи активов по рыночной или близкой к рыночной цене. Подробнее Изменчивость цены в определенный промежуток времени. Финансовый показатель в управлении финансовыми рисками. Характеризует тенденцию изменчивости цены – резкое падение или рост приводит к росту волатильности. Подробнее Торговая позиция при биржевых операциях. Она возникает, когда инвестор покупает ценные бумаги, валюту или товар в ожидании роста цен на них. В этом случае инвестор не ограничен во времени и может владеть инструментом (бумагой, валютой, товаром, контрактом и пр.) сколь угодно долго, отчего такая позиция получила название «длинной» Способ торговли на бирже, когда инвестор заимствует у брокера акции, которыми сам не владеет, чтобы продать их по текущей рыночной цене с тем, чтобы купить эти же акции по более низкой цене и извлечь выгоду. В этом случае инвестор ограничен сроками расчетов, а открытие короткой позиции сопряжено с высоким риском. Финансовый инстурмент, используемый для привлечения капитала. Основные типы ценных бумаг: акции (предоставляет владельцу право собственности), облигации (долговая ценная бумага) и их производные. ПодробнееРасчитать индекс массы тела, калькулятор ИМТ
Индекс массы тела (ИМТ)
Индекс массы тела является показателем отношения веса и роста человека. Данный параметр помогает определить отклонения от нормальной массы тела в ту или иную сторону. Лишний вес опасен для человеческого здоровья, поскольку часто приводят к сердечным заболеваниям. Онлайн калькулятор индекса массы тела позволяет быстро и точно узнать, насколько ваш показатель веса соответствует норме. Чтобы рассчитать индекс массы тела необходимо выбрать в представленном сервисе свой рост и вес.
Индекс массы тела для женщин считается нормальным, если показатель входит в диапазон от 20 до 22. Для мужчин этот показатель должен быть от 23 до 25. Статистика показывает, что люди, у которых данный показатель остается в пределах 18-22, живут в среднем дольше, чем те, у кого есть проблемы с весом.
Если показатель ИМТ превышает 25, то это сигнал, что вам нужно менять свой образ жизни. Важно отметить, что используемая формула для расчета индекса массы тела может переоценить показатель ожирения для людей атлетического сложения, поскольку вычисления не учитывают мышечную массу.
Индекс массы тела стал особенно актуален в западных странах, где проблема с ожирением встала достаточно остро. В самом начале расчет имт разрабатывался для социологических исследования, поэтому ставить медицинский диагноз с помощью этих расчетов не совсем правильно.
Однако доступность и простота расчета сделала данный калькулятор очень популярным среди населения. Если индекс превышает число 30, то это с большой долей вероятности говорит об ожирении.
Нужно понимать, что индекс массы тела не годится для постановления диагноза, но он может помочь в качестве контроля в процессе опробования новой фитнес-программы или диеты.
Калькулятор ИМТ определит точку отсчета и позволит прослеживать изменения веса тела.
Формула расчета индекса массы тела (ИМТ)
Для того, чтобы узнать свой ИМТ необходимо лишь свой вес в килограммах разделить на квадрат роста в метрах.
ИМТ = ВЕС / РОСТ2
Формула не учитывает пол и возраст человека, несмотря на то что ИМТ мужчин выше чем ИМТ женщин, а также ИМТ выше у людей среднего возраста, а у детей и пожилых людей этот показатель ниже.
Сводная таблица значений
Интерпретация показателей ИМТ, в соответствии с ремомендациями Всемирной Организации Здравоохранения (ВОЗ)
| 16 и менее | Выраженный дефицит массы тела |
| 16—18,5 | Недостаточная (дефицит) масса тела |
| 18,5—25 | Норма |
| 25—30 | Избыточная масса тела (предожирение) |
| 30—35 | Ожирение первой степени |
| 35—40 | Ожирение второй степени |
| 40 и более | Ожирение третьей степени (морбидное) |
Индексы научного цитирования для ученых ПетрГУ
РИНЦ, SCIENCE INDEX
Адрес входа: http://elibrary.ru/project_risc.asp
Российский индекс научного цитирования (РИНЦ) — это национальная информационно-аналитическая система, аккумулирующая более 2 миллионов публикаций российских авторов, а также информацию о цитировании этих публикаций из более 3000 российских журналов. Она предназначена не только для оперативного обеспечения научных исследований актуальной справочно-библиографической информацией, но является также и мощным инструментом, позволяющим осуществлять оценку результативности и эффективности деятельности научно-исследовательских организаций, ученых, уровень научных журналов и т.д.
Регистрация авторов
Регистрация пользователя в Научной электронной библиотеке является необходимым условием для получения доступа к полным текстам публикаций, размещенных на платформе eLIBRARY.RU, независимо от того, находятся ли они в открытом доступе или распространяются по подписке. Зарегистрированные пользователи также получают возможность создавать персональные подборки журналов, статей, сохранять историю поисковых запросов, настраивать панель навигатора и т.д.
Для работы с авторским профилем в системе SCIENCE INDEX также необходимо вначале зарегистрироваться, но уже в качестве автора. Регистрация автора в SCIENCE INDEX объединена с регистрацией пользователя на портале Научной электронной библиотеки eLIBRARY.RU. Для регистрации в SCIENCE INDEX нужно просто заполнить несколько дополнительных полей.
Основные функциональные возможности, которые предоставляются авторам научных публикаций
- просмотр списка своих публикаций в РИНЦ с возможностью его анализа и отбора по различным параметрам;
- просмотр списка ссылок на свои публикации с возможностью его анализа и отбора по различным параметрам;
- возможность добавить найденные в РИНЦ публикации в список своих работ;
- возможность добавить найденные в РИНЦ ссылки в список своих цитирований;
- возможность удалить из списка своих работ или цитирований ошибочно попавшие туда публикации или ссылки;
- возможность идентификации организаций, указанных в публикациях автора в качестве места выполнения работы;
- возможность глобального поиска по спискам цитируемой литературы;
- новый раздел анализа публикационной активности и цитируемости автора с возможностью расчета большого количества библиометрических показателей, их самостоятельного обновления и построения распределения публикаций и цитирований автора по различным параметрам;
- получение актуальных значений количества цитирований публикаций не только в РИНЦ, но и в Web of Science и Scopus с возможностью перехода на список цитирующих статей в этих базах данных при наличии подписки.
Приложение
Рис. 1. Авторы из ПетрГУ
Рис. 2. Пример публикации
Рис. 3. Пример анализа публикационной активности автора
Функция ИНДЕКС
Функция ИНДЕКС возвращает значение или ссылку на значение из таблицы или диапазона.
Есть два способа использовать функцию ИНДЕКС:
Если вы хотите вернуть значение указанной ячейки или массива ячеек, см. Форма массива.
Если вы хотите вернуть ссылку на указанные ячейки, см. Справочную форму.
Форма массива
Описание
Возвращает значение элемента в таблице или массиве, выбранном индексами номеров строк и столбцов.
Используйте форму массива, если первый аргумент INDEX является константой массива.
Синтаксис
ИНДЕКС (массив; номер_строки; [номер_столбца])
Форма массива функции ИНДЕКС имеет следующие аргументы:
массив Обязательно.Диапазон ячеек или константа массива.
Если массив содержит только одну строку или столбец, соответствующий аргумент row_num или column_num является необязательным.
Если в массиве более одной строки и более одного столбца и используется только row_num или column_num, INDEX возвращает массив всей строки или столбца в массиве.
row_num Обязательный, если не указан column_num.Выбирает строку в массиве, из которой нужно вернуть значение. Если row_num опущен, column_num является обязательным.
column_num Необязательно. Выбирает столбец в массиве, из которого нужно вернуть значение. Если column_num опущен, row_num является обязательным.
Примечания
Если используются аргументы row_num и column_num, INDEX возвращает значение в ячейке на пересечении row_num и column_num.
row_num и column_num должны указывать на ячейку в массиве; в противном случае ИНДЕКС возвращает # ССЫЛКУ! ошибка.
Если вы установите row_num или column_num равным 0 (ноль), INDEX вернет массив значений для всего столбца или строки, соответственно. Чтобы использовать значения, возвращаемые в виде массива, введите функцию ИНДЕКС как формулу массива.
Примечание: Если у вас текущая версия Microsoft 365, вы можете ввести формулу в верхнюю левую ячейку диапазона вывода, а затем нажать ENTER , чтобы подтвердить формулу как формулу динамического массива.В противном случае формулу необходимо ввести как формулу устаревшего массива, сначала выбрав диапазон вывода, введите формулу в верхнюю левую ячейку диапазона вывода, а затем нажмите CTRL + SHIFT + ENTER для подтверждения. Excel вставляет фигурные скобки в начало и конец формулы за вас. Дополнительные сведения о формулах массива см. В разделе Рекомендации и примеры формул массива.
Примеры
Пример 1
В этих примерах используется функция ИНДЕКС, чтобы найти значение в пересекающейся ячейке, где встречаются строка и столбец.
Скопируйте данные примера из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы формулы отображали результаты, выберите их, нажмите F2 , а затем нажмите Введите .
Данные | Данные | |
|---|---|---|
Яблоки | Лимоны | |
Бананы | Груши | |
Формула | Описание | Результат |
= ИНДЕКС (A2: B3,2,2) | Значение на пересечении второй строки и второго столбца в диапазоне A2: B3. | Груши |
= ИНДЕКС (A2: B3,2,1) | Значение на пересечении второй строки и первого столбца в диапазоне A2: B3. | Бананы |
Пример 2
В этом примере функция ИНДЕКС в формуле массива используется для поиска значений в двух ячейках, указанных в массиве 2×2.
Примечание: Если у вас текущая версия Microsoft 365, вы можете ввести формулу в верхнюю левую ячейку диапазона вывода, а затем нажать ENTER , чтобы подтвердить формулу как формулу динамического массива. В противном случае формулу необходимо ввести как формулу устаревшего массива, сначала выбрав две пустые ячейки, введите формулу в верхнюю левую ячейку выходного диапазона, а затем нажмите CTRL + SHIFT + ENTER для подтверждения. Excel вставляет фигурные скобки в начало и конец формулы за вас.Дополнительные сведения о формулах массива см. В разделе Рекомендации и примеры формул массива.
Формула | Описание | Результат |
|---|---|---|
= ИНДЕКС ({1,2 ; 3,4}, 0,2) | Значение, найденное в первой строке, втором столбце массива.Массив содержит 1 и 2 в первой строке и 3 и 4 во второй строке. | 2 |
Значение, найденное во второй строке, втором столбце массива (тот же массив, что и выше). | 4 | |
Верх страницы
Референсная форма
Описание
Возвращает ссылку на ячейку на пересечении определенной строки и столбца.Если ссылка состоит из несмежных выборок, вы можете выбрать выбор для просмотра.
Синтаксис
ИНДЕКС (ссылка; номер_строки; [номер_столбца]; [номер_площади])
Справочная форма функции ИНДЕКС имеет следующие аргументы:
ссылка Обязательно.Ссылка на один или несколько диапазонов ячеек.
Если вы вводите несмежный диапазон для ссылки, заключите ссылку в круглые скобки.
Если каждая область в ссылке содержит только одну строку или столбец, аргумент row_num или column_num, соответственно, является необязательным. Например, для ссылки на одну строку используйте ИНДЕКС (ссылка ,, номер_столбца).
row_num Обязательно. Номер строки в ссылке, из которой нужно вернуть ссылку.
column_num Необязательно. Номер столбца в ссылке, из которого нужно вернуть ссылку.
area_num Необязательно.Выбирает диапазон в ссылке, из которого нужно вернуть пересечение row_num и column_num. Первая выбранная или введенная область имеет номер 1, вторая — 2 и так далее. Если area_num опущено, INDEX использует область 1. Все перечисленные здесь области должны быть расположены на одном листе. Если вы укажете области, которые не находятся на одном листе друг с другом, это вызовет ошибку #VALUE! ошибка. Если вам нужно использовать диапазоны, которые расположены на разных листах друг от друга, рекомендуется использовать форму массива функции ИНДЕКС и использовать другую функцию для вычисления диапазона, составляющего массив.Например, вы можете использовать функцию ВЫБОР, чтобы вычислить, какой диапазон будет использоваться.
Например, если Ссылка описывает ячейки (A1: B4, D1: E4, G1: h5), area_num 1 — это диапазон A1: B4, area_num 2 — это диапазон D1: E4, а area_num 3 — это диапазон G1: h5.
Замечания
После того, как ссылка и area_num выбрали конкретный диапазон, row_num и column_num выбирают конкретную ячейку: row_num 1 — это первая строка в диапазоне, column_num 1 — это первый столбец и так далее.Ссылка, возвращаемая INDEX, является пересечением row_num и column_num.
Если вы установите row_num или column_num равным 0 (ноль), INDEX вернет ссылку для всего столбца или строки, соответственно.
row_num, column_num и area_num должны указывать на ячейку в пределах ссылки; в противном случае ИНДЕКС возвращает # ССЫЛКУ! ошибка. Если row_num и column_num опущены, INDEX возвращает область, указанную в ссылке area_num.
Результат функции ИНДЕКС является ссылкой и интерпретируется как таковой другими формулами. В зависимости от формулы возвращаемое значение ИНДЕКС может использоваться как ссылка или как значение. Например, формула CELL («ширина», ИНДЕКС (A1: B2,1,2)) эквивалентна CELL («ширина», B1). Функция ЯЧЕЙКА использует возвращаемое значение ИНДЕКС в качестве ссылки на ячейку. С другой стороны, такая формула, как 2 * INDEX (A1: B2,1,2), переводит возвращаемое значение INDEX в число в ячейке B1.
Примеры
Скопируйте данные примера из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы формулы отображали результаты, выберите их, нажмите F2, а затем нажмите Enter.
Фрукты | Цена | Счетчик |
|---|---|---|
Яблоки | $ 0.69 | 40 |
Бананы | $ 0,34 | 38 |
Лимоны | $ 0.55 | 15 |
Апельсины | $ 0,25 | 25 |
Груши | $ 0.59 | 40 |
Миндаль | $ 2,80 | 10 |
Кешью | $ 3.55 | 16 |
Арахис | $ 1,25 | 20 |
Грецкие орехи | $ 1.75 | 12 |
Формула | Описание | Результат |
= ИНДЕКС (A2: C6, 2, 3) | Пересечение второй строки и третьего столбца в диапазоне A2: C6, который является содержимым ячейки C3. | 38 |
= ИНДЕКС ((A1: C6, A8: C11), 2, 2, 2) | Пересечение второй строки и второго столбца во второй области A8: C11, которая является содержимым ячейки B9. | 1.25 |
= СУММ (ИНДЕКС (A1: C11, 0, 3, 1)) | Сумма третьего столбца в первой области диапазона A1: C11, которая является суммой C1: C11. | 216 |
= СУММ (B2: ИНДЕКС (A2: C6, 5, 2)) | Сумма диапазона, начинающегося с B2 и заканчивающегося на пересечении пятой строки и второго столбца диапазона A2: A6, который представляет собой сумму B2: B6. | 2,42 |
Верх страницы
См. Также
Функция ВПР
Функция ПОИСКПОЗ
КОСВЕННАЯ функция
Рекомендации и примеры формул массива
Функции поиска и ссылки (ссылка)
Функция ИНДЕКС— формула, примеры, как использовать указатель в Excel
Что такое функция ИНДЕКС?
Функция ИНДЕКС относится к категории функций поиска и справки Excel ФункцииСписок наиболее важных функций Excel для финансовых аналитиков.Эта шпаргалка охватывает 100 функций, которые критически важно знать аналитику Excel. Функция вернет значение в заданной позиции в диапазоне или массиве. Функция ИНДЕКС часто используется с функцией ПОИСКПОЗ. Функция ПОИСКПОЗ Функция ПОИСКПОЗ относится к функциям поиска и справочника Excel. Он ищет значение в массиве и возвращает позицию значения в массиве. Например, если мы хотим сопоставить значение 5 в диапазоне A1: A4, которое содержит значения 1,5,3,8, функция вернет 2, поскольку 5 является вторым элементом в диапазоне.Можно сказать, что это альтернативный способ сделать ВПР.
Как финансовый аналитик Описание работы финансового аналитика Описание работы финансового аналитика, приведенное ниже, дает типичный пример всех навыков, образования и опыта, необходимых для работы аналитиком в банке, учреждении или корпорации. Выполняйте финансовое прогнозирование, отчетность и отслеживание операционных показателей, анализируйте финансовые данные, создавайте финансовые модели. INDEX можно использовать в других формах анализа, помимо поиска значения в списке или таблице.В финансовом анализе мы можем использовать его вместе с другими функциями для поиска и возврата суммы столбца.
Есть два формата для функции ИНДЕКС:
- Формат массива
- Справочный формат
Формат массива функции ИНДЕКС
Формат массива используется, когда мы хотим вернуть значение указанная ячейка или массив ячеек.
Формула
= ИНДЕКС (массив, row_num, [col_num])
Функция использует следующие аргументы:
- Array (обязательный аргумент) — это указанный массив или диапазон клетки.
- Row_num (обязательный аргумент) — обозначает номер строки указанного массива. Если для аргумента установлено значение 0 или пусто, по умолчанию будут использоваться все строки в предоставленном массиве.
- Col_num (необязательный аргумент) — обозначает номер столбца указанного массива. Если для этого аргумента установлено значение 0 или пусто, по умолчанию будут использоваться все строки в предоставленном массиве.
Справочный формат функции ИНДЕКС
Справочный формат используется, когда мы хотим вернуть ссылку на ячейку на пересечении row_num и col_num.
Формула
= ИНДЕКС (ссылка, row_num, [column_num], [area_num])
Функция использует следующие аргументы:
- Reference (обязательный аргумент) — это ссылка в одну или несколько ячеек. Если мы вводим несколько областей непосредственно в функцию, отдельные области должны быть разделены запятыми и заключены в квадратные скобки. Например (A1: B2, C3: D4) и т. Д.
- Row_num (обязательный аргумент) — обозначает номер строки указанной области.Если для аргумента установлено значение 0 или пусто, по умолчанию будут использоваться все строки в предоставленном массиве.
- Col_num (необязательный аргумент) — обозначает номер столбца указанного массива. Если для аргумента установлено значение 0 или пусто, по умолчанию будут использоваться все строки в предоставленном массиве.
- Area_num (необязательный аргумент) — если ссылка предоставляется в виде нескольких диапазонов, area_num указывает, какой диапазон использовать. Области нумеруются в порядке их указания.
Если аргумент area_num опущен, по умолчанию используется значение 1 (т.е.е., ссылка берется из первой области в предоставленном диапазоне).
Как использовать функцию ИНДЕКС в Excel?
Чтобы понять использование функции, давайте рассмотрим несколько примеров:
Пример 1
Нам даны следующие данные, и мы хотим сопоставить расположение значения.
В таблице выше мы хотим увидеть расстояние, пройденное Уильямом. Используемая формула будет выглядеть так:
Мы получаем результат ниже:
Пример 2
Теперь давайте посмотрим, как использовать функции ПОИСКПОЗ и ИНДЕКС одновременно.Предположим, нам даны следующие данные:
Предположим, мы хотим узнать место Грузии в категории «Легкость ведения бизнеса». Мы будем использовать следующую формулу:
Здесь функция ПОИСКПОЗ будет искать Грузию и возвращать число 10, поскольку Грузия находится в списке 10. Функция ИНДЕКС принимает значение «10» во втором параметре (row_num), который указывает, из какой строки мы хотим вернуть значение, и превращается в простой = INDEX ($ C $ 2: $ C $ 11,3).
Получаем результат ниже:
Что нужно запомнить
- #VALUE! error — возникает, когда любой из заданных аргументов row_num, col_num или area_num не является числовым.
- # ССЫЛКА! ошибка — возникает по одной из следующих причин:
- Заданный аргумент row_num больше, чем количество строк в заданном диапазоне;
- Заданный аргумент [col_num] больше, чем количество столбцов в указанном диапазоне; или
- Заданный аргумент [area_num] больше, чем количество областей в указанном диапазоне.
- ВПР по сравнению с функцией ИНДЕКС
- ВПР Excel не может смотреть влево, а это означает, что значение поиска всегда должно находиться в крайнем левом столбце диапазона поиска. Это не относится к функциям ИНДЕКС и ПОИСКПОЗ.
- Формулы ВПР не работают или возвращают неверные результаты, когда новый столбец удаляется из или добавляется в таблицу поиска. С помощью INDEX и MATCH мы можем удалять или вставлять новые столбцы в таблицу поиска без искажения результатов.
Щелкните здесь, чтобы загрузить образец файла Excel
Дополнительные ресурсы
Спасибо, что прочитали руководство CFI по важным функциям Excel! Потратив время на изучение и освоение этих функций, вы значительно ускорите свой финансовый анализ. Чтобы узнать больше, ознакомьтесь с этими дополнительными ресурсами CFI:
- Расширенный курс формул Excel
- Расширенные формулы Excel, которые вы должны знать Расширенные формулы Excel, которые необходимо знать Эти расширенные формулы Excel очень важно знать и выведут ваши навыки финансового анализа на новый уровень.Загрузите нашу бесплатную электронную книгу Excel!
- Ярлыки Excel для ПК и MacExcel Ярлыки ПК MacExcel Ярлыки — Список наиболее важных и распространенных ярлыков MS Excel для пользователей ПК и Mac, специалистов в области финансов и бухгалтерского учета. Сочетания клавиш ускоряют ваши навыки моделирования и экономят время. Изучите редактирование, форматирование, навигацию, ленту, специальную вставку, манипулирование данными, редактирование формул и ячеек и другие краткие сведения
- Программа финансового аналитика Станьте сертифицированным аналитиком финансового моделирования и оценки (FMVA) ® Сертификат CFI’s Financial Modeling and Valuation Analyst (FMVA) ® поможет вам обрести уверенность в своей финансовой карьере.Запишитесь сегодня!
СООТВЕТСТВИЕ ИНДЕКСУ — Пошаговое руководство по Excel
Что такое СООТВЕТСТВИЕ ИНДЕКСА в Excel?
Формула СООТВЕТСТВИЕ ИНДЕКСА — это комбинация двух функций в Excel Ресурсы Excel Изучите Excel онлайн с помощью сотен бесплатных руководств, ресурсов, руководств и шпаргалок по Excel! Ресурсы CFI — лучший способ изучить Excel на своих условиях: INDEX и MATCH.
= ИНДЕКС () возвращает значение ячейки в таблице на основе номера столбца и строки.
= ПОИСКПОЗ () возвращает позицию ячейки в строке или столбце.
В сочетании две формулы могут искать и возвращать значение ячейки в таблице на основе вертикальных и горизонтальных критериев. Для краткости это называется просто функцией соответствия индекса. Чтобы увидеть видеоурок, посетите наш бесплатный ускоренный курс по Excel.
# 1 Как пользоваться формулой ИНДЕКС
Ниже приведена таблица, в которой указаны имена, рост и вес людей. Мы хотим использовать формулу ИНДЕКС, чтобы найти рост Кевина … вот пример того, как это сделать.
Выполните следующие действия:
- Введите «= ИНДЕКС (» и выберите область таблицы, затем добавьте запятую
- Введите номер строки для Кевина, равный «4», и добавьте запятую.
- Введите номер столбца для высоты, равный «2», и закрыть скобку
- Результат: «5.8. ”
# 2 Как использовать формулу MATCH
Придерживаясь того же примера, что и выше, давайте воспользуемся MATCH, чтобы выяснить, в какой строке находится Кевин.
Выполните следующие шаги:
- Введите «= MATCH» (»И укажите ссылку на ячейку, содержащую« Кевин »… имя, которое мы хотим найти.
- Выберите все ячейки в столбце« Имя »(включая заголовок« Имя »).
- Введите нулевой« 0 »для точного совпадения
- В результате Кевин находится в строке «4.»
Снова используйте ПОИСКПОЗ, чтобы определить высоту столбца.
Выполните следующие действия:
- Введите« = ПОИСКПОЗ (»и укажите ссылку на ячейку, содержащую« Высота »… критерии, которые мы хотим найти .
- Выберите все ячейки в верхней строке таблицы.
- Введите ноль «0» для точного совпадения.
- В результате высота будет указана в столбце «2.»
# 3 Как объединить ИНДЕКС и ПОИСКПОЗ
Теперь мы можем взять две формулы ПОИСКПОЗ и использовать их для замены «4» и «2» в исходной формуле ИНДЕКС.Результатом является формула ИНДЕКС ПОИСКПОЗ.
Выполните следующие действия:
- Вырежьте формулу MATCH для Кевина и замените ею цифру «4».
- Вырежьте формулу MATCH для высоты и замените на нее цифру «2».
- Результат: рост Кевина «5,8».
- Поздравляем, теперь у вас есть динамическая формула ПОИСКПОЗ!
Видеообъяснение того, как использовать соответствие индексов в Excel
Ниже приводится короткое видеоурок о том, как объединить две функции и эффективно использовать соответствие индексов в Excel! Дополнительные бесплатные руководства по Excel можно найти на канале CFI на YouTube.
Надеюсь, это короткое видео прояснило, как использовать эти две функции для значительного улучшения возможностей поиска в Excel.
Дополнительные уроки по Excel
Благодарим вас за то, что вы прочитали это пошаговое руководство по использованию INDEX MATCH в Excel. Чтобы продолжить обучение и совершенствовать свои навыки, вам будут полезны следующие дополнительные ресурсы CFI:
- Формулы и функции Excel ListFunctionsСписок наиболее важных функций Excel для финансовых аналитиков.Эта шпаргалка охватывает 100 функций, которые критически важно знать аналитику Excel.
- Ярлыки Excel Ярлыки Excel для ПК MacExcel Ярлыки — Список наиболее важных и распространенных ярлыков MS Excel для пользователей ПК и Mac, финансов и бухгалтеров. Сочетания клавиш ускоряют ваши навыки моделирования и экономят время. Изучите редактирование, форматирование, навигацию, ленту, специальную вставку, манипулирование данными, редактирование формул и ячеек и другие краткие сведения.
- Перейти к специальному Перейти к специальному Перейти к специальному в Excel — важная функция для электронных таблиц финансового моделирования.Клавиша F5 открывает «Перейти к», выберите «Специальные сочетания клавиш для формул Excel», что позволяет быстро выбрать все ячейки, соответствующие определенным критериям.
- Найти и заменить Найти и заменить в ExcelУзнайте, как выполнять поиск в Excel — это пошаговое руководство научит, как искать и заменять в электронных таблицах Excel с помощью сочетания клавиш Ctrl + F. Функция поиска и замены Excel позволяет быстро искать во всех ячейках и формулах электронной таблицы все экземпляры, соответствующие вашим критериям поиска. В этом руководстве будет рассказано, как создать оператор IF и FIF между двумя числами
- .Загрузите бесплатный шаблон для оператора IF между двумя числами в Excel.В этом руководстве мы шаг за шагом покажем вам, как вычислить IF с помощью оператора AND.
- функция в Excel Оператор IF между двумя числамиЗагрузите этот бесплатный шаблон для оператора IF между двумя числами в Excel. В этом руководстве мы шаг за шагом покажем вам, как вычислить IF с помощью оператора AND.
Что такое, типы индексов с ПРИМЕРАМИ
Что такое индексирование?
Индексирование — это метод построения структуры данных, который позволяет быстро извлекать записи из файла базы данных.Индекс — это небольшая таблица, состоящая всего из двух столбцов. Первый столбец содержит копию первичного или потенциального ключа таблицы. Его второй столбец содержит набор указателей для хранения адреса дискового блока, в котором хранится это конкретное значение ключа.
Индекс —
- Принимает ключ поиска в качестве ввода
- Эффективно возвращает коллекцию совпадающих записей.
Из этого руководства по индексированию СУБД вы узнаете:
Типы индексирования в СУБД
Тип индексов в базе данныхИндексирование в базе данных определяется на основе ее атрибутов индексации.Два основных типа методов индексации:
- Первичное индексирование
- Вторичное индексирование
Первичный индекс в СУБД
Первичный индекс — это упорядоченный файл фиксированной длины с двумя полями. Первое поле совпадает с первичным ключом, а второе поле указывает на этот конкретный блок данных. В первичном индексе между записями в индексной таблице всегда существует однозначное отношение.
Первичное индексирование в СУБД также делится на два типа.
Индекс плотности
В плотном индексе запись создается для каждого ключа поиска, указанного в базе данных. Это помогает вам выполнять поиск быстрее, но требует больше места для хранения индексных записей. В этом индексировании записи метода содержат значение ключа поиска и указывают на реальную запись на диске.
Редкий индекс
Это индексная запись, которая появляется только для некоторых значений в файле. Sparse Index помогает решить проблемы плотного индексирования в СУБД.В этом методе индексации в диапазоне столбцов индекса хранится один и тот же адрес блока данных, и, когда необходимо получить данные, будет выбран адрес блока.
Однако разреженный индекс хранит записи индекса только для некоторых значений ключа поиска. Ему требуется меньше места, меньше накладных расходов на обслуживание для вставки и удаления, но он медленнее по сравнению с плотным индексом для поиска записей.
Ниже приведен индекс базы данных Пример разреженного индекса
Вторичный индекс в СУБД
Вторичный индекс в СУБД может быть сгенерирован полем, которое имеет уникальное значение для каждой записи, и это должен быть ключ-кандидат.Он также известен как индекс без кластеризации.
Этот двухуровневый метод индексации базы данных используется для уменьшения размера отображения первого уровня. Для первого уровня из-за этого выбран большой диапазон чисел; размер отображения всегда остается небольшим.
Пример вторичного индекса
Давайте разберемся с вторичной индексацией на примере индекса базы данных:
В базе данных банковских счетов данные хранятся последовательно через acc_no; вы можете найти все счета в определенном филиале банка ABC.
Здесь у вас может быть вторичный индекс в СУБД для каждого ключа поиска. Индексная запись — это точка записи для корзины, которая содержит указатели на все записи с их конкретным значением ключа поиска.
Индекс кластеризации в СУБД
В кластеризованном индексе в индексе хранятся сами записи, а не указатели. Иногда индекс создается на столбцах, не являющихся первичными ключами, которые могут не быть уникальными для каждой записи. В такой ситуации вы можете сгруппировать два или более столбца, чтобы получить уникальные значения и создать индекс, который называется кластеризованным индексом.Это также поможет вам быстрее идентифицировать запись.
Пример:
Предположим, что компания наняла много сотрудников в разных отделах. В этом случае кластерное индексирование в СУБД необходимо создать для всех сотрудников одного отдела.
Считается в отдельном кластере, а точки индекса указывают на кластер в целом. Здесь Department _no — неуникальный ключ.
Что такое многоуровневый индекс?
Многоуровневое индексирование в базе данных создается, когда первичный индекс не помещается в памяти.В этом типе метода индексации вы можете уменьшить количество обращений к диску, чтобы сократить любую запись и сохранить на диске как последовательный файл, и создать разреженную базу на этом файле.
Индекс B-дерева
B-tree index — это широко используемые структуры данных для древовидной индексации в СУБД. Это многоуровневый формат индексирования на основе дерева в технике СУБД, который имеет сбалансированные бинарные деревья поиска. Все листовые узлы B-дерева обозначают фактические указатели данных.
Кроме того, все конечные узлы связаны списком ссылок, что позволяет B-дереву поддерживать как произвольный, так и последовательный доступ.
- Ведущие узлы должны иметь от 2 до 4 значений.
- Все пути от корня до листа в основном имеют одинаковую длину.
- Нелистовые узлы, кроме корневого, имеют от 3 до 5 дочерних узлов.
- Каждый узел, не являющийся корнем или листом, имеет от n / 2] до n дочерних узлов.
Преимущества индексирования
Важные плюсы / преимущества индексирования:
- Это помогает сократить общее количество операций ввода-вывода, необходимых для извлечения этих данных, поэтому вам не нужно обращаться к строке в базе данных из структуры индекса.
- Предлагает пользователям более быстрый поиск и извлечение данных.
- Индексирование также помогает уменьшить табличное пространство, поскольку вам не нужно связывать строку в таблице, так как нет необходимости хранить ROWID в индексе. Таким образом вы сможете уменьшить табличное пространство.
- Вы не можете сортировать данные в узлах лида, поскольку значение первичного ключа классифицирует их.
Недостатки индексации
Важные недостатки / минусы индексирования:
- Для выполнения индексирования системы управления базой данных вам понадобится первичный ключ в таблице с уникальным значением.
- Вы не можете выполнять какие-либо другие индексации в базе данных для проиндексированных данных.
- Вам не разрешено секционировать таблицу, организованную по индексу.
- Индексирование SQL Снижение производительности при запросах INSERT, DELETE и UPDATE.
Общая информация:
- Индексирование — это небольшая таблица, состоящая из двух столбцов.
- Два основных типа методов индексации: 1) Первичное индексирование 2) Вторичное индексирование.
- Первичный индекс — это упорядоченный файл фиксированной длины с двумя полями.
- Первичное индексирование также делится на два типа: 1) плотный индекс 2) разреженный индекс.
- В плотном индексе запись создается для каждого ключа поиска, указанного в базе данных.
- Метод разреженной индексации помогает решить проблемы плотной индексации.
- Вторичный индекс в СУБД — это метод индексации, ключ поиска которого определяет порядок, отличный от последовательного порядка файла.
- Индекс кластеризации определяется как файл данных заказа.
- Многоуровневое индексирование создается, когда первичный индекс не помещается в памяти.
- Самым большим преимуществом индексирования является то, что оно помогает сократить общее количество операций ввода-вывода, необходимых для извлечения этих данных.
- Самый большой недостаток выполнения системы управления базой данных индексации, вам нужен первичный ключ в таблице с уникальным значением.
Индексирование и выбор данных — документация pandas 1.3.4
Информация о маркировке осей в объектах pandas служит многим целям:
Идентифицирует данные (т.е. предоставляет метаданные ) с использованием известных индикаторов, важно для анализа, визуализации и отображения интерактивной консоли.
Включает автоматическое и явное выравнивание данных.
Позволяет интуитивно получать и настраивать подмножества набора данных.
В этом разделе мы сосредоточимся на последнем пункте: а именно, как нарезать, нарезать кубиками, и обычно получают и устанавливают подмножества объектов pandas. Основное внимание будет уделяться на Series и DataFrame, поскольку они получили больше внимания разработчиков в эта зона.
Примечание
Операторы индексации Python и NumPy [] и оператор атрибута . обеспечить быстрый и легкий доступ к структурам данных pandas в широком диапазоне
вариантов использования. Это делает интерактивную работу интуитивно понятной, так как мало нового
чтобы узнать, знаете ли вы, как работать со словарями Python и NumPy
массивы. Однако, поскольку тип данных, к которым будет осуществляться доступ, неизвестен в
заранее, прямое использование стандартных операторов имеет некоторые ограничения оптимизации.Для
производственного кода, мы рекомендуем вам воспользоваться оптимизированным
методы доступа к данным pandas, представленные в этой главе.
Предупреждение
Будет ли возвращена копия или ссылка для операции настройки, может
зависят от контекста. Иногда это называется присвоение цепочки и
необходимо избегать. См. Раздел «Возврат просмотра или копии».
См. MultiIndex / Advanced Indexing для MultiIndex и дополнительную документацию по индексированию.
См. Поваренную книгу для ознакомления с некоторыми расширенными стратегиями.
Различные варианты индексации
При выборе объекта был внесен ряд дополнений, запрошенных пользователем, чтобы поддерживать более явную индексацию на основе местоположения. pandas теперь поддерживает три типа многоосевой индексации.
.locв основном основан на метках, но также может использоваться с логическим массивом..locвызоветKeyError, если элементы не найдены. Допустимые вводы:Одинарная этикетка, e.грамм.
5или'a'(обратите внимание, что5интерпретируется как метка индекса. Это использование , а не целочисленной позиции вдоль показатель.).Список или массив меток
['a', 'b', 'c'].Объект-фрагмент с метками
'a': 'f'(Обратите внимание, что в отличие от обычного Python срезы, и запуск и остановка включены, если они присутствуют в показатель! См. Раздел «Нарезка с помощью этикеток» и конечные точки включены.)Логический массив (любые значения
NAбудут обрабатываться какFalse).вызываемая функцияс одним аргументом (вызывающая серия или DataFrame) и который возвращает допустимый результат для индексации (один из вышеперечисленных).
Подробнее см. Выбор по этикетке.
.ilocв основном основан на целочисленных позициях (от0доlength-1оси), но также может использоваться с логическим значением множество..ilocвызоветIndexError, если запрошено индексатор находится за пределами диапазона, кроме индексаторов среза , которые позволяют индексирование вне пределов. (это соответствует Python / NumPy slice семантика). Допустимые вводы:Целое число, например
5.Список или массив целых чисел
[4, 3, 0].Объект среза с целыми числами
1: 7.Логический массив (любые значения
NAбудут обрабатываться какFalse).вызываемая функцияс одним аргументом (вызывающая серия или DataFrame) и который возвращает допустимый результат для индексации (один из вышеперечисленных).
Подробнее см. Выбор по позиции, Расширенное индексирование и расширенное Иерархический.
.loc,.iloc, а также[]индексирование может приниматьвызываемыйв качестве индексатора. Дополнительные сведения см. В разделе «Выбор по вызываемому».
Для получения значений от объекта с многоосевым выделением используются следующие
обозначение (с использованием .loc в качестве примера, но следующее относится к .iloc как
хорошо). Любой из аксессоров осей может быть нулевым срезом : . Топоры остались вне
предполагается, что спецификация будет : , например p.loc ['a'] эквивалентно p.loc ['a',:,:] .
Тип объекта | Индексаторы |
|---|---|
Серия | |
DataFrame | |
Основы
Как упоминалось при представлении структур данных в последнем разделе, основная функция индексации с помощью [] (также известного как __getitem__ для тех, кто знаком с реализацией поведения классов в Python) выбирает
низкоразмерные срезы. В следующей таблице показаны значения возвращаемого типа, когда
индексирование объектов pandas с помощью [] :
Тип объекта | Выбор | Тип возвращаемого значения |
|---|---|---|
Серия | | скалярное значение |
DataFrame | | |
Здесь мы создаем простой набор данных временного ряда, чтобы использовать его для иллюстрации функциональность индексации:
В [1]: date = pd.диапазон_даты ('01.01.2000', периодов = 8)
В [2]: df = pd.DataFrame (np.random.randn (8, 4),
...: индекс = даты, столбцы = ['A', 'B', 'C', 'D'])
...:
В [3]: df
Из [3]:
А Б В Г
2000-01-01 0,469112 -0,282863 -1,509059 -1,135632
2000-01-02 1,212112 -0,173215 0,119209 -1,044236
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
2000-01-04 0,721555 -0,706771 -1,039575 0,271860
2000-01-05 -0,424972 0,567020 0,276232 -1,087401
2000-01-06 -0.673690 0,113648 -1,478427 0,524988
2000-01-07 0,404705 0,577046 -1,715002 -1,039268
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885
Примечание
Ни одна из функций индексирования не зависит от временных рядов, если только конкретно указано.
Таким образом, как описано выше, у нас самая простая индексация с использованием [] :
В [4]: s = df ['A'] В [5]: s [даты [5]] Выход [5]: -0.6736897080883706
Вы можете передать список столбцов в [] , чтобы выбрать столбцы в указанном порядке.Если столбец не содержится в DataFrame, будет исключение
поднятый. Также можно задать несколько столбцов:
В [6]: df
Из [6]:
А Б В Г
2000-01-01 0,469112 -0,282863 -1,509059 -1,135632
2000-01-02 1,212112 -0,173215 0,119209 -1,044236
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
2000-01-04 0,721555 -0,706771 -1,039575 0,271860
2000-01-05 -0,424972 0,567020 0,276232 -1,087401
2000-01-06 -0,673690 0,113648 -1,478427 0.524988
2000-01-07 0,404705 0,577046 -1,715002 -1,039268
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885
В [7]: df [['B', 'A']] = df [['A', 'B']]
В [8]: df
Из [8]:
А Б В Г
2000-01-01 -0,282863 0,469112 -1,509059 -1,135632
2000-01-02 -0,173215 1,212112 0,119209 -1,044236
2000-01-03 -2,104569 -0,861849 -0,494929 1,071804
2000-01-04 -0,706771 0,721555 -1,039575 0,271860
2000-01-05 0,567020 -0,424972 0,276232 -1,087401
2000-01-06 0,113648 -0.673690 -1,478427 0,524988
2000-01-07 0,577046 0,404705 -1,715002 -1,039268
2000-01-08 -1,157892 -0,370647 -1,344312 0,844885
Вы можете найти это полезным для применения преобразования (на месте) к подмножеству столбцы.
Предупреждение
pandas выравнивает все ОСИ при установке Series и DataFrame из .loc и .iloc .
Это приведет к изменению , а не df , поскольку выравнивание столбца выполняется до присвоения значения.
В [9]: df [['A', 'B']]
Из [9]:
А Б
2000-01-01 -0,282863 0,469112
2000-01-02 -0,173215 1,212112
2000-01-03 -2,104569 -0,861849
2000-01-04 -0,706771 0,721555
2000-01-05 0,567020 -0,424972
2000-01-06 0,113648 -0,673690
2000-01-07 0,577046 0,404705
2000-01-08 -1,157892 -0,370647
В [10]: df.loc [:, ['B', 'A']] = df [['A', 'B']]
В [11]: df [['A', 'B']]
Из [11]:
А Б
2000-01-01 -0,282863 0,469112
2000-01-02 -0,173215 1,212112
2000-01-03 -2.104569 -0,861849
2000-01-04 -0,706771 0,721555
2000-01-05 0,567020 -0,424972
2000-01-06 0,113648 -0,673690
2000-01-07 0,577046 0,404705
2000-01-08 -1,157892 -0,370647
Правильный способ поменять местами значения столбцов — использовать необработанные значения:
В [12]: df.loc [:, ['B', 'A']] = df [['A', 'B']]. To_numpy ()
В [13]: df [['A', 'B']]
Из [13]:
А Б
2000-01-01 0,469112 -0,282863
2000-01-02 1,212112 -0,173215
2000-01-03 -0,861849 -2,104569
2000-01-04 0,721555 -0.706771
2000-01-05 -0,424972 0,567020
2000-01-06 -0,673690 0,113648
2000-01-07 0,404705 0,577046
2000-01-08 -0,370647 -1,157892
Доступ к атрибуту
Вы можете получить доступ к индексу на Series или столбцу на DataFrame напрямую
в качестве атрибута:
В [14]: sa = pd.Series ([1, 2, 3], index = list ('abc'))
В [15]: dfa = df.copy ()
В [16]: sa.b Вых [16]: 2 В [17]: dfa.A Из [17]: 2000-01-01 0,469112 2000-01-02 1.212112 2000-01-03 -0.861849 2000-01-04 0,721555 2000-01-05 -0,424972 2000-01-06 -0,673690 2000-01-07 0,404705 2000-01-08 -0,370647 Freq: D, имя: A, dtype: float64
В [18]: sa.a = 5
В [19]: sa
Из [19]:
а 5
Би 2
c 3
dtype: int64
В [20]: dfa.A = list (range (len (dfa.index))) # нормально, если A уже существует
В [21]: dfa
Из [21]:
А Б В Г
2000-01-01 0 -0,282863 -1,509059 -1,135632
2000-01-02 1 -0,173215 0,119209 -1,044236
2000-01-03 2 -2.104569 -0.494929 1,071804
2000-01-04 3-0,706771 -1,039575 0,271860
2000-01-05 4 0,567020 0,276232 -1,087401
2000-01-06 5 0,113648 -1,478427 0,524988
2000-01-07 6 0,577046 -1,715002 -1,039268
2000-01-08 7 -1,157892 -1,344312 0,844885
В [22]: dfa ['A'] = list (range (len (dfa.index))) # используйте эту форму для создания нового столбца
В [23]: dfa
Из [23]:
А Б В Г
2000-01-01 0 -0,282863 -1,509059 -1,135632
2000-01-02 1 -0,173215 0,119209 -1,044236
2000-01-03 2 -2.104569 -0.494929 1,071804
2000-01-04 3-0,706771 -1,039575 0,271860
2000-01-05 4 0,567020 0,276232 -1,087401
2000-01-06 5 0,113648 -1,478427 0,524988
2000-01-07 6 0,577046 -1,715002 -1,039268
2000-01-08 7 -1,157892 -1,344312 0,844885
Предупреждение
Вы можете использовать этот доступ, только если элемент индекса является действительным идентификатором Python, например
с.1не допускается. См. Здесь объяснение допустимых идентификаторов.Атрибут будет недоступен, если он конфликтует с существующим именем метода, например.грамм.
с.минне разрешено, нос ['мин »]возможно.Точно так же атрибут будет недоступен, если он конфликтует с любым из следующего списка:
index,главная_ ось,второстепенная ось,позиции.В любом из этих случаев стандартное индексирование по-прежнему будет работать, например
с ['1'],с ['min']ис ['index']будет доступ к соответствующему элементу или столбцу.
Если вы используете среду IPython, вы также можете использовать завершение табуляции для увидеть эти доступные атрибуты.
Вы также можете назначить dict строке DataFrame :
В [24]: x = pd.DataFrame ({'x': [1, 2, 3], 'y': [3, 4, 5]})
В [25]: x.iloc [1] = {'x': 9, 'y': 99}
В [26]: x
Из [26]:
х у
0 1 3
1 9 99
2 3 5
Вы можете использовать доступ к атрибутам для изменения существующего элемента Series или столбца DataFrame, но будьте осторожны;
если вы попытаетесь использовать доступ к атрибутам для создания нового столбца, он создаст новый атрибут, а не
новый столбец.В версии 0.21.0 и новее это вызовет UserWarning :
В [1]: df = pd.DataFrame ({'one': [1., 2., 3.]})
В [2]: df.two = [4, 5, 6]
UserWarning: Pandas не позволяет назначать серии несуществующим столбцам - см. Https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute_access
В [3]: df
Из [3]:
один
0 1.0
1 2,0
2 3,0
Диапазон нарезки
Самый надежный и последовательный способ нарезки диапазонов по произвольным осям — это
описано в разделе «Выбор по позиции»
детализация .iloc метод. А пока мы объясним семантику нарезки с помощью оператора [] .
С Series синтаксис работает точно так же, как с ndarray, возвращая часть значения и соответствующие метки:
В [27]: s [: 5] Из [27]: 2000-01-01 0,469112 2000-01-02 1.212112 2000-01-03 -0,861849 2000-01-04 0,721555 2000-01-05 -0,424972 Freq: D, имя: A, dtype: float64 В [28]: s [:: 2] Из [28]: 2000-01-01 0,469112 2000-01-03 -0,861849 2000-01-05 -0.424972 2000-01-07 0,404705 Freq: 2D, имя: A, dtype: float64 В [29]: s [:: - 1] Из [29]: 2000-01-08 -0,370647 2000-01-07 0,404705 2000-01-06 -0,673690 2000-01-05 -0,424972 2000-01-04 0,721555 2000-01-03 -0,861849 2000-01-02 1.212112 2000-01-01 0,469112 Freq: -1D, имя: A, dtype: float64
Обратите внимание, что настройка также работает:
В [30]: s2 = s.copy () В [31]: s2 [: 5] = 0 В [32]: s2 Из [32]: 2000-01-01 0,000000 2000-01-02 0,000000 2000-01-03 0.000000 2000-01-04 0,000000 2000-01-05 0,000000 2000-01-06 -0,673690 2000-01-07 0,404705 2000-01-08 -0,370647 Freq: D, имя: A, dtype: float64
С DataFrame нарезка внутри [] нарезает строки . Это предусмотрено
в основном для удобства, поскольку это обычная операция.
В [33]: df [: 3]
Из [33]:
А Б В Г
2000-01-01 0,469112 -0,282863 -1,509059 -1,135632
2000-01-02 1,212112 -0,173215 0.119209 -1,044236
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
В [34]: df [:: - 1]
Из [34]:
А Б В Г
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885
2000-01-07 0,404705 0,577046 -1,715002 -1,039268
2000-01-06 -0,673690 0,113648 -1,478427 0,524988
2000-01-05 -0,424972 0,567020 0,276232 -1,087401
2000-01-04 0,721555 -0,706771 -1,039575 0,271860
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804
2000-01-02 1,212112 -0,173215 0,119209 -1,044236
2000-01-01 0.469112 -0,282863 -1,509059 -1,135632
Выбор по этикетке
Предупреждение
Будет ли возвращена копия или ссылка для операции настройки, может зависеть от контекста.
Иногда это называется присвоением цепочки , и его следует избегать.
См. Раздел «Возврат просмотра или копии».
Предупреждение
.locявляется строгим, когда вы представляете срезы, которые не совместимы (или конвертируются) с типом индекса. Например используя целые числа вDatetimeIndex.Это вызоветTypeError.
В [35]: dfl = pd.DataFrame (np.random.randn (5, 4),
....: columns = list ('ABCD'),
....: index = pd.date_range ('20130101', периоды = 5))
....:
В [36]: dfl
Из [36]:
А Б В Г
2013-01-01 1.075770 -0.109050 1.643563 -1.469388
2013-01-02 0,357021 -0,674600 -1,776904 -0,968914
2013-01-03 -1.294524 0,413738 0,276662 -0,472035
2013-01-04 -0.013960 -0.362543 -0,006154 -0,1
2013-01-05 0,895717 0,805244 -1,206412 2,565646
В [4]: dfl.loc [2: 3] TypeError: невозможно выполнить индексирование срезов нас этими индексаторами [2]
Строка в разрезе может преобразовываться в тип индекса и приводить к естественному разрезанию.
В [37]: dfl.loc ['20130102': '20130104']
Из [37]:
А Б В Г
2013-01-02 0.357021 -0,674600 -1,776904 -0,968914
2013-01-03 -1.294524 0,413738 0,276662 -0,472035
2013-01-04 -0,013960 -0,362543 -0,006154 -0,1
pandas предоставляет набор методов для индексирования только на основе меток . Это протокол, основанный на строгом включении.
Каждая запрошенная метка должна быть в индексе, в противном случае возникнет KeyError .
При нарезке как начальная граница , так и граница остановки включены , если они присутствуют в индексе.Целые числа являются допустимыми метками, но они относятся к метке , а не к позиции .
Атрибут .loc является основным методом доступа. Допустимые значения:
Одна этикетка, например
5или'a'(обратите внимание, что5интерпретируется как метка индекса. Это использование , а не как целое число вдоль индекса.).Список или массив меток
['a', 'b', 'c'].Объект-фрагмент с метками
'a': 'f'(Обратите внимание, что в отличие от обычного Python срезы, и запуск и остановка включены, если они присутствуют в показатель! См. Раздел "Нарезка с помощью этикеток".Логический массив.
A
, вызываемый, см. Выбор по вызываемому.
В [38]: s1 = pd.Series (np.random.randn (6), index = list ('abcdef'))
В [39]: s1
Из [39]:
а 1.431256
б 1.340309
c -1.170299
d -0,226169
e 0,410835
f 0,813850
dtype: float64
В [40]: s1.loc ['c':]
Из [40]:
с -1.170299
d -0,226169
e 0,410835
f 0,813850
dtype: float64
В [41]: s1.loc ['b']
Из [41]: 1.3403088497993827
Обратите внимание, что настройка также работает:
В [42]: s1.loc ['c':] = 0 В [43]: s1 Из [43]: а 1.431256 б 1.340309 с 0,000000 г 0,000000 е 0,000000 f 0,000000 dtype: float64
с DataFrame:
В [44]: df1 = pd.DataFrame (np.random.randn (6, 4),
....: index = list ('abcdef'),
....: columns = list ('ABCD'))
....:
В [45]: df1
Из [45]:
А Б В Г
а 0,132003 -0,827317 -0,076467 -1,187678
б 1.130127 -1.436737 -1.413681 1.607920
в 1.024180 0.569605 0.875906 -2.211372
г 0,974466 -2,006747 -0,410001 -0,078638
е 0,545952 -1,219217 -1,226825 0,769804
ф -1,281247 -0,727707 -0,121306 -0,097883
В [46]: df1.loc [['a', 'b', 'd'],:]
Из [46]:
А Б В Г
а 0.132003 -0,827317 -0,076467 -1,187678
б 1.130127 -1.436737 -1.413681 1.607920
г 0,974466 -2,006747 -0,410001 -0,078638
Доступ через срезы этикеток:
В [47]: df1.loc ['d' :, 'A': 'C']
Из [47]:
А Б В
д 0,974466 -2,006747 -0,410001
е 0,545952 -1,219217 -1,226825
ф -1,281247 -0,727707 -0,121306
Для получения поперечного сечения с помощью метки (эквивалент df.xs ('a') ):
В [48]: df1.loc ['a'] Из [48]: А 0.132003 В -0,827317 С -0.076467 D -1.187678 Имя: a, dtype: float64
Для получения значений с помощью логического массива:
В [49]: df1.loc ['a']> 0
Из [49]:
Правда
B ложно
C Ложь
D Ложь
Имя: a, dtype: bool
В [50]: df1.loc [:, df1.loc ['a']> 0]
Из [50]:
А
а 0,132003
б 1.130127
в 1.024180
г 0,974466
e 0,545952
f -1,281247
значений NA в логическом массиве распространяются как False :
Изменено в версии 1.0.2.
В [51]: mask = pd.array ([True, False, True, False, pd.NA, False], dtype = "boolean") В [52]: маска Из [52]:[Верно, Ложно, Верно, Ложно, , Ложно] Длина: 6, dtype: boolean В [53]: df1 [маска] Из [53]: А Б В Г а 0,132003 -0,827317 -0,076467 -1,187678 в 1.024180 0.569605 0.875906 -2.211372
Для явного получения значения:
# это также эквивалентно `df1.at ['a', 'A']` ` В [54]: df1.loc ['a', 'A'] Аут [54]: 0.13200317033032932
Нарезка с этикетками
При использовании .loc со срезами, если метки начала и конца
присутствуют в индексе, то элементы расположены между двумя (включая их)
возвращаются:
В [55]: s = pd.Series (list ('abcde'), index = [0, 3, 2, 5, 4])
В [56]: s.loc [3: 5]
Из [56]:
3 б
2 с
5 дней
dtype: объект
Если хотя бы один из двух отсутствует, но индекс отсортирован и может быть по сравнению с метками начала и остановки, то нарезка будет по-прежнему работать как ожидается, выбрав метки, которые ранжируют между двумя:
В [57]: с.sort_index () Из [57]: 0 а 2 с 3 б 4 е 5 дней dtype: объект В [58]: s.sort_index (). Loc [1: 6] Из [58]: 2 с 3 б 4 е 5 дней dtype: объект
Однако, если хотя бы один из двух отсутствует и , индекс не сортируется,
возникнет ошибка (поскольку в противном случае это было бы дорогостоящим с точки зрения вычислений,
а также потенциально неоднозначный для индексов смешанного типа). Например, в
В приведенном выше примере s.loc [1: 6] вызовет KeyError .
Обоснование такого поведения см. Конечные точки включены.
В [59]: s = pd.Series (list ('abcdef'), index = [0, 3, 2, 5, 4, 2])
В [60]: s.loc [3: 5]
Из [60]:
3 б
2 с
5 дней
dtype: объект
Кроме того, если в индексе есть повторяющиеся метки и , либо начальная, либо конечная метка дублируются,
возникнет ошибка. Например, в приведенном выше примере s.loc [2: 5] вызовет KeyError .
Для получения дополнительной информации о повторяющихся этикетках см. Повторяющиеся ярлыки.
Выбор по позиции
Предупреждение
Будет ли возвращена копия или ссылка для операции настройки, может зависеть от контекста.Иногда это называется присвоением цепочки , и его следует избегать.
См. Раздел «Возврат просмотра или копии».
pandas предоставляет набор методов для получения полностью целочисленной индексации . Семантика близко соответствует нарезке Python и NumPy. Это индексация на основе 0. При нарезке начальная граница - , включая , а верхняя граница - , исключая . Попытка использовать нецелое число, даже допустимая метка вызовет IndexError .
Атрибут .iloc является основным методом доступа. Допустимые значения:
Целое число, например
5.Список или массив целых чисел
[4, 3, 0].Объект среза с целыми числами
1: 7.Логический массив.
A
, вызываемый, см. Выбор по вызываемому.
В [61]: s1 = pd.Series (np.random.randn (5), индекс = список (диапазон (0, 10, 2))) В [62]: s1 Из [62]: 0 0,695775 2 0,341734 4 0,959726 6 -1,110336 8 -0,619976 dtype: float64 В [63]: s1.iloc [: 3] Из [63]: 0 0,695775 2 0,341734 4 0,959726 dtype: float64 В [64]: s1.iloc [3] Из [64]: -1.1103361028
Обратите внимание, что настройка также работает:
В [65]: s1.iloc [: 3] = 0 В [66]: s1 Из [66]: 0 0,000000 2 0,000000 4 0,000000 6 -1,110336 8 -0,619976 dtype: float64
с DataFrame:
В [67]: df1 = pd.DataFrame (np.random.randn (6, 4),
....: index = list (диапазон (0, 12, 2)),
....: columns = list (диапазон (0, 8, 2)))
....:
В [68]: df1
Из [68]:
0 2 4 6
0 0,149748 -0,732339 0,687738 0,176444
2 0,403310 -0,154951 0,301624 -2,179861
4 -1,369849 -0,954208 1,462696 -1,743161
6 -0,826591 -0,345352 1,314232 0,6
8 0,995761 2,396780 0,014871 3,357427
10 -0,317441 -1,236269 0,896171 -0,487602
Выбор с помощью целочисленного нарезания:
В [69]: df1.iloc [: 3]
Из [69]:
0 2 4 6
0 0,149748 -0,732339 0,687738 0,176444
2 0,403310 -0,154951 0,301624 -2,179861
4 -1,369849 -0,954208 1,462696 -1,743161
В [70]: df1.iloc [1: 5, 2: 4]
Из [70]:
4 6
2 0,301624 -2,179861
4 1,462696 -1,743161
6 1,314232 0,6
8 0,014871 3,357427
Выбрать через целочисленный список:
В [71]: df1.iloc [[1, 3, 5], [1, 3]]
Из [71]:
2 6
2 -0,154951 -2,179861
6 -0,345352 0,6
10 -1.236269 -0,487602
В [72]: df1.iloc [1: 3,:]
Из [72]:
0 2 4 6
2 0,403310 -0,154951 0,301624 -2,179861
4 -1,369849 -0,954208 1,462696 -1,743161
В [73]: df1.iloc [:, 1: 3]
Из [73]:
2 4
0 -0,732339 0,687738
2 -0,154951 0,301624
4 -0,954208 1,462696
6 -0,345352 1,314232
8 2,396780 0,014871
10 -1,236269 0,896171
# это также эквивалентно `df1.iat [1,1]` В [74]: df1.iloc [1, 1] Аут [74]: -0.1549507744249032
Для получения поперечного сечения с использованием целочисленной позиции (эквивалент df.xs (1) ):
В [75]: df1.iloc [1] Из [75]: 0 0,403310 2 -0,154951 4 0,301624 6 -2,179861 Имя: 2, dtype: float64
Индексы срезов вне диапазона обрабатываются изящно, как в Python / NumPy.
# это разрешено в Python / NumPy.
В [76]: x = list ('abcdef')
В [77]: x
Out [77]: ['a', 'b', 'c', 'd', 'e', 'f']
В [78]: x [4:10]
Out [78]: ['e', 'f']
В [79]: x [8:10]
Из [79]: []
В [80]: s = pd.Серия (x)
В [81]: s
Из [81]:
0 а
1 б
2 с
3 дн.
4 е
5 ж
dtype: объект
В [82]: s.iloc [4:10]
Из [82]:
4 е
5 ж
dtype: объект
В [83]: s.iloc [8:10]
Out [83]: Series ([], dtype: object)
Обратите внимание, что использование срезов, выходящих за границы, может привести к пустая ось (например, возвращается пустой DataFrame).
В [84]: dfl = pd.DataFrame (np.random.randn (5, 2), columns = list ('AB'))
В [85]: dfl
Из [85]:
А Б
0 -0,082240 -2,182937
1 0,380396 0.084844
2 0,432390 1,519970
3 -0,493662 0,600178
4 0,274230 0,132885
В [86]: dfl.iloc [:, 2: 3]
Из [86]:
Пустой фрейм данных
Столбцы: []
Индекс: [0, 1, 2, 3, 4]
В [87]: dfl.iloc [:, 1: 3]
Из [87]:
B
0 -2,182937
1 0,084844
2 1,519970
3 0,600178
4 0,132885
В [88]: dfl.iloc [4: 6]
Из [88]:
А Б
4 0,27423 0,132885
Один индексатор, выходящий за границы, вызовет IndexError .
Список индексаторов, у которых какой-либо элемент выходит за границы, вызовет IndexError .
>>> dfl.iloc [[4, 5, 6]] IndexError: позиционные индексаторы находятся за пределами >>> dfl.iloc [:, 4] IndexError: одиночный позиционный индексатор находится за пределами
Выбор по телефону
.loc , .iloc , а также [] indexing может принимать вызываемый в качестве индексатора.
Вызываемый должен быть функцией с одним аргументом (вызывающий Series или DataFrame), который возвращает допустимые выходные данные для индексации.
В [89]: df1 = pd.DataFrame (np.random.randn (6, 4),
....: index = list ('abcdef'),
....: columns = list ('ABCD'))
....:
В [90]: df1
Из [90]:
А Б В Г
а -0,023688 2,410179 1,450520 0,206053
б -0,251905 -2,213588 1,063327 1,266143
в 0,299368 -0,863838 0,408204 -1,048089
г -0,025747 -0,988387 0,094055 1,262731
е 1,289997 0,082423 -0,055758 0,536580
ф -0,489682 0,369374 -0,034571 -2,484478
В [91]: df1.loc [lambda df: df ['A']> 0,:]
Из [91]:
А Б В Г
с 0.299368 -0,863838 0,408204 -1,048089
е 1,289997 0,082423 -0,055758 0,536580
В [92]: df1.loc [:, lambda df: ['A', 'B']]
Из [92]:
А Б
а -0,023688 2,410179
б -0,251905 -2,213588
в 0,299368 -0,863838
г -0,025747 -0,988387
е 1,289997 0,082423
ж -0,489682 0,369374
В [93]: df1.iloc [:, lambda df: [0, 1]]
Из [93]:
А Б
а -0,023688 2,410179
б -0,251905 -2,213588
в 0,299368 -0,863838
г -0,025747 -0,988387
е 1,289997 0,082423
ж -0,489682 0,369374
В [94]: df1 [лямбда df: df.столбцы [0]]
Из [94]:
а -0,023688
б -0,251905
в 0,299368
d -0,025747
e 1.289997
f -0,489682
Имя: A, dtype: float64
Вы можете использовать вызываемую индексацию в серии .
В [95]: df1 ['A']. Loc [лямбда s: s> 0] Из [95]: в 0,299368 e 1.289997 Имя: A, dtype: float64
Используя эти методы / индексаторы, вы можете связать операции выбора данных без использования временной переменной.
В [96]: bb = pd.read_csv ('data / baseball.csv', index_col = 'id')
В [97]: (bb.groupby (['год', 'команда']). sum ()
....: .loc [лямбда df: df ['r']> 100])
....:
Из [97]:
stint g ab r h X2b X3b hr rbi sb cs bb so ibb hbp sh sf gidp
годовая команда
2007 КИН 6 379 745 101 203 35 2 36 125,0 10,0 1,0 105 127,0 14,0 1,0 1,0 15,0 18,0
ДЕТ 5 301 1062 162 283 54 4 37 144,0 24,0 7.0 97 176,0 3,0 10,0 4,0 8,0 28,0
ХОУ 4 311 926 109 218 47 6 14 77,0 10,0 4,0 60 212,0 3,0 9,0 16,0 6,0 17,0
LAN 11413 1021 153293 61 3 36 154,0 7,0 5,0 114 141,0 8,0 9,0 3,0 8,0 29,0
NYN 13 622 1854 240 509 101 3 61 243,0 22,0 4,0 174 310,0 24,0 23,0 18,0 15,0 48,0
SFN 5 482 1305 198 337 67 6 40 171,0 26,0 7,0 235 188,0 51,0 8,0 16,0 6,0 41,0
ТЕКСТ 2 198 729 115 200 40 4 28 115.0 21,0 4,0 73140,0 4,0 5,0 2,0 8,0 16,0
ТЗ 4 459 1408 187 378 96 2 58 223,0 4,0 2,0 190 265,0 16,0 12,0 4,0 16,0 38,0
Сочетание позиционной индексации и индексации на основе меток
Если вы хотите получить 0-й и 2-й элементы из индекса в столбце «A», вы можете сделать:
В [98]: dfd = pd.DataFrame ({'A': [1, 2, 3],
....: 'B': [4, 5, 6]},
....: index = список ('abc'))
....:
В [99]: dfd
Из [99]:
А Б
а 1 4
б 2 5
в 3 6
В [100]: dfd.loc [dfd.index [[0, 2]], 'A']
Из [100]:
а 1
c 3
Имя: A, dtype: int64
Это также можно выразить с помощью .iloc , явно получая местоположения в индексаторах и используя позиционная индексация для выбора вещей.
В [101]: dfd.iloc [[0, 2], dfd.columns.get_loc ('A')]
Из [101]:
а 1
c 3
Имя: A, dtype: int64
Для получения нескольких индексаторов с использованием .get_indexer :
В [102]: dfd.iloc [[0, 2], dfd.columns.get_indexer (['A', 'B'])] Из [102]: А Б а 1 4 в 3 6
Индексирование со списком с отсутствующими метками устарело
Предупреждение
Изменено в версии 1.0.0.
Использование .loc или [] со списком с одной или несколькими пропущенными метками больше не будет переиндексировать в пользу .reindex .
В предыдущих версиях при использовании .loc [list-of-label] работал бы до тех пор, пока было найдено не менее 1 ключей (в противном случае
вызовет KeyError ).Это поведение было изменено и теперь будет вызывать KeyError , если хотя бы одна метка отсутствует.
Рекомендуемая альтернатива - использовать .reindex () .
Например.
В [103]: s = pd.Series ([1, 2, 3]) В [104]: s Из [104]: 0 1 1 2 2 3 dtype: int64
Выбор со всеми найденными ключами не изменился.
В [105]: s.loc [[1, 2]] Из [105]: 1 2 2 3 dtype: int64
Предыдущее поведение
В [4]: s.loc [[1, 2, 3]] Из [4]: 1 2.0 2 3,0 3 NaN dtype: float64
Текущее поведение
В [4]: s.loc [[1, 2, 3]] Передача списков лайков в .loc с любыми несоответствующими элементами вызовет KeyError, в качестве альтернативы вы можете использовать .reindex (). Смотрите документацию здесь: https://pandas.pydata.org/pandas-docs/stable/indexing.html#deprecate-loc-reindex-listlike Из [4]: 1 2,0 2 3,0 3 NaN dtype: float64
Переиндексирование
Идиоматический способ добиться выбора потенциально ненайденных элементов - через .переиндекс () . См. Также раздел о переиндексации.
В [106]: s.reindex ([1, 2, 3]) Из [106]: 1 2,0 2 3,0 3 NaN dtype: float64
В качестве альтернативы, если вы хотите выбрать только действительных ключей , следующее будет идиоматическим и эффективным; гарантируется сохранение dtype выделения.
В [107]: label = [1, 2, 3] В [108]: s.loc [s.index.intersection (метки)] Из [108]: 1 2 2 3 dtype: int64
Наличие дублированного индекса повысит до .переиндекс () :
В [109]: s = pd.Series (np.arange (4), index = ['a', 'a', 'b', 'c']) В [110]: label = ['c', 'd']
В [17]: s.reindex (метки) ValueError: невозможно переиндексировать с повторяющейся оси
Как правило, желаемые метки можно пересекать с текущими оси, а затем переиндексировать.
В [111]: s.loc [s.index.intersection (метки)]. Reindex (метки) Из [111]: в 3,0 d NaN dtype: float64
Тем не менее, это будет все равно , если ваш результирующий индекс будет продублирован.
В [41]: labels = ['a', 'd'] В [42]: s.loc [s.index.intersection (метки)]. Reindex (метки) ValueError: невозможно переиндексировать с повторяющейся оси
Отбор случайных выборок
Случайный выбор строк или столбцов из Series или DataFrame с помощью метода sample () . По умолчанию метод отбирает строки и принимает определенное количество строк / столбцов для возврата или часть строк.
В [112]: s = pd.Series ([0, 1, 2, 3, 4, 5]) # Если аргументы не переданы, возвращается 1 строка.В [113]: s.sample () Из [113]: 4 4 dtype: int64 # Можно указать количество строк: В [114]: s.sample (n = 3) Из [114]: 0 0 4 4 1 1 dtype: int64 # Или часть строк: В [115]: s.sample (frac = 0,5) Из [115]: 5 5 3 3 1 1 dtype: int64
По умолчанию образец вернет каждую строку не более одного раза, но можно также выполнить выборку с заменой
при использовании замените вариант :
В [116]: s = pd.Series ([0, 1, 2, 3, 4, 5]) # Без замены (по умолчанию): В [117]: с.образец (n = 6, replace = False) Из [117]: 0 0 1 1 5 5 3 3 2 2 4 4 dtype: int64 # С заменой: В [118]: s.sample (n = 6, replace = True) Из [118]: 0 0 4 4 3 3 2 2 4 4 4 4 dtype: int64
По умолчанию каждая строка имеет равную вероятность быть выбранной, но если вы хотите, чтобы строки
чтобы иметь разные вероятности, вы можете передать веса выборки функции sample как весов . Эти веса могут быть списком, массивом NumPy или серией, но они должны быть той же длины, что и объект, который вы выбираете.Отсутствующие значения будут рассматриваться как нулевой вес, а значения inf не допускаются. Если суммы весов не равны 1, они будут повторно нормализованы путем деления всех весов на сумму весов. Например:
В [119]: s = pd.Series ([0, 1, 2, 3, 4, 5]) В [120]: example_weights = [0, 0, 0,2, 0,2, 0,2, 0,4] В [121]: s.sample (n = 3, weights = example_weights) Из [121]: 5 5 4 4 3 3 dtype: int64 # Вес будет повторно нормализован автоматически В [122]: example_weights2 = [0,5, 0, 0, 0, 0, 0] В [123]: с.образец (n = 1, weights = example_weights2) Из [123]: 0 0 dtype: int64
При применении к DataFrame вы можете использовать столбец DataFrame в качестве весов выборки. (при условии, что вы выбираете строки, а не столбцы), просто передавая имя столбца в виде строки.
В [124]: df2 = pd.DataFrame ({'col1': [9, 8, 7, 6],
.....: 'weight_column': [0.5, 0.4, 0.1, 0]})
.....:
В [125]: df2.sample (n = 3, weights = 'weight_column')
Из [125]:
col1 weight_column
1 8 0.4
0 9 0,5
2 7 0,1
образец также позволяет пользователям выбирать столбцы вместо строк с использованием аргумента оси .
В [126]: df3 = pd.DataFrame ({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
В [127]: df3.sample (n = 1, axis = 1)
Из [127]:
col1
0 1
1 2
2 3
Наконец, можно также установить начальное число для генератора случайных чисел sample , используя аргумент random_state , который будет принимать либо целое число (как начальное значение), либо объект NumPy RandomState.
В [128]: df4 = pd.DataFrame ({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
# С заданным семенем образец всегда будет рисовать одни и те же строки.
В [129]: df4.sample (n = 2, random_state = 2)
Из [129]:
col1 col2
2 3 4
1 2 3
В [130]: df4.sample (n = 2, random_state = 2)
Из [130]:
col1 col2
2 3 4
1 2 3
Настройка с увеличением
Операции .loc / [] могут выполнять увеличение при установке несуществующего ключа для этой оси.
В случае Series это фактически операция добавления.
В [131]: se = pd.Series ([1, 2, 3]) В [132]: se Из [132]: 0 1 1 2 2 3 dtype: int64 В [133]: se [5] = 5. В [134]: se Из [134]: 0 1.0 1 2,0 2 3,0 5 5,0 dtype: float64
DataFrame может быть увеличен по любой оси через .loc .
В [135]: dfi = pd.DataFrame (np.arange (6) .reshape (3, 2), .....: columns = ['A', 'B']) .....: В [136]: dfi Из [136]: А Б 0 0 1 1 2 3 2 4 5 В [137]: dfi.loc [:, 'C'] = dfi.loc [:, 'A'] В [138]: dfi Из [138]: А Б В 0 0 1 0 1 2 3 2 2 4 5 4
Это похоже на операцию добавления к DataFrame .
В [139]: dfi.loc [3] = 5 В [140]: dfi Из [140]: А Б В 0 0 1 0 1 2 3 2 2 4 5 4 3 5 5 5
Быстрое получение и установка скалярного значения
Поскольку индексация с помощью [] должна обрабатывать множество случаев (доступ по одной метке,
нарезка, логическое индексирование и т. д.), у него есть немного накладных расходов, чтобы вычислить
из того, что вы просите. Если вы хотите получить доступ только к скалярному значению,
Самый быстрый способ - использовать методы на и iat , которые реализованы на
все структуры данных.
Аналогично loc , на обеспечивает скалярный поиск на основе метки , а iat обеспечивает поиск на основе целых чисел аналогично iloc
В [141]: s.iat [5] Вых [141]: 5 В [142]: df.в [даты [5], 'A'] Из [142]: -0.6736897080883706 В [143]: df.iat [3, 0] Из [143]: 0,7215551622443669
Можно также установить с помощью этих же индексаторов.
В [144]: df.at [date [5], 'E'] = 7 В [145]: df.iat [3, 0] = 7
на может увеличить объект на месте, как указано выше, если индексатор отсутствует.
В [146]: df.at [date [-1] + pd.Timedelta ('1 day'), 0] = 7
В [147]: df
Из [147]:
А Б В Г Д Е 0
2000-01-01 0.469112 -0,282863 -1,509059 -1,135632 NaN NaN
2000-01-02 1,212112 -0,173215 0,119209 -1,044236 NaN NaN
2000-01-03 -0,861849 -2,104569 -0,494929 1,071804 NaN NaN
2000-01-04 7,000000 -0,706771 -1,039575 0,271860 NaN NaN
2000-01-05 -0,424972 0,567020 0,276232 -1,087401 NaN NaN
2000-01-06 -0,673690 0,113648 -1,478427 0,524988 7,0 NaN
2000-01-07 0,404705 0,577046 -1,715002 -1,039268 NaN NaN
2000-01-08 -0,370647 -1,157892 -1,344312 0,844885 NaN NaN
9 января 2000 г. NaN NaN NaN NaN NaN 7.0
Булево индексирование
Другой распространенной операцией является использование логических векторов для фильтрации данных.
Операторы: | для или , и для и и ~ для , а не .
Эти должны быть сгруппированы с помощью круглых скобок , поскольку по умолчанию Python будет
оценить такое выражение, как df ['A']> 2 & df ['B'] <3 как df ['A']> (2 & df ['B']) <3 , а желаемый порядок оценки - (df ['A']> 2) & (df ['B'] <3) .
Использование логического вектора для индексации серии работает точно так же, как в NumPy ndarray:
В [148]: s = pd.Series (range (-3, 4)) В [149]: s Из [149]: 0–3 1-2 2-1 3 0 4 1 5 2 6 3 dtype: int64 В [150]: s [s> 0] Из [150]: 4 1 5 2 6 3 dtype: int64 В [151]: s [(s <-1) | (s> 0,5)] Из [151]: 0–3 1-2 4 1 5 2 6 3 dtype: int64 В [152]: s [~ (s <0)] Из [152]: 3 0 4 1 5 2 6 3 dtype: int64
Вы можете выбирать строки из DataFrame, используя логический вектор той же длины, что и индекс DataFrame (например, что-то производное от одного из столбцов DataFrame):
В [153]: df [df ['A']> 0]
Из [153]:
А Б В Г Д Е 0
2000-01-01 0.469112 -0,282863 -1,509059 -1,135632 NaN NaN
2000-01-02 1,212112 -0,173215 0,119209 -1,044236 NaN NaN
2000-01-04 7,000000 -0,706771 -1,039575 0,271860 NaN NaN
2000-01-07 0,404705 0,577046 -1,715002 -1,039268 NaN NaN
Понимание списков и метод map Series также можно использовать для создания
более сложные критерии:
В [154]: df2 = pd.DataFrame ({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'],
.....: 'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'],
.....: 'c': np.random.randn (7)})
.....:
# нужно только два или три
В [155]: критерий = df2 ['a']. Map (lambda x: x.startswith ('t'))
В [156]: df2 [критерий]
Из [156]:
а б в
2 два года 0,041290
3 три x 0,361719
4 два года -0,238075
# эквивалентно, но медленнее
В [157]: df2 [[x.startswith ('t') для x в df2 ['a']]]
Из [157]:
а б в
2 два года 0,041290
3 три x 0,361719
4 два года -0,238075
# Несколько критериев
В [158]: df2 [критерий & (df2 ['b'] == 'x')]
Из [158]:
а б в
3 три x 0.361719
С методами выбора Выбор по метке, Выбор по позиции, и Advanced Indexing, вы можете выбрать более чем по одной оси, используя логические векторы в сочетании с другими выражениями индексации.
В [159]: df2.loc [критерий & (df2 ['b'] == 'x'), 'b': 'c'] Из [159]: до н.э 3 х 0,361719
Предупреждение
iloc поддерживает два вида логической индексации. Если индексатор является логическим Series ,
возникнет ошибка.Например, в следующем примере df.iloc [s.values, 1] подходит.
Логический индексатор - это массив. Но df.iloc [s, 1] вызовет ValueError .
В [160]: df = pd.DataFrame ([[1, 2], [3, 4], [5, 6]],
.....: index = list ('abc'),
.....: columns = ['A', 'B'])
.....:
В [161]: s = (df ['A']> 2)
В [162]: s
Из [162]:
Ложь
б Верно
c Верно
Имя: A, dtype: bool
В [163]: df.loc [s, 'B']
Из [163]:
б 4
с 6
Имя: B, dtype: int64
В [164]: df.iloc [s.values, 1]
Из [164]:
б 4
с 6
Имя: B, dtype: int64
Индексирование с помощью isin
Рассмотрим метод isin () из Series , который возвращает логическое значение
вектор, который является истинным везде, где в переданном списке присутствуют элементы серии .
Это позволяет вам выбирать строки, в которых один или несколько столбцов имеют нужные вам значения:
В [165]: s = pd.Series (np.arange (5), index = np.arange (5) [:: - 1], dtype = 'int64') В [166]: s Из [166]: 4 0 3 1 2 2 1 3 0 4 dtype: int64 В [167]: с.isin ([2, 4, 6]) Из [167]: 4 ложь 3 ложь 2 Верно 1 ложь 0 Верно dtype: bool В [168]: s [s.isin ([2, 4, 6])] Из [168]: 2 2 0 4 dtype: int64
Тот же метод доступен для объектов Index и полезен для случаев
когда вы не знаете, какой из искомых ярлыков присутствует на самом деле:
В [169]: s [s.index.isin ([2, 4, 6])] Из [169]: 4 0 2 2 dtype: int64 # сравните это со следующим В [170]: s.reindex ([2, 4, 6]) Из [170]: 2 2.0 4 0,0 6 NaN dtype: float64
Кроме того, MultiIndex позволяет выбрать отдельный уровень для использования
в проверке членства:
В [171]: s_mi = pd.Series (np.arange (6), .....: index = pd.MultiIndex.from_product ([[0, 1], ['a', 'b', 'c']])) .....: В [172]: s_mi Из [172]: 0 а 0 б 1 с 2 1 а 3 б 4 в 5 dtype: int64 В [173]: s_mi.iloc [s_mi.index.isin ([(1, 'a'), (2, 'b'), (0, 'c')])] Из [173]: 0 с 2 1 а 3 dtype: int64 В [174]: s_mi.iloc [s_mi.index.isin (['a', 'c', 'e'], level = 1)] Из [174]: 0 а 0 с 2 1 а 3 в 5 dtype: int64
DataFrame также имеет метод isin () . При вызове - это , передайте набор
значения в виде массива или dict. Если значения являются массивом, isin возвращает
DataFrame логических значений, имеющий ту же форму, что и исходный DataFrame, с True
где бы ни находился элемент в последовательности значений.
В [175]: df = pd.DataFrame ({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'],
.....: 'ids2': ['a', 'n', 'c', 'n']})
.....:
В [176]: values = ['a', 'b', 1, 3]
В [177]: df.isin (значения)
Из [177]:
vals ids ids2
0 правда правда правда
1 Неверно Верно Неверно
2 Верно Неверно Неверно
3 Ложь Ложь Ложь
Часто бывает необходимо сопоставить определенные значения с определенными столбцами.
Просто сделайте значения dict , где ключом является столбец, а значение
список элементов, которые вы хотите проверить.
В [178]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
В [179]: df.isin (значения)
Из [179]:
vals ids ids2
0 Верно Верно Неверно
1 Неверно Верно Неверно
2 Верно Неверно Неверно
3 Ложь Ложь Ложь
Объедините isin DataFrame с методами any () и all () , чтобы
быстро выбрать подмножества ваших данных, которые соответствуют заданным критериям.
Чтобы выбрать строку, в которой каждый столбец соответствует своему критерию:
В [180]: values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]}
В [181]: row_mask = df.isin (значения).все (1)
В [182]: df [row_mask]
Из [182]:
vals ids ids2
0 1 а а
The
where () Метод и маскирование Выбор значений из серии с логическим вектором обычно возвращает
подмножество данных. Чтобы гарантировать, что результат выбора имеет ту же форму, что и
Исходные данные, вы можете использовать метод where в Series и DataFrame .
Чтобы вернуть только выбранные строки:
В [183]: s [s> 0] Из [183]: 3 1 2 2 1 3 0 4 dtype: int64
Чтобы вернуть серию той же формы, что и исходная:
В [184]: с.где (s> 0) Из [184]: 4 NaN 3 1.0 2 2,0 1 3,0 0 4,0 dtype: float64
Выбор значений из DataFrame с логическим критерием теперь также сохраняет
форма входных данных. , где используется под капотом в качестве реализации.
Приведенный ниже код эквивалентен df.where (df <0) .
В [185]: df [df <0]
Из [185]:
А Б В Г
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0,352480 NaN -1.1 NaN
2000-01-03 -0,864883 NaN -0,227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2,670153 -0,114722 NaN -0,048048
2000-01-08 NaN NaN -0.048788 -0.808838
Кроме того, , где принимает необязательный другой аргумент для замены
значения, для которых условие равно False, в возвращенной копии.
В [186]: df.где (df <0, -df)
Из [186]:
А Б В Г
2000-01-01 -2.104139 -1.309525 -0.485855 -0.245166
2000-01-02 -0,352480 -0,3 -1,1 -1,655824
2000-01-03 -0,864883 -0,299674 -0,227870 -0,281059
2000-01-04 -0,846958 -1,222082 -0,600705 -1,233203
2000-01-05 -0,669692 -0.605656 -1,169184 -0,342416
2000-01-06 -0,868584 -0,948458 -2,297780 -0,684718
2000-01-07 -2,670153 -0,114722 -0,168904 -0,048048
2000-01-08 -0,801196 -1,3
-0,048788 -0,808838
Вы можете установить значения на основе некоторых логических критериев.Интуитивно это можно сделать так:
В [187]: s2 = s.copy ()
В [188]: s2 [s2 <0] = 0
В [189]: s2
Из [189]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
В [190]: df2 = df.copy ()
В [191]: df2 [df2 <0] = 0
В [192]: df2
Из [192]:
А Б В Г
2000-01-01 0,000000 0,000000 0,485855 0,245166
2000-01-02 0,000000 0,3 0,000000 1,655824
2000-01-03 0,000000 0,299674 0,000000 0,281059
2000-01-04 0,846958 0,000000 0.600705 0,000000
2000-01-05 0,669692 0,000000 0,000000 0,342416
2000-01-06 0,868584 0,000000 2,297780 0,000000
2000-01-07 0,000000 0,000000 0,168904 0,000000
2000-01-08 0.801196 1.3 0.000000 0.000000
По умолчанию , где возвращает измененную копию данных. Существует
необязательный параметр вместо , чтобы можно было изменить исходные данные
без создания копии:
В [193]: df_orig = df.copy ()
В [194]: df_orig.where (df> 0, -df, inplace = True)
В [195]: df_orig
Из [195]:
А Б В Г
2000-01-01 2.104139 1,309525 0,485855 0,245166
2000-01-02 0,352480 0,3 1,1 1,655824
2000-01-03 0,864883 0,299674 0,227870 0,281059
2000-01-04 0,846958 1,222082 0,600705 1,233203
2000-01-05 0,669692 0,605656 1,169184 0,342416
2000-01-06 0,868584 0,948458 2,297780 0,684718
2000-01-07 2,670153 0,114722 0,168904 0,048048
2000-01-08 0,801196 1,3
0,048788 0,808838
Примечание
Подпись для DataFrame.where () отличается от numpy.где () .
Примерно df1. где (m, df2) эквивалентно np., где (m, df1, df2) .
В [196]: df.where (df <0, -df) == np.where (df <0, df, -df)
Из [196]:
А Б В Г
01.01.2000 Правда Правда Правда Правда
2000-01-02 Правда Правда Правда Правда
2000-01-03 Правда Правда Правда Правда
2004-01-04 Правда Правда Правда Правда
05.01.2000 Правда Правда Правда Правда
2000-01-06 Правда Правда Правда Правда
07.01.2000 True True True True
2008-01-08 Правда Правда Правда Правда
Выравнивание
Кроме того, , где выравнивает входное логическое условие (ndarray или DataFrame),
такой, что возможен частичный выбор с настройкой.Это аналогично
частичная установка через .loc (но по содержимому, а не по меткам осей).
В [197]: df2 = df.copy ()
В [198]: df2 [df2 [1: 4]> 0] = 3
В [199]: df2
Из [199]:
А Б В Г
2000-01-01 -2.104139 -1.309525 0.485855 0.245166
2000-01-02 -0.352480 3.000000 -1.1 3.000000
2000-01-03 -0,864883 3,000000 -0,227870 3,000000
2000-01-04 3.000000 -1.222082 3.000000 -1.233203
2000-01-05 0,669692 -0,605656-1.169184 0,342416
2000-01-06 0,868584 -0,948458 2,297780 -0,684718
2000-01-07 -2,670153 -0,114722 0,168904 -0,048048
2000-01-08 0.801196 1.3
-0.048788 -0.808838
Где также может принимать параметры оси и уровня для выравнивания ввода, когда
выполняя , где .
В [200]: df2 = df.copy ()
В [201]: df2.where (df2> 0, df2 ['A'], axis = 'index')
Из [201]:
А Б В Г
2000-01-01 -2.104139 -2.104139 0,485855 0,245166
2000-01-02 -0,352480 0,3 -0,352480 1,655824
2000-01-03 -0,864883 0,299674 -0,864883 0,281059
2000-01-04 0,846958 0,846958 0,600705 0,846958
2000-01-05 0,669692 0,669692 0,669692 0,342416
2000-01-06 0,868584 0,868584 2,297780 0,868584
2000-01-07 -2,670153 -2,670153 0,168904 -2,670153
2000-01-08 0.801196 1.3 0.801196 0.801196
Это эквивалентно (но быстрее) следующему.
В [202]: df2 = df.copy ()
В [203]: df.применить (лямбда x, y: x.where (x> 0, y), y = df ['A'])
Из [203]:
А Б В Г
2000-01-01 -2.104139 -2.104139 0,485855 0,245166
2000-01-02 -0,352480 0,3 -0,352480 1,655824
2000-01-03 -0,864883 0,299674 -0,864883 0,281059
2000-01-04 0,846958 0,846958 0,600705 0,846958
2000-01-05 0,669692 0,669692 0,669692 0,342416
2000-01-06 0,868584 0,868584 2,297780 0,868584
2000-01-07 -2,670153 -2,670153 0,168904 -2,670153
2000-01-08 0.801196 1.3 0.801196 0.801196
, где может принимать вызываемый объект как условие и другие аргументы . Функция должна
быть с одним аргументом (вызывающий Series или DataFrame), который возвращает действительный вывод
как условие и другой аргумент .
В [204]: df3 = pd.DataFrame ({'A': [1, 2, 3],
.....: 'B': [4, 5, 6],
.....: 'C': [7, 8, 9]})
.....:
В [205]: df3.where (лямбда x: x> 4, лямбда x: x + 10)
Из [205]:
А Б В
0 11 14 7
1 12 5 8
2 13 6 9
Маска
mask () - это обратная логическая операция для , где .
В [206]: s.mask (s> = 0)
Из [206]:
4 NaN
3 NaN
2 NaN
1 NaN
0 NaN
dtype: float64
В [207]: df.mask (df> = 0)
Из [207]:
А Б В Г
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0,352480 NaN -1,1 NaN
2000-01-03 -0,864883 NaN -0,227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2,670153 -0,114722 NaN -0,048048
2000-01-08 NaN NaN -0.048788 -0.808838
Настройка с условным увеличением с использованием
numpy () Альтернатива where () - использовать numpy.where () .
В сочетании с настройкой нового столбца вы можете использовать его для увеличения DataFrame, в котором
значения определены условно.
Предположим, у вас есть два варианта выбора в следующем фрейме данных. И ты хочешь установите цвет нового столбца на «зеленый», когда второй столбец имеет «Z».Вы можете сделать следующее:
В [208]: df = pd.DataFrame ({'col1': список ('ABBC'), 'col2': список ('ZZXY')})
В [209]: df ['color'] = np.where (df ['col2'] == 'Z', 'green', 'red').
В [210]: df
Из [210]:
col1 col2 цвет
0 A Z зеленый
1 B Z зеленый
2 B X красный
3 C Y красный
Если у вас несколько условий, вы можете использовать numpy.select () для этого. Сказать
соответствует трем условиям, есть три варианта выбора цвета, с четвертым цветом
в качестве запасного варианта вы можете сделать следующее.
В [211]: conditions = [ .....: (df ['col2'] == 'Z') & (df ['col1'] == 'A'), .....: (df ['col2'] == 'Z') & (df ['col1'] == 'B'), .....: (df ['col1'] == 'B') .....:] .....: В [212]: choices = ['желтый', 'синий', 'фиолетовый'] В [213]: df ['color'] = np.select (условия, варианты, по умолчанию = 'черный') В [214]: df Из [214]: col1 col2 цвет 0 A Z желтый 1 B Z синий 2 B X фиолетовый 3 C Y черный
Объекты DataFrame имеют query () метод, позволяющий выбирать с помощью выражения.
Вы можете получить значение кадра, в котором столбец b имеет значения
между значениями столбцов a и c . Например:
В [215]: n = 10
В [216]: df = pd.DataFrame (np.random.rand (n, 3), columns = list ('abc'))
В [217]: df
Из [217]:
а б в
0 0,438921 0,118680 0,863670
1 0,138138 0,577363 0,686602
2 0,595307 0,564592 0,520630
3 0,2 0,5 0,616184
4 0,078718 0,854477 0,898725
5 0,076404 0.523211 0,5
6 0,7 0,216974 0,564056
7 0,397890 0,454131 0,6
8 0,074315 0,437913 0,019794
9 0,559209 0,502065 0,026437
# чистый питон
В [218]: df [(df ['a']
7 0,397890 0,454131 0,6
# запрос
В [219]: df.query ('(a
7 0,397890 0,454131 0,6
Сделайте то же самое, но вернитесь к именованному индексу, если нет столбца
с именем .
В [220]: df = pd.DataFrame (np.random.randint (n / 2, size = (n, 2)), columns = list ('bc'))
В [221]: df.index.name = 'a'
В [222]: df
Из [222]:
до н.э
а
0 0 4
1 0 1
2 3 4
3 4 3
4 1 4
5 0 3
6 0 1
7 3 4
8 2 3
9 1 1
В [223]: df.запрос ('a Если вместо этого вы не хотите или не можете давать название своему индексу, вы можете использовать имя индекс в выражении вашего запроса:
В [224]: df = pd.DataFrame (np.random.randint (n, size = (n, 2)), columns = list ('bc'))
В [225]: df
Из [225]:
до н.э
0 3 1
1 3 0
2 5 6
3 5 2
4 7 4
5 0 1
6 2 5
7 0 1
8 6 0
9 7 9
В [226]: df.query ('index Примечание
Если имя вашего индекса перекрывается с именем столбца, имя столбца будет
учитывая приоритет.Например,
В [227]: df = pd.DataFrame ({'a': np.random.randint (5, size = 5)})
В [228]: df.index.name = 'a'
В [229]: df.query ('a> 2') # использует столбец 'a', а не индекс
Из [229]:
а
а
1 3
3 3
Вы по-прежнему можете использовать индекс в выражении запроса, используя специальный
идентификатор "index":
В [230]: df.query ('index> 2')
Из [230]:
а
а
3 3
4 2
Если по какой-то причине у вас есть столбец с именем index , вы можете обратиться к
индекс как ilevel_0 , но на этом этапе вы должны рассмотреть
переименование столбцов в менее неоднозначное.
MultiIndex query () Синтаксис Вы также можете использовать уровни DataFrame с MultiIndex , как если бы они были столбцами в кадре:
В [231]: n = 10
В [232]: colors = np.random.choice (['красный', 'зеленый'], size = n)
В [233]: foods = np.random.choice (['яйца', 'ветчина'], размер = n)
В [234]: цвета
Из [234]:
array (['красный', 'красный', 'красный', 'зеленый', 'зеленый', 'зеленый', 'зеленый', 'зеленый',
'зеленый', 'зеленый'], dtype = ' Если уровни MultiIndex не имеют названия, вы можете ссылаться на них, используя
специальные имена:
В [240]: df.index.names = [None, None]
В [241]: df
Из [241]:
0 1
красный окорок 0,194889 -0,381994
ветчина 0,318587 2.089075
яйца -0,728293 -0,0 Условное обозначение - ilevel_0 , что означает «индексный уровень 0» для 0-го уровня.
индекса .
query () Примеры использования Пример использования query () - это когда у вас есть коллекция DataFrame объектов, которые имеют подмножество имен столбцов (или индекс
уровни / имена) вместе. Вы можете передать один и тот же запрос обоим кадрам без необходимо указать, какой фрейм вы хотите запрашивать
В [243]: df = pd.DataFrame (np.random.rand (n, 3), columns = list ('abc'))
В [244]: df
Из [244]:
а б в
0 0.224283 0,736107 0,139168
1 0,302827 0,657803 0,713897
2 0,611185 0,136624 0,984960
3 0,195246 0,123436 0,627712
4 0,618673 0,371660 0,047902
5 0,480088 0,062993 0,185760
6 0,568018 0,483467 0,445289
7 0,309040 0,274580 0,587101
8 0,258993 0,477769 0,370255
9 0,550459 0,840870 0,304611
В [245]: df2 = pd.DataFrame (np.random.rand (n + 2, 3), columns = df.columns)
В [246]: df2
Из [246]:
а б в
0 0,357579 0,229800 0,596001
1 0,309059 0,957923 0.965663
2 0,123102 0,336914 0,318616
3 0,526506 0,323321 0,860813
4 0,518736 0,486514 0,384724
5 0,16 0,732716
В [247]: expr = '0,0 <= a <= c <= 0,5'
В [248]: карта (лямбда-кадр: frame.query (expr), [df, df2])
Выход [248]: <карта на 0x7f42bfbd5490>
query () Сравнение синтаксиса Python и pandas Полный синтаксис, похожий на numpy:
В [249]: df = pd.DataFrame (np.random.randint (n, размер = (n, 3)), columns = list ('abc'))
В [250]: df
Из [250]:
а б в
0 7 8 9
1 1 0 7
2 2 7 2
3 6 2 2
4 2 6 3
5 3 8 2
6 1 7 2
7 5 1 5
8 9 8 0
9 1 5 0
В [251]: df.query ('(a Немного лучше, убрав круглые скобки (операторы сравнения связывают жестче
чем , и | ):
В [253]: df.запрос ('a Используйте английский вместо символов:
В [254]: df.query ('a Довольно близко к тому, как это можно было бы написать на бумаге:
В [255]: df.query ('a в и нет в операторов query () также поддерживает специальное использование Python в и отсутствует в операторах сравнения , обеспечивая краткий синтаксис для вызова - это метод из
серии или DataFrame . # получить все строки, в которых столбцы "a" и "b" имеют перекрывающиеся значения
В [256]: df = pd.DataFrame ({'a': list ('aabbccddeeff'), 'b': list ('aaaabbbbcccc'),
.....: 'c': np.random.randint (5, size = 12),
.....: 'd': np.random.randint (9, size = 12)})
.....:
В [257]: df
Из [257]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
6 д б 3 3
7 д б 2 1
8 д в 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
В [258]: df.запрос ('а в б')
Из [258]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
# Как бы вы это сделали на чистом Python
В [259]: df [df ['a']. Isin (df ['b'])]
Из [259]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
В [260]: df.query ('a not in b')
Из [260]:
а б в г
6 д б 3 3
7 д б 2 1
8 д в 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
# чистый Python
В [261]: df [~ df ['a']. Isin (df ['b'])]
Из [261]:
а б в г
6 д б 3 3
7 д б 2 1
8 д в 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
Вы можете комбинировать это с другими выражениями для очень сжатых запросов:
# строки, в которых столбцы a и b имеют перекрывающиеся значения
# и значения столбца c меньше, чем значения столбца d
В [262]: df.запрос ('a in b и c Примечание
Обратите внимание, что в и не в оцениваются в Python, поскольку numexpr не имеет эквивалента этой операции.Однако только в / не в Само выражение вычисляется в ванильном Python. Например, в
выражение
df.query ('a в b + c + d')
(b + c + d) оценивается numexpr и , затем в операция оценивается на простом Python. В общем, любые операции, которые могут
будет оцениваться с использованием numexpr будет.
Специальное использование оператора
== со списком объектов Сравнение списка значений со столбцом с использованием == /! = работает аналогично
на в / не в .
В [264]: df.query ('b == ["a", "b", "c"]')
Из [264]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
6 д б 3 3
7 д б 2 1
8 д в 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
# чистый Python
В [265]: df [df ['b']. Isin ([«a», «b», «c»])]
Из [265]:
а б в г
0 а а 2 6
1 а а 4 7
2 б а 1 6
3 б а 2 1
4 в б 3 6
5 в б 0 2
6 д б 3 3
7 д б 2 1
8 д в 4 3
9 д в 2 0
10 ж в 0 6
11 f c 1 2
В [266]: df.запрос ('c == [1, 2]')
Из [266]:
а б в г
0 а а 2 6
2 б а 1 6
3 б а 2 1
7 д б 2 1
9 д в 2 0
11 f c 1 2
В [267]: df.query ('c! = [1, 2]')
Из [267]:
а б в г
1 а а 4 7
4 в б 3 6
5 в б 0 2
6 д б 3 3
8 д в 4 3
10 ж в 0 6
# использование в / не в
В [268]: df.query ('[1, 2] in c')
Из [268]:
а б в г
0 а а 2 6
2 б а 1 6
3 б а 2 1
7 д б 2 1
9 д в 2 0
11 f c 1 2
В [269]: df.query ('[1, 2] не в c')
Из [269]:
а б в г
1 а а 4 7
4 в б 3 6
5 в б 0 2
6 д б 3 3
8 д в 4 3
10 ж в 0 6
# чистый Python
В [270]: df [df ['c'].isin ([1, 2])]
Из [270]:
а б в г
0 а а 2 6
2 б а 1 6
3 б а 2 1
7 д б 2 1
9 д в 2 0
11 f c 1 2
Логические операторы
Вы можете инвертировать логические выражения с помощью слова , а не или оператора ~ .
В [271]: df = pd.DataFrame (np.random.rand (n, 3), columns = list ('abc'))
В [272]: df ['bools'] = np.random.rand (len (df))> 0,5
В [273]: df.query ('~ bools')
Из [273]:
a b c bools
2 0.697753 0,212799 0,329209 Ложь
7 0,275396 0,6Конечно, выражения могут быть сколь угодно сложными:
# короткий синтаксис запроса
В [276]: shorter = df.query ('a 2')
# эквивалент в чистом Python
В [277]: long = df [(df ['a'] 2)]
.....:
В [278]: короче
Из [278]:
a b c bools
7 0,275396 0,6 0,826619 Ложь
В [279]: длиннее
Из [279]:
a b c bools
7 0,275396 0,6 0,826619 Ложь
В [280]: короче == длиннее
Из [280]:
a b c bools
7 Правда Правда Правда Правда
Выполнение запроса
() DataFrame.query () с использованием numexpr немного быстрее, чем Python для
большие рамки.
Примечание
Вы увидите только преимущества в производительности при использовании движка numexpr с DataFrame.query () , если в вашем фрейме больше примерно 200 000
ряды.
Этот график был создан с использованием DataFrame с 3 столбцами, каждый из которых содержит
значения с плавающей запятой, сгенерированные с использованием numpy.random.randn () .
Дубликаты данных
Если вы хотите идентифицировать и удалять повторяющиеся строки в DataFrame, есть
два метода, которые помогут: duplicates и drop_duplicates .Каждый
принимает в качестве аргумента столбцы, используемые для идентификации повторяющихся строк.
duplicatedвозвращает логический вектор, длина которого равна количеству строк и указывает, дублируется ли строка.drop_duplicatesудаляет повторяющиеся строки.
По умолчанию первая наблюдаемая строка повторяющегося набора считается уникальной, но
у каждого метода есть параметр keep , чтобы указать целевые объекты, которые необходимо сохранить.
keep = 'first'(по умолчанию): отметить / удалить дубликаты, кроме первого вхождения.keep = 'last': отметить / удалить дубликаты, кроме последнего вхождения.keep = False: отметить / удалить все дубликаты.
В [281]: df2 = pd.DataFrame ({'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'],
.....: 'b': ['x', 'y', 'x', 'y', 'x', 'x', 'x'],
.....: 'c': np.random.randn (7)})
.....:
В [282]: df2
Из [282]:
а б в
0 один x -1.067137
1 один год 0,309500
2 два x -0,21 · 1056
3 два года -1.842023
4 два х -0,3
5 три x -1.964475
6 четыре x 1,298329
В [283]: df2.duplicated ('a')
Из [283]:
0 ложь
1 Верно
2 ложь
3 Верно
4 Верно
5 Неверно
6 ложь
dtype: bool
В [284]: df2.duplicated ('a', keep = 'last')
Из [284]:
0 Верно
1 ложь
2 Верно
3 Верно
4 ложь
5 Неверно
6 ложь
dtype: bool
В [285]: df2.дублированный ('a', keep = False)
Из [285]:
0 Верно
1 Верно
2 Верно
3 Верно
4 Верно
5 Неверно
6 ложь
dtype: bool
В [286]: df2.drop_duplicates ('a')
Из [286]:
а б в
0 один x -1.067137
2 два x -0,21 · 1056
5 три x -1.964475
6 четыре x 1,298329
В [287]: df2.drop_duplicates ('a', keep = 'last')
Из [287]:
а б в
1 один год 0,309500
4 два х -0,3
5 три x -1.964475
6 четыре x 1,298329
В [288]: df2.drop_duplicates ('a', keep = False)
Из [288]:
а б в
5 три х -1.964475
6 четыре x 1,298329
Также вы можете передать список столбцов для выявления дубликатов.
В [289]: df2.duplicated (['a', 'b'])
Из [289]:
0 ложь
1 ложь
2 ложь
3 ложь
4 Верно
5 Неверно
6 ложь
dtype: bool
В [290]: df2.drop_duplicates (['a', 'b'])
Из [290]:
а б в
0 один x -1.067137
1 один год 0,309500
2 два x -0,21 · 1056
3 два года -1.842023
5 три x -1.964475
6 четыре x 1,298329
Чтобы удалить дубликаты по значению индекса, используйте индекс .продублируйте , затем выполните нарезку.
Тот же набор опций доступен для параметра keep .
В [291]: df3 = pd.DataFrame ({'a': np.arange (6),
.....: 'b': np.random.randn (6)},
.....: index = ['a', 'a', 'b', 'c', 'b', 'a'])
.....:
В [292]: df3
Из [292]:
а б
а 0 1,440455
а 1 2.456086
б 2 1.038402
в 3 -0,894409
б 4 0,683536
а 5 3,082764
В [293]: df3.index.duplicated ()
Выход [293]: массив ([Ложь, Истина, Ложь, Ложь, Истина, Истина])
В [294]: df3 [~ df3.index.duplicated ()]
Из [294]:
а б
а 0 1,440455
б 2 1.038402
в 3 -0,894409
В [295]: df3 [~ df3.index.duplicated (keep = 'last')]
Из [295]:
а б
в 3 -0,894409
б 4 0,683536
а 5 3,082764
В [296]: df3 [~ df3.index.duplicated (keep = False)]
Из [296]:
а б
в 3 -0,894409
Словарный
get () метод Каждый из Series или DataFrame имеет метод get , который может возвращать
значение по умолчанию.
В [297]: s = pd.Серии ([1, 2, 3], index = ['a', 'b', 'c'])
В [298]: s.get ('a') # эквивалентно s ['a']
Вых [298]: 1
В [299]: s.get ('x', по умолчанию = -1)
Вых [299]: -1
Поиск значений по индексам / меткам столбцов
Иногда требуется извлечь набор значений из последовательности меток строк.
и метки столбцов, это может быть достигнуто с помощью pandas.factorize и индексации NumPy.
Например:
В [300]: df = pd.DataFrame ({'col': ["A", "A", "B", "B"],
.....: 'A': [80, 23, np.нан, 22],
.....: 'B': [80, 55, 76, 67]})
.....:
В [301]: df
Из [301]:
столбец A B
0 А 80,0 80
1 А 23,0 55
2 Б NaN 76
3 В 22.0 67
В [302]: idx, cols = pd.factorize (df ['col'])
В [303]: df.reindex (cols, axis = 1) .to_numpy () [np.arange (len (df)), idx]
Out [303]: array ([80., 23., 76., 67.])
Ранее этого можно было достичь с помощью специального метода DataFrame.lookup который устарел в версии 1.2.0.
Индексные объекты
Класс pandas Index и его подклассы можно рассматривать как
реализация заказанного мультимножества .Дубликаты разрешены. Однако, если вы попробуете
для преобразования объекта Index с повторяющимися записями в установите , будет возбуждено исключение.
Index также обеспечивает инфраструктуру, необходимую для
поиск, выравнивание данных и переиндексация. Самый простой способ создать Индекс напрямую должен передать список или другую последовательность в Индекс :
В [304]: index = pd.Index (['e', 'd', 'a', 'b']) В [305]: индекс Out [305]: индекс (['e', 'd', 'a', 'b'], dtype = 'object') В [306]: 'd' в индексе Out [306]: Верно
Вы также можете передать имя , которое будет сохранено в индексе:
В [307]: index = pd.Индекс (['e', 'd', 'a', 'b'], name = 'something') В [308]: index.name Out [308]: 'что-то'
Имя, если оно задано, будет отображаться на дисплее консоли:
В [309]: index = pd.Index (list (range (5)), name = 'rows') В [310]: columns = pd.Index (['A', 'B', 'C'], name = 'cols') В [311]: df = pd.DataFrame (np.random.randn (5, 3), index = index, columns = columns) В [312]: df Из [312]: столбцы A B C ряды 0 1,295989 -1,051694 1,340429 1-2.366110 0,428241 0,387275 2 0,433306 0,8 0,278094 3 2,154730 -0,315628 0,264223 4 1,126818 1,132290 -0,353310 В [313]: df ['A'] Из [313]: ряды 0 1,295989 1 -2,366110 2 0,433306 3 2,154730 4 1,126818 Имя: A, dtype: float64
Установка метаданных
Индексы «в основном неизменяемы», но их можно устанавливать и изменять. имя атрибута. Вы можете использовать переименовать , set_names для установки этих атрибутов
напрямую, и по умолчанию они возвращают копию.
См. Расширенное индексирование для использования MultiIndexes.
В [314]: ind = pd.Index ([1, 2, 3])
В [315]: ind.rename ("яблоко")
Выход [315]: Int64Index ([1, 2, 3], dtype = 'int64', name = 'apple')
В [316]: ind
Выход [316]: Int64Index ([1, 2, 3], dtype = 'int64')
В [317]: ind.set_names (["яблоко"], inplace = True)
В [318]: ind.name = "bob"
В [319]: ind
Выход [319]: Int64Index ([1, 2, 3], dtype = 'int64', name = 'bob')
set_names , set_levels и set_codes также принимают необязательный уровень аргумент
В [320]: index = pd.MultiIndex.from_product ([диапазон (3), ['один', 'два']], names = ['первый', 'второй'])
В [321]: индекс
Из [321]:
Мультииндекс ([(0, 'один'),
(0, 'два'),
(1, 'один'),
(1, 'два'),
(2, 'один'),
(2, 'два')],
names = ['первый', 'второй'])
В [322]: index.levels [1]
Out [322]: Index (['one', 'two'], dtype = 'object', name = 'second').
В [323]: index.set_levels (["a", "b"], level = 1)
Из [323]:
Мультииндекс ([(0, 'a'),
(0, 'b'),
(1, 'а'),
(1, 'b'),
(2, 'а'),
(2, 'b')],
names = ['первый', 'второй'])
Задать операции над индексными объектами
Двумя основными операциями являются объединение и пересечение .Разница предоставляется с помощью метода .difference () .
В [324]: a = pd.Index (['c', 'b', 'a']) В [325]: b = pd.Index (['c', 'e', 'd']) В [326]: а. Разница (б) Выход [326]: Индекс (['a', 'b'], dtype = 'object')
Также доступна операция symric_difference , которая возвращает элементы
которые появляются либо в idx1 , либо в idx2 , но не в обоих. Это
эквивалентно индексу, созданному idx1.difference (idx2) .union (idx2.разница (idx1)) ,
с дубликатами сброшены.
В [327]: idx1 = pd.Index ([1, 2, 3, 4]) В [328]: idx2 = pd.Index ([2, 3, 4, 5]) В [329]: idx1.symmetric_difference (idx2) Out [329]: Int64Index ([1, 5], dtype = 'int64')
Примечание
Индекс, полученный в результате операции над множеством, будет отсортирован в порядке возрастания.
При выполнении Index.union () между индексами с разными типами данных индексы
должен быть приведен к общему типу dtype. Обычно, хотя и не всегда, это объект dtype.В
Исключение составляет объединение целочисленных данных и данных с плавающей запятой. В этом случае
целочисленные значения преобразуются в число с плавающей запятой
В [330]: idx1 = pd.Index ([0, 1, 2]) В [331]: idx2 = pd.Index ([0.5, 1.5]) В [332]: idx1.union (idx2) Выход [332]: Float64Index ([0.0, 0.5, 1.0, 1.5, 2.0], dtype = 'float64')
Отсутствующие значения
Важно
Несмотря на то, что Index может содержать пропущенные значения ( NaN ), этого следует избегать
если вы не хотите неожиданных результатов.Например, некоторые операции
неявно исключить отсутствующие значения.
Index.fillna заполняет пропущенные значения указанным скалярным значением.
В [333]: idx1 = pd.Index ([1, np.nan, 3, 4])
В [334]: idx1
Выход [334]: Float64Index ([1.0, nan, 3.0, 4.0], dtype = 'float64')
В [335]: idx1.fillna (2)
Выход [335]: Float64Index ([1.0, 2.0, 3.0, 4.0], dtype = 'float64')
В [336]: idx2 = pd.DatetimeIndex ([pd.Timestamp ('2011-01-01'),
.....: pd.NaT,
.....: pd.Отметка времени ('2011-01-03')])
.....:
В [337]: idx2
Out [337]: DatetimeIndex (['2011-01-01', 'NaT', '2011-01-03'], dtype = 'datetime64 [ns]', freq = None)
В [338]: idx2.fillna (pd.Timestamp ('2011-01-02'))
Выход [338]: DatetimeIndex (['2011-01-01', '2011-01-02', '2011-01-03'], dtype = 'datetime64 [ns]', freq = None)
Установить / сбросить индекс
Иногда вы загружаете или создаете набор данных в DataFrame и хотите добавить индекс после того, как вы это уже сделали. Есть пара разных способами.
Установить индекс
DataFrame имеет метод set_index () , который принимает имя столбца
(для обычного Index ) или списка имен столбцов (для MultiIndex ).
Чтобы создать новый переиндексированный фрейм данных:
В [339]: данные
Из [339]:
а б в г
0 бар один z 1,0
1 бар два и 2,0
2 фу один x 3,0
3 фу два ш 4.0
В [340]: indexed1 = data.set_index ('c')
В [341]: indexed1
Из [341]:
а б г
c
z bar один 1.0
у бар два 2,0
х фу один 3.0
w foo two 4.0
В [342]: indexed2 = data.set_index (['a', 'b'])
В [343]: indexed2
Из [343]:
CD
а б
один бар z 1.0
два года 2,0
foo one x 3.0
два w 4.0
Параметр добавить ключевое слово позволяет сохранить существующий индекс и добавить
данные столбцы в MultiIndex:
В [344]: frame = data.set_index ('c', drop = False)
В [345]: frame = frame.set_index (['a', 'b'], append = True)
В [346]: кадр
Из [346]:
CD
такси
z bar one z 1.0
у бар два у 2,0
х фу один х 3,0
w foo two w 4.0
Другие параметры в set_index позволяют не отбрасывать столбцы индекса или добавлять
индекс на месте (без создания нового объекта):
В [347]: data.set_index ('c', drop = False)
Из [347]:
а б в г
c
z bar one z 1.0
у бар два у 2,0
х фу один х 3,0
w foo two w 4.0
В [348]: data.set_index (['a', 'b'], inplace = True)
В [349]: данные
Из [349]:
CD
а б
bar one z 1.0
два года 2,0
foo one x 3.0
два w 4.0
Сбросить индекс
Для удобства в DataFrame есть новая функция, которая называется reset_index () , который передает значения индекса в
Столбцы DataFrame и задает простой целочисленный индекс.
Это операция, обратная set_index () .
В [350]: данные
Из [350]:
CD
а б
один бар z 1.0
два года 2,0
foo one x 3.0
два w 4.0
В [351]: data.reset_index ()
Из [351]:
а б в г
0 бар один z 1.0
1 бар два и 2,0
2 фу один x 3,0
3 фу два ш 4.0
Вывод больше похож на таблицу SQL или массив записей. Имена для
столбцы, полученные из индекса, хранятся в атрибуте names .
Вы можете использовать ключевое слово level , чтобы удалить только часть индекса:
В [352]: рамка
Из [352]:
CD
такси
z bar one z 1.0
у бар два у 2,0
х фу один х 3,0
w foo two w 4.0
В [353]: кадр.reset_index (уровень = 1)
Из [353]:
а в г
в б
z одна полоса z 1,0
y два бара y 2,0
х один фу х 3,0
ш два фу ш 4.0
reset_index принимает необязательный параметр drop , который в случае истины просто
отбрасывает индекс вместо того, чтобы помещать значения индекса в столбцы DataFrame.
Добавление специального индекса
Если вы создаете индекс самостоятельно, вы можете просто назначить его полю index :
Возврат вида по сравнению с копией
При установке значений в объекте pandas необходимо соблюдать осторожность, чтобы избежать того, что называется цепная индексация .Вот пример.
В [354]: dfmi = pd.DataFrame ([список ('abcd'),
.....: list ('efgh'),
.....: список ('ijkl'),
.....: list ('mnop')],
.....: columns = pd.MultiIndex.from_product ([[['один', 'два'],
.....: ['первая секунда']]))
.....:
В [355]: dfmi
Из [355]:
один два
первая секунда первая секунда
0 а б в г
1 e f g h
2 я дж к л
3 мес.
Сравните эти два метода доступа:
В [356]: dfmi ['один'] ['второй'] Из [356]: 0 б 1 ж 2 Дж 3 п Имя: второй, dtype: объект
В [357]: dfmi.loc [:, ('один', 'второй')]
Из [357]:
0 б
1 ж
2 Дж
3 п
Имя: (один, второй), dtype: object
Они оба дают одинаковые результаты, так что вы должны использовать? Поучительно разобраться в порядке
операций над ними и почему метод 2 ( .loc ) намного предпочтительнее, чем метод 1 (связанный [] ).
dfmi ['one'] выбирает первый уровень столбцов и возвращает DataFrame с однократной индексацией.
Затем другая операция Python dfmi_with_one ['second'] выбирает серию, проиндексированную 'second' .На это указывает переменная dfmi_with_one , потому что pandas видит эти операции как отдельные события.
например отдельные вызовы __getitem__ , поэтому он должен рассматривать их как линейные операции, они происходят один за другим.
Сравните это с df.loc [:, ('one', 'second')] , который передает вложенный кортеж (slice (None), ('one', 'second')) в один вызов к __getitem__ . Это позволяет пандам справляться с этим как с единым целым. Кроме того, этот порядок операций может быть значительно
быстрее и позволяет при желании индексировать обе оси .
Почему не удается присвоение при использовании цепной индексации?
Проблема в предыдущем разделе связана только с производительностью. Что случилось с
предупреждение SettingWithCopy ? Мы не используем , как правило, предупреждаем, когда
вы делаете что-то, что может стоить несколько дополнительных миллисекунд!
Но оказывается, что присвоение продукту цепной индексации по своей сути непредсказуемые результаты. Чтобы убедиться в этом, подумайте о том, как Python интерпретатор выполняет этот код:
dfmi.loc [:, ('один', 'второй')] = значение
# становится
dfmi.loc .__ setitem __ ((фрагмент (Нет), ('один', 'второй')), значение)
Но этот код обрабатывается иначе:
dfmi ['one'] ['second'] = значение
# становится
dfmi .__ getitem __ ('один') .__ setitem __ ('второй', значение)
Видите там __getitem__ ? Вне простых случаев очень сложно
предсказать, вернет ли он представление или копию (это зависит от макета памяти
массива, относительно которого pandas не дает никаких гарантий), и, следовательно, __setitem__ изменит dfmi или временный объект, который будет брошен
сразу после этого. Это то, что SettingWithCopy предупреждает вас
о!
Примечание
Вы можете спросить, стоит ли нам беспокоиться о loc недвижимость в первом примере. Но dfmi.loc гарантированно будет dfmi сам с измененным поведением индексации, поэтому dfmi.loc .__ getitem__ / dfmi.loc .__ setitem__ работает напрямую с dfmi . Конечно, dfmi.loc .__ getitem __ (idx) может быть представлением или копией dfmi .
Иногда предупреждение SettingWithCopy появляется в тех случаях, когда нет
происходит очевидное цепное индексирование. Эти - ошибки, которые SettingWithCopy создан для ловли! панды, вероятно, пытается вас предупредить
что вы сделали это:
def do_something (df):
foo = df [['bar', 'baz']] # Является ли foo представлением? Копия? Никто не знает!
# ... здесь много строк ...
# Мы не знаем, изменит ли это df или нет!
foo ['quux'] = значение
return foo
Ура!
Порядок оценки имеет значение
При использовании цепной индексации порядок и тип операции индексации частично определить, является ли результат срезом исходного объекта, или копия среза.
pandas имеет SettingWithCopyWarning , потому что присвоение копии
срез часто не является преднамеренным, а является ошибкой, вызванной цепным индексированием
возврат копии там, где ожидался фрагмент.
Если вы хотите, чтобы панды более или менее доверяли назначению
связанное выражение индексации, вы можете установить опцию mode.chained_assignment на одно из этих значений:
'warn', значение по умолчанию, означает, что напечатаноSettingWithCopyWarning.'поднять'означает, что панды поднимутSettingWithCopyExceptionвы должны иметь дело с.Нет.полностью подавит предупреждения.
В [358]: dfb = pd.DataFrame ({'a': ['one', 'one', 'two',
.....: «три», «два», «один», «шесть»],
.....: 'c': np.arange (7)})
.....:
# Это покажет SettingWithCopyWarning
# но значения кадра будут установлены
В [359]: dfb ['c'] [dfb ['a'].str.startswith ('o')] = 42
Это, однако, работает с копией и не будет работать.
>>> pd.set_option ('mode.chained_assignment', 'предупреждать')
>>> dfb [dfb ['a']. str.startswith ('o')] ['c'] = 42
Отслеживание (последний вызов последний)
...
SettingWithCopyWarning:
Значение пытается быть установлено на копии фрагмента из DataFrame.
Попробуйте вместо этого использовать .loc [row_index, col_indexer] = value
Цепное назначение также может возникать в настройке в кадре смешанного типа dtype.
Примечание
Эти правила настройки применяются ко всем .loc / .iloc .
Ниже приводится рекомендуемый метод доступа с использованием .loc для нескольких элементов (с использованием маски ) и одного элемента с использованием фиксированного индекса:
В [360]: dfc = pd.DataFrame ({'a': ['one', 'one', 'two',
.....: «три», «два», «один», «шесть»],
.....: 'c': np.arange (7)})
.....:
В [361]: dfd = dfc.copy ()
# Установка нескольких элементов с помощью маски
В [362]: маска = dfd ['a'].str.startswith ('о')
В [363]: dfd.loc [маска, 'c'] = 42
В [364]: dfd
Из [364]:
а с
0 один 42
1 один 42
2 два 2
3 три 3
4 два 4
5 один 42
6 шесть 6
# Установка одного элемента
В [365]: dfd = dfc.copy ()
В [366]: dfd.loc [2, 'a'] = 11
В [367]: dfd
Из [367]:
а с
0 один 0
1 один 1
2 11 2
3 три 3
4 два 4
5 один 5
6 шесть 6
Следующий может работать время от времени, но это не гарантируется, и поэтому его следует избегать:
В [368]: dfd = dfc.копия ()
В [369]: dfd ['a'] [2] = 111
В [370]: dfd
Из [370]:
а с
0 один 0
1 один 1
2 111 2
3 три 3
4 два 4
5 один 5
6 шесть 6
Наконец, следующий пример не будет работать вообще , поэтому его следует избегать:
>>> pd.set_option ('mode.chained_assignment', 'поднять')
>>> dfd.loc [0] ['a'] = 1111
Отслеживание (последний вызов последний)
...
SettingWithCopyException:
Значение пытается быть установлено на копии фрагмента из DataFrame.Попробуйте вместо этого использовать .loc [row_index, col_indexer] = value
Предупреждение
Предупреждения / исключения связанных назначений нацелены на то, чтобы проинформировать пользователя о возможном недопустимом назначение. Возможны ложные срабатывания; ситуации, когда связанное назначение непреднамеренно сообщил.
ИНДЕКС Функция | Smartsheet Learning Center
Возвращает элемент из коллекции на основе предоставленных индексов строк и столбцов.
Примеры
Этот пример ссылается на следующую информацию таблицы:
| Пункт одежды | Всего транзакций | Продано квартир | Цена за единицу | В наличии? | |
|---|---|---|---|---|---|
| 1 | Футболка | 1,170.00 | 78 | 15,00 | правда |
| 2 | Брюки | 1 491,00 | 42 | 35,50 | ложный |
| 3 | Куртка | 812,00 | 217 | 200,00 | правда |
В приведенной выше таблице приведены несколько примеров использования INDEX на листе:
Формула | Описание | Результат |
|---|---|---|
= ИНДЕКС ([Предмет одежды]: [Продано единиц], 1, 3) | Возвращает значение в столбце «Продано единиц» для строки 1. | 78 |
= ИНДЕКС (СБОР ([Сумма транзакции]: [Сумма транзакции], [В наличии?]: [В наличии?], Истина), 1) | Собирает значения в столбце «Сумма транзакции» для строк, где установлен флажок в поле «В наличии?» столбец проверяется (истина) и возвращает первую запись в этой коллекции. | 1 170,00 долл. США |
= ИНДЕКС ([Цена за единицу]: [Цена за единицу], МАТЧ («Куртка», [Предмет одежды]: [Предмет одежды], 0)) | Возвращает значение в столбце «Цена за единицу» для строки, которая содержит значение «Куртка» в столбце «Предмет одежды». | $ 200 |
= ИНДЕКС ([В наличии]: [В наличии], МАТЧ («Куртка», [Предмет одежды]: [Предмет одежды], 0)) | Возвращает значение в столбце «В наличии» для строки, содержащей значение «Куртка» в столбце «Предмет одежды». | правда |
Техническое письмо в Интернете: индексирование
Как технический писатель, вам, как правило, придется создавать указатели для печатных книг и для онлайн-помощников в разработке.Под типом указателя, который мы здесь имеем в виду, является классический указатель на обратной стороне книги, который показывает номера страниц, на которых темы и подтемы встречаются в книге. Онлайн-указатель во многом аналогичен, за исключением того, что вы предоставляете гипертекстовые ссылки, а не номера страниц.
Индекс в печатном документе
Указатель в онлайн-справочной системе (левая панель)
Как и в любом письменном проекте, для индексации есть черновой этап.И, конечно же, вам нужно подумать о своей аудитории - кто они, как они будут использовать индекс, почему они будут его использовать и к какой терминологии они могут привыкнуть. После этого вот что делать дальше:
- Преобразование каждого заголовка в несколько записей указателя. Заголовки - хорошее место для начала: они указывают темы и подтемы - именно то, что делает индекс. Однако не стоит просто копировать заголовки прямо в указатель и уходить. Как вы увидите ниже, вам необходимо составить перекрестный список заголовков в максимально возможном количестве способов.
- Перечислите каждую запись. Переупорядочивайте каждую запись на основе заголовка как можно большим количеством практических способов. Например, такой заголовок, как «Изменение разрешения экрана», можно проиндексировать как «разрешение экрана, изменение», а также «изменение разрешения экрана». Вы также можете включить «разрешение, изменение экрана». Эти перекрестные записи пытаются предугадать все возможные способы, которыми читатель может искать эту тему в указателе: «экран», «разрешение» или «изменение».
Вот еще несколько примеров:
Товарная позиция Индексные позиции Оптимизация отображения видео видеодисплей, оптимизация
оптимизация отображения видео
дисплей, оптимизация видеоВоспроизведение потокового мультимедиа потоковое мультимедиа, воспроизведение
воспроизведение потокового мультимедиа
мультимедиа, потоковое воспроизведениеОсновы работы в сети сеть
сетиПредставляем потоковое мультимедиа потоковое мультимедиа
мультимедиа, потоковое
Обратите внимание на то, что вы не всегда можете перекрестно перечислять элементы указателя по каждому слову.Например, предыдущая фраза «представление потокового мультимедиа» просто не сработает. Будет ли кто-нибудь из читателей искать эту тему, начиная со слова «введение»? - Создайте синонимы. Читатели не обязательно используют ту же терминологию, что и вы в своей документации. Они могут называть дисковод гибких дисков «дисководом для гибких дисков». Они могут называть дисплей «монитором». Как индексатор, вы должны предвидеть эти общие вариации терминологии. В предыдущих записях было бы неплохо иметь синоним для «видеодисплея», например «монитор».«Но вместо того, чтобы повторять номера страниц, используйте ссылку See . Таким образом, вы укажете читателям на предпочтительный термин. (Конечно, если есть только один номер страницы, просто повторите его с синонимом).
Вот еще несколько примеров:
Запись индекса Синонимы громкость регулировочная громкость, регулировочная скорость передачи скорость, коробка передач захват видео копирование видео - Просмотрите текст на предмет дополнительных записей указателя.Обычно недостаточно просто индексировать по заголовкам. Вы должны покопаться в тексте в поисках концепций, терминов и задач, которые не представлены в заголовках. Например, под заголовком «Создание мультимедийного потока» вы можете увидеть определения «захват» и «кодирование». Это важные термины, но они нигде не появляются в заголовках - тоже их проиндексируйте! В этом случае вам нужно создать эти дополнительные записи индекса: «захватывающие потоки» и «кодирующие потоки».
- Указатель лицевой и оборотной сторон.Не забудьте покопаться в предисловии, примечаниях по технике безопасности, приложениях и других подобных периферийных устройствах, чтобы найти дополнительные записи в указателе. Обычно в предисловии указаны номера и адреса техподдержки. Индексируйте их - и не забудьте также создать для них записи из перекрестного списка и записи-синонимы.
Запись индекса Клонированные и сининомные записи техническая поддержка поддержка, техническая
справочная служба
проблемы
После мозгового штурма всех записей индекса, которые вы только можете придумать, пора посмотреть, как выглядит индекс, и начать работу над ним.Чтобы пересмотреть предварительный указатель:
- Создайте первый проект указателя. После того, как вы создали как можно больше записей указателя, перекрестных списков и синонимов, пора «построить» первый черновик указателя. Если вы не работаете по старинке с учетными карточками, вы можете настроить приложение, которое сделает это за вас. Например, если вы работаете в настольной издательской системе, вы прошли через свой текст, вставляя элементы указателя. Тот же процесс применяется к инструментам создания справки.Не расстраивайтесь, когда вы создаете первый черновик указателя. Это всего лишь черновик, к которому вам нужно будет внести несколько исправлений.
- Выбросьте бесполезные записи. На предыдущих этапах вы набросали указатель. На этом этапе вы не зацикливаетесь на точной формулировке записей или вероятности того, что кто-нибудь когда-либо их использует. Но сейчас самое время начать отсеивать записи, которые ни один читатель никогда бы не использовал. Например, записи первого уровня, начинающиеся со слов «введение», «использование», «о», вряд ли будут полезны.Удалите их! Но не удаляйте их из построенного индекса. Вернитесь в свой документ и избавьтесь от исходной записи указателя.
- Объединяйте записи с похожей формулировкой. Вы также найдете множество статей с незначительными вариациями во фразе. Например:
Черновые вводы Исправленные записи технология потокового мультимедиа
технологии, потоковое мультимедиатехнологии, потоковое мультимедиа видеодисплей
видео дисплеивидеодисплеев изменить разрешение экрана
изменение разрешения экранаизменение разрешения экрана
Как вы можете видеть в этих примерах, записи в единственном / множественном числе и варианты глаголов являются наиболее частыми причинами сходной формулировки в записях указателя.Ваш домашний стиль может диктовать использование единственного, а не множественного числа. Каким бы способом вы ни справились, просто будьте последовательны. - Сгруппировать похожие записи. Вы также увидите записи, которые необходимо сгруппировать и расположить в подчинении. Например, все они могут начинаться с одного и того же слова, но иметь разные модификаторы. Вот пример:
Подобные записи Сгруппированные и подчиненные записи проектор определенный
проекторы, комплектующие
проекторы, соображения
проекторы, создающие
проекторы, устранение неисправностейпроекторы компиляция
соображения
создание
определено
устранение неисправностей
- Исправить записи с избыточным количеством страниц.В некоторых организациях есть действующие правила стиля, касающиеся допустимого количества ссылок на страницы после записи в указателе. Три - общий максимум; двое - агрессивный, амбициозный. Например, «синтаксис программирования, 12, 45, 74, 122, 219, 222». Подобная цепочка анонимных ссылок на страницы никому не помогает. Вместо этого определите подтему для этих ссылок на страницы. Вот пример:
Слишком много неопознанных ссылок на страницы Подчиненные и помеченные записи проекторы, 124, 136, 154-155, 156 157 проекторы сборник, 154-155
соображения, 156
управления, 136
определено, 124, 136, 157
Очень хороший штрих, который вы не часто видите в индексах, - это диапазон страниц, на котором обсуждается тема, даже если есть подстатьи.Если бы это было правильно, вы могли бы иметь такую запись: «проекторы, 126–137» - Ищите группы записей. Приятный полезный штрих в индексах - поиск способов группировки записей. Например, представьте себе руководство пользователя, в котором объясняются различные диалоговые окна, всплывающие в приложении. Есть диалоговое окно «Пароль», диалоговое окно «Новый пользователь», диалоговое окно «Удалить пользователя» и т. Д. Как насчет того, чтобы повторить все эти записи в «диалоговых окнах»?
Записи Сгруппированные записи (записи разбросаны по индексу) Диалоговое окно «Добавить пользователя»
...
Диалоговое окно "Удалить пользователя"
...
Диалоговое окно "Новый пользователь"
...
Диалоговое окно пароляДиалоговое окно добавления пользователя
...
Диалоговое окно "Удалить пользователя"
...
диалоговые окнаДобавить пользователя
Удалить пользователя
Новый пользователь
Пароль
...
Диалоговое окно "Новый пользователь"
...
Диалоговое окно пароля - Ищите записи о смене вверх.В процессе индексирования у вас могут быть некоторые подстатьи, которые необходимо скопировать в качестве основных записей.
Записи Сдвинутые вверх записи
(записи разбросаны по всему индексу)батареи утилизация, 33
предупреждение о взрыве, 34
рекомендация производителя, 34
полярность, 33-34
закупочная, 33
замена, 33-34
вкладок, 33 (илл.)
батареи утилизация, 33
предупреждение о взрыве, 34
рекомендация производителя, 34
полярность, 33-34
закупочная, 33
замена, 33-34
вкладок, 33 (илл.)
утилизация, батарейки, 33
...
полярность, батарейки, 33-34
...
предупреждение, батареи, 34
...
В этом примере индексатор думал, что некоторые (вероятно, не многие) читатели сначала будут искать «полярность», а не «батареи, полярность». Точно так же индексатор подумал, что люди могут сначала поискать «утилизация». Несмотря на то, что такие возможности невелики, все равно поместите их в индекс. - Ищите См. Также и дополнительные См. Ссылки .Ближе к концу фазы проверки посмотрите в свой указатель на возможность См. Также ссылок. См. Также ссылки - это близко связанные термины, которые читатели могут выбрать по ошибке. Например, в старых системах DOS были команды copy и xcopy . Эти две команды настолько тесно связаны по названию и функциям, что вы захотите поместить . См. Также ссылки друг на друга. И не забывайте ссылки See : эти ссылки читают от синонимических терминов к терминам, которые вы предпочитаете использовать и индексировать в своей книге.
- Проверьте стиль и механику записей указателя. Организация, в которой вы работаете, может иметь собственное руководство по стилю дома или рекомендовать вам какой-либо стандартный стиль, например, Chicago Manual of Style . Посмотрите на них очень внимательно, чтобы узнать, как они говорят вам использовать заглавные буквы и знаки пунктуации в индексных статьях. Индексы обычно используют строчные буквы для всех записей, не являющихся собственными существительными, но определенный процент действительно использует начальные заглавные буквы для записей первого уровня. В большинстве стилей запятую ставят сразу после индекса и перед номерами страниц; но некоторые этого не делают.Некоторые стили требуют, чтобы в указателе использовалось такое же выделение, как и в основном тексте. Если что-то выделено жирным шрифтом в основном тексте, они также хотят, чтобы это было жирным шрифтом в указателе.
Примечание: В этой главе используются различные стили пунктуации и использования заглавных букв - не для того, чтобы запутать вас, а для того, чтобы вы знали о стилистической вариативности.
Один общий стиль индекса Другой распространенный стиль указателя проекторы, 123 компиляция, 154-155
соображения, 156
управления, 136
определено, 124, 136, 157
профилей проектов, 451-461
проекторы сборник 154-155
соображения 156
органы управления 136
определено 124, 136, 157
Профили проектов 451-461
Обратите внимание на то, что в примере справа нет запятой между термином индекса и ссылками на страницы.Кроме того, вы обнаружите, что некоторые стандарты и стили индексирования не одобряют наличие ссылки на страницу в записи указателя, которая имеет подстатьи: например, «проекторы, 123» в левом примере. Почему ссылка на страницу 123 не находится среди подстатьей? Каков подтема на странице 123?
Буду признателен за ваши мысли, реакцию, критику по поводу этой главы: ваш ответ.